Ve věku velkých dat, úkolem již není získat dostatek údajů; úkolem je zjistit správné údaje použít. V minulém článku jsem se zaměřil na hodnotu alternativních dat, která jsou životně důležitým obchodním aktivem. I s výhodami alternativních dat však může nesprávná zrnitost dat podkopat návratnost investic správy založené na datech.
„jsme tak posedlí daty, zapomínáme, jak je interpretovat“. – Danah Boyd, hlavní výzkumná pracovnice společnosti Microsoft Research
jak pečlivě byste se tedy měli dívat na svá data? Protože nesprávná zrnitost dat vás může stát víc, než si uvědomujete.
jednoduše řečeno, granularita dat se týká úrovně podrobností našich dat. Čím podrobnější jsou vaše data, tím více informací obsažených v konkrétním datovém bodě. Měření roční transakcí v rámci všech obchodů v zemi by mít nízkou zrnitost, jako byste vědět velmi málo o tom, kdy a kde zákazníky, aby tyto nákupy. Na druhou stranu by měření transakcí jednotlivých obchodů mělo neuvěřitelně vysokou granularitu.
ideální zrnitost dat závisí na druhu analýzy, kterou provádíte. Pokud hledáte vzorce chování spotřebitelů po celá desetiletí, nízká granularita je pravděpodobně v pořádku. K automatizaci doplňování úložiště však budete potřebovat mnohem podrobnější data.
Když si vyberete špatně zrnitosti pro analýzu, můžete skončit s méně přesné a méně užitečné informace. Přemýšlejte o tom, jak chaotický týdenní úložiště doplňování pouze na základě ročních dat systemwide by bylo! Neustále byste zažívali nadměrné zásoby i zásoby, hromadění obrovských nákladů a vysoké úrovně odpadu v procesu. V jakékoli analýze může mít nesprávná zrnitost dat podobně závažné důsledky pro vaši efektivitu a spodní řádek.
takže používáte správnou zrnitost dat pro vaši business intelligence? Zde je pět běžných — a nákladných-chyb zrnitosti dat.
seskupení více obchodních trendů do jednoho vzoru (pokud data nejsou dostatečně Zrnitá).
Business intelligence musí být jasný a jednoduchý, aby bylo žalovatelné, ale někdy, ve snaze o dosažení jednoduchosti, lidé nemají ponořit dostatečně hluboko do data. To je škoda, protože vám budou chybět cenné postřehy. Když je zrnitost dat příliš nízká, vidíte pouze velké vzory, které vznikají na povrchu. Může vám chybět kritická data.
v příliš mnoha případech vede nedostatečný pohled na vaše data ke kompresi nesourodých trendů do jediného výsledku. Podniky, které dělají tuto chybu, skončí s nerovnými výsledky. Je pravděpodobnější, že budou mít nepředvídatelné a extrémní odlehlé hodnoty — které neodpovídají celkovému vzoru – protože tento vzorec neodráží realitu.
to je běžný problém v mnoha tradičních předpovědních systémech dodavatelského řetězce. Nemůžou zvládnout na úrovni podrobnosti nutné předvídat SKU-úroveň poptávky v jednotlivých prodejen, což znamená, že jeden obchod může být jednání s oběma overstocks a stockouts ve stejnou dobu. Automatizované systémy poháněné AI může zvládnout složitost nutné, aby správně segmentu dat, což je jeden z důvodů těchto zlepšení efektivity dodavatelského řetězce. Dostatečná zrnitost dat je rozhodující pro přesnější business intelligence.

se ztratil v datech bez bodu zaostření (když dat je příliš zrnitý).
už jste někdy náhodou přiblížili příliš daleko do mapy online? Je to tak frustrující! Nemůžete rozeznat žádné užitečné informace, protože neexistuje žádný kontext. To se děje i v datech.
pokud jsou vaše data příliš Zrnitá, ztratíte se; nemůžete se dostatečně soustředit, abyste našli užitečný vzor ve všech cizích datech. Je to lákavé, aby pocit, že více detailů je vždy lepší, když jde o data, ale příliš mnoho detailů může vaše data prakticky k ničemu. Mnoho vedoucích pracovníků, kteří čelí tolika datům, se ocitnou zmrazeni paralýzou analýzy. Skončíte s nespolehlivými doporučeními, nedostatkem obchodního kontextu a zbytečným zmatkem.
Příliš zrnitý dat je velmi nákladné chybu, když přijde na AI prognózování. Data mohou trik algoritmu do naznačuje, že to má dost údajů, aby se předpoklady o budoucnosti, kterou není možné, s dnešní technologií. Například v mém dodavatelském řetězci v Evo je stále nemožné předpovědět denní tržby za SKU. Vaše chyba bude příliš velká na to, aby byla užitečná. Tato úroveň zrnitosti podkopává cíle a snižuje návratnost investic.
záměrně nevybereme zrnitost časových proměnných.
nejčastější chyby zrnitosti dat se týkají časových intervalů, tj. měření proměnných v hodinovém, denním, týdenním, ročním atd. základ. Časové chyby zrnitosti se často vyskytují kvůli pohodlí. Většina společností má standardní způsoby hlášení časovaných proměnných. Zdá se, že by to vyžadovalo příliš mnoho úsilí na jejich změnu, takže ne. ale to je zřídka ideální granularita k řešení analyzovaného problému.
Když si vážit náklady mění způsob, jakým váš systém zpráv, Kpi versus náklady na důsledně získávání nedostatečné business intelligence, výhody cíleně výběr správné zrnitosti se zaregistrovat. V závislosti na zrnitosti času poznáte velmi odlišné poznatky ze stejných dat. Vezměte si například sezónní trendy v maloobchodě. Při pohledu na transakce přes jeden den mohli udělat sezónní trendy neviditelné, nebo přinejmenším obsahovat tolik údajů, že vzory jsou jen bílý šum, zatímco měsíční data akcie odlišné sekvence můžete skutečně použít. Pokud standardní Kpi přeskočit měsíční reporting jít rovnou na čtvrtletní vzory, ztratíte cenné poznatky, že by se předpovědi přesnější. Pokud chcete získat nejlepší inteligenci, nemůžete mít čas na granularitu v nominální hodnotě.


