možná Jste byli pomocí Strom modely pro dlouhou dobu, nebo nováček, ale už jste někdy zajímalo, jak vlastně funguje a jak se liší od jiných algoritmů? Tady, sdílím stručný přehled mých porozumění.
CART je také prediktivní model, který pomáhá najít proměnnou založenou na jiných značených proměnných. Aby bylo jasněji, stromové modely předpovídají výsledek položením sady otázek if-else. Při používání stromových modelů existují dvě hlavní výhody,
- jsou schopni zachytit nelinearitu v datovém souboru.
- není třeba standardizovat data při použití stromových modelů. Protože nepočítají žádnou euklidovskou vzdálenost ani jiné měřící faktory mezi daty. Jen kdyby-jinak.
Matice a Šrouby Stromů

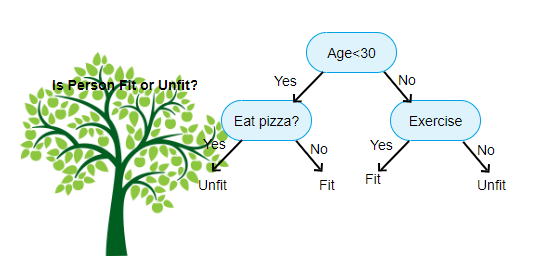
Výše uvedené je obraz Klasifikátor Rozhodovací Strom, každé kolo je známý jako Uzly. Každý uzel bude mít klauzuli if-else založenou na označené proměnné. Na základě této otázky bude každá instance vstupu směrována/směrována na konkrétní uzel listu, který řekne konečnou předpověď. Existují tři typy uzlů,
- Kořenový Uzel: nemá žádný nadřazený uzel, a dává dvě děti uzly založené na otázku,
- Vnitřní Uzel: to bude mít rodič uzlu, a dává dvě děti uzly
- Leaf Node: to bude mít také nadřazeného uzlu, ale nebude mít žádné děti uzly
počet úrovní jsme je známý jako max_depth. Ve výše uvedeném diagramu max_depth = 3. Jak se max_depth zvyšuje, složitost modelu se také zvýší. Zatímco trénujeme, pokud ji zvýšíme, chyba tréninku bude vždy klesat nebo zůstane stejná. Někdy však může zvýšit chybu testování. Takže musíme být vybíraví při výběru max_depth pro model.
dalším zajímavým faktorem o uzlu je informační zisk (IR). Toto je kritérium používané k měření čistoty uzlu. Čistota se měří na základě toho, jak chytrý uzel může rozdělit položky. Řekněme, že jste v uzlu a chcete jít doleva nebo doprava. Ale máte položky patří do obou tříd ve stejné výši (50-50) v každém uzlu. Pak je čistota obou tříd nízká, protože nevíte, kterým směrem zvolit. Jeden musí být vyšší než druhý, aby se mohl rozhodnout. to se měří pomocí IR,
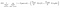

jak již název napovídá, cílem CART je předpovědět, do které třídy vstupní instance patří na základě označených hodnot. K dosažení tohoto cíle bude rozhodovat regiony pomocí rozhodovacích hranic. Představte si, že máme 2D datové sady,

jako je tento, bude samostatný naše multidimenzionální datové sady do Rozhodnutí Regionů na základě if-else otázky v každém uzlu. Modely košíku mohou najít přesnější rozhodovací oblasti než lineární modely. A rozhodovací oblasti podle košíku mají obvykle obdélníkový tvar, protože v každém uzlu je při rozhodování zapojen pouze jeden prvek. Můžete si to představit pod,

myslím, že to je dost úvodů, pojďme se podívat na nějaké příklady, jak vybudovat VOZÍK modely na Scikit learn.
Klasifikace Strom
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regresní Strom
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Doufám, že tento článek je užitečné, pokud máte nějaké diskuse nebo návrhy, prosím, zanechte soukromou poznámku.