Im Zeitalter von Big Data besteht die Herausforderung nicht mehr darin, auf genügend Daten zuzugreifen. In einem früheren Artikel habe ich mich auf den Wert alternativer Daten konzentriert, die ein wichtiges Geschäftsgut sind. Selbst mit den Vorteilen alternativer Daten kann jedoch die falsche Datengranularität den ROI des datengesteuerten Managements untergraben.
“ Wir sind so besessen von Daten, dass wir vergessen, sie zu interpretieren“. – Danah Boyd, Principal Researcher bei Microsoft Research
Wie genau sollten Sie sich Ihre Daten ansehen? Weil die falsche Datengranularität Sie mehr kosten könnte, als Sie denken.
Einfach ausgedrückt, bezieht sich die Datengranularität auf den Detaillierungsgrad unserer Daten. Je detaillierter Ihre Daten sind, desto mehr Informationen sind in einem bestimmten Datenpunkt enthalten. Die Messung jährlicher Transaktionen in allen Geschäften eines Landes hätte eine geringe Granularität, da Sie sehr wenig darüber wissen würden, wann und wo Kunden diese Einkäufe tätigen. Die sekundengenaue Messung der Transaktionen einzelner Geschäfte hätte dagegen eine unglaublich hohe Granularität.
Die ideale Datengranularität hängt von der Art der Analyse ab, die Sie durchführen. Wenn Sie nach Mustern im Verbraucherverhalten über Jahrzehnte hinweg suchen, ist eine geringe Granularität wahrscheinlich in Ordnung. Um den Nachschub in den Geschäften zu automatisieren, benötigen Sie jedoch viel detailliertere Daten.
Wenn Sie die falsche Granularität für Ihre Analyse wählen, erhalten Sie weniger genaue und weniger nützliche Informationen. Denken Sie darüber nach, wie chaotisch die wöchentliche Auffüllung des Geschäfts wäre, die nur auf jährlichen systemweiten Daten basiert! Sie würden ständig sowohl Überbestände als auch Lagerbestände erleben, was zu enormen Kosten und hohem Abfall führt. In jeder Analyse kann die falsche Datengranularität ähnlich schwerwiegende Folgen für Ihre Effizienz und Ihr Endergebnis haben.
Verwenden Sie also die richtige Datengranularität für Ihre Business Intelligence? Hier sind fünf häufige — und kostspielige – Datengranularitätsfehler.
Gruppieren mehrerer Geschäftstrends in einem einzigen Muster (wenn die Daten nicht granular genug sind).
Business Intelligence muss klar und unkompliziert sein, um umsetzbar zu sein, aber manchmal tauchen die Leute nicht tief genug in die Daten ein, um Einfachheit zu erreichen. Das ist schade, denn Sie verpassen wertvolle Einblicke. Wenn die Datengranularität zu gering ist, sehen Sie nur große Muster, die an der Oberfläche entstehen. Sie können kritische Daten verpassen.
In viel zu vielen Fällen führt ein nicht genauer Blick auf Ihre Daten dazu, dass unterschiedliche Trends zu einem einzigen Ergebnis komprimiert werden. Unternehmen, die diesen Fehler machen, führen zu ungleichen Ergebnissen. Sie haben eher unvorhersehbare und extreme Ausreißer, die nicht zum Gesamtmuster passen — weil dieses Muster nicht die Realität widerspiegelt.
Dies ist ein häufiges Problem in vielen traditionellen Lieferkettenprognosesystemen. Sie können nicht mit der Granularität umgehen, die erforderlich ist, um die Nachfrage auf SKU-Ebene in einzelnen Geschäften vorherzusagen, was bedeutet, dass ein einzelnes Geschäft möglicherweise gleichzeitig mit Überbeständen und Lagerbeständen zu tun hat. Automatisierte Systeme mit KI können die Komplexität bewältigen, die erforderlich ist, um Daten richtig zu segmentieren, was ein Grund dafür ist, die Effizienz der Lieferkette zu verbessern. Ausreichende Datengranularität ist entscheidend für genauere Business Intelligence.

Sich in den Daten ohne Fokuspunkt zu verlieren (wenn die Daten zu granular sind).
Haben Sie schon einmal versehentlich zu weit in eine Karte gezoomt? Es ist so frustrierend! Sie können keine nützlichen Informationen erkennen, da es keinen Kontext gibt. Das passiert auch in Daten.
Wenn Ihre Daten zu granular sind, gehen Sie verloren; Sie können sich nicht genug konzentrieren, um ein nützliches Muster in allen fremden Daten zu finden. Es ist verlockend zu glauben, dass mehr Details immer besser sind, wenn es um Daten geht, aber zu viele Details können Ihre Daten praktisch unbrauchbar machen. Viele Führungskräfte, die mit so vielen Daten konfrontiert sind, sind durch Analyselähmung eingefroren. Sie enden mit unzuverlässigen Empfehlungen, einem Mangel an Geschäftskontext und unnötiger Verwirrung.
Zu granulare Daten sind ein besonders kostspieliger Fehler, wenn es um KI-Prognosen geht. Die Daten können den Algorithmus dazu verleiten, darauf hinzuweisen, dass er über genügend Daten verfügt, um Annahmen über die Zukunft zu treffen, die mit der heutigen Technologie nicht möglich sind. In meiner Supply-Chain-Arbeit bei Evo zum Beispiel ist es immer noch unmöglich, den täglichen Umsatz pro SKU zu prognostizieren. Ihre Fehlerquote wird zu groß sein, um nützlich zu sein. Diese Granularität untergräbt die Ziele und verringert den ROI.
Die Granularität von Zeitvariablen wird nicht gezielt ausgewählt.
Die häufigsten Datengranularitätsfehler beziehen sich auf Zeitintervalle, d. H. Messvariablen stündlich, täglich, wöchentlich, jährlich usw. Grundlage. Zeitliche Granularitätsfehler treten häufig aus Gründen der Bequemlichkeit auf. Die meisten Unternehmen haben Standardmethoden, um zeitgesteuerte Variablen zu melden. Es fühlt sich an, als würde es zu viel Aufwand erfordern, sie zu ändern, also tun sie es nicht. Dies ist jedoch selten die ideale Granularität, um das analysierte Problem anzugehen.
Wenn Sie die Kosten für die Änderung der Art und Weise, wie Ihr System KPIs meldet, im Vergleich zu den Kosten für die konsistente Beschaffung unzureichender Business Intelligence abwägen, ergeben sich die Vorteile einer gezielten Auswahl der richtigen Granularität. Abhängig von der Granularität der Zeit erkennen Sie sehr unterschiedliche Erkenntnisse aus denselben Daten. Nehmen wir zum Beispiel Saisonalitätstrends im Einzelhandel. Wenn Sie Transaktionen über einen einzigen Tag betrachten, können saisonale Trends unsichtbar werden oder zumindest so viele Daten enthalten, dass Muster nur weißes Rauschen sind, während monatliche Daten eine eindeutige Sequenz aufweisen, die Sie tatsächlich verwenden können. Wenn Standard-KPIs die monatliche Berichterstattung überspringen, um direkt zu vierteljährlichen Mustern überzugehen, verlieren Sie wertvolle Erkenntnisse, die Prognosen genauer machen würden. Sie können Zeitgranularität nicht für bare Münze nehmen, wenn Sie die beste Intelligenz erhalten möchten.


Über- oder Unteranpassung Ihres Modells bis zu dem Punkt, an dem die Muster, die Sie sehen, bedeutungslos sind.
KI-Modelle müssen aus bestehenden und zukünftigen Daten gut verallgemeinert werden, um nützliche Empfehlungen zu liefern. Im Wesentlichen könnte ein gutes Modell diese Daten betrachten:

Und nehmen Sie dies als Arbeitsmodell basierend auf den Informationen an:

Das Muster repräsentiert die Daten möglicherweise nicht perfekt, aber es kann typisches Verhalten gut vorhersagen, ohne zu viel Intelligenz zu opfern.
Wenn Sie jedoch nicht über die richtige Datengranularität verfügen, können Sie das falsche Modell erhalten. Wie bereits erwähnt, können zu granulare Daten Rauschen verursachen, das das Auffinden eines Musters erschwert. Wenn Ihr Algorithmus konsequent mit dieser verrauschten Detailstufe trainiert, liefert er wiederum Rauschen. Sie erhalten ein Modell, das so aussieht:

Wir nennen das Überanpassung Ihres Modells. Jeder Datenpunkt hat eine übergroße Auswirkung, so dass das Modell nicht mehr sinnvoll verallgemeinert werden kann. Die anfänglich durch hohe Granularität verursachten Probleme werden vergrößert und zu einem permanenten Problem im Modell gemacht.
Eine zu geringe Datengranularität kann Ihrem Modell auch langfristig schaden. Ein Algorithmus muss über ausreichende Daten