Overfitting nebo underfitting model do bodu, že vzory, které vidíte, jsou nesmyslné.
modely AI se musí dobře zobecnit ze stávajících i budoucích dat, aby poskytly užitečná doporučení. V podstatě dobrý model se mohli podívat na tato data:

A předpokládám, že to jako pracovní model na základě informací:

vzor nemusí dokonale reprezentují data, ale to dělá dobrou práci předpovídají typické chování bez obětování příliš mnoho inteligence.
Pokud však nemáte správnou zrnitost dat, můžete skončit se špatným modelem. Jak jsme mluvili dříve, příliš podrobná data mohou způsobit šum, který ztěžuje nalezení vzoru. Pokud váš algoritmus důsledně trénuje s touto hlučnou úrovní detailů, bude zase poskytovat šum. Můžete skončit s modelem, který vypadá jako tento:

říkáme tomu overfitting váš model. Každý datový bod má nadměrný dopad, do té míry, že model již nemůže užitečně zobecnit. Problémy zpočátku způsobené vysokou zrnitostí jsou zvětšeny a v modelu jsou trvalým problémem.
příliš nízká zrnitost dat může také způsobit dlouhodobé poškození vašeho modelu. Algoritmus musí mít dostatek dat k nalezení vzorů. Algoritmy vyškolené pomocí dat bez dostatečné zrnitosti budou chybět kritické vzorce. Jakmile se algoritmus posune za tréninkovou fázi, bude i nadále selhávat v identifikaci podobných vzorců. Skončíte s modelem, který vypadá takto:
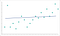
To je underfitting modelu. Algoritmus se blíží k vytváření správných předpovědí, přesto nikdy nebudou tak přesné,jak by mohly být. Stejně jako nadměrné vybavení je to zvětšení počátečního problému zrnitosti.
když vytváříte model pro vaši analýzu, správná granularita se stává exponenciálně důležitější než jednou, když máte stabilní algoritmus. Z tohoto důvodu se mnoho společností rozhodlo tuto část procesu outsourcovat odborníkům. Je to příliš choulostivá a nákladná etapa na chyby.
nastavení zrnitosti nesprávných údajů zcela.
Možná nejnákladnější údaje zrnitost chybu, jen se tolik zaměřuje na optimalizaci zrnitost Kpi v současné době opatření, které si nedokážou uvědomit, že jsou špatné Kpi úplně. Naším cílem je dosáhnout správné údaje zrnitost ne pro optimalizaci žádné konkrétní KPI výkon, ale spíše rozpoznat vzory v datech, které poskytují žalovatelné a cenné postřehy. Pokud chcete například zlepšit příjmy, můžete podkopávat svůj úspěch pouze tím, že se podíváte na vzorce v cenách. Jsou zapojeny další faktory.
Vezměte si příklad od mého kolegy. Nový klient Evo chtěl zvýšit prodej a počáteční test s použitím našich nástrojů dodavatelského řetězce ukázal 10% zlepšení za méně než dva týdny. Náš generální ředitel byl těmito bezprecedentními výsledky nadšen, ale k jeho překvapení nebyl manažer dodavatelského řetězce ohromen. Jeho primárním KPI byla dostupnost produktů, a podle interních čísel, To se nikdy nezměnilo. Jeho zaměření na zlepšení konkrétního KPI přišlo za cenu rozpoznání cenných poznatků z jiných dat.


Zda nebo ne, že KPI byl přesně měří, se zaměřením výhradně na měnící se jeho výkon konat tento manažer viděl hodnotu nového přístupu. Byl to chytrý muž jednající v dobré víře, ale data ho uvedla v omyl — neuvěřitelně běžná, ale drahá chyba. Správná granularita dat je zásadní, ale nemůže to být cíl sám o sobě. Musíte se podívat na větší obrázek, abyste maximalizovali své výnosy z AI. Na tom, jak pozorně se díváte na svá data, nezáleží, pokud na prvním místě nemáte správná data.
„častým klamem správy založené na datech je použití nesprávných dat k zodpovězení správné otázky“. – Fabrizio Fantini, zakladatel a generální ředitel společnosti Evo
výhody správné zrnitosti dat
pokud jde o zrnitost dat, neexistuje žádná magická kulka. Musíte si je vybrat pečlivě a úmyslně, abyste se vyhnuli těmto a dalším méně častým chybám. Jediným způsobem, jak maximalizovat výnosy z vašich dat, je podívat se na to kriticky-obvykle s pomocí odborníka na data. Pravděpodobně nebudete mít granularitu hned při prvním pokusu, takže je třeba testovat a upravovat, dokud nebude perfektní.
stojí to za námahu. Při bližším pohledu, ale ne příliš pozorně, vaše data zajišťují optimální business intelligence. Segmentovaná a správně analyzovaná data se transformují do konkurenční výhody, na kterou se můžete spolehnout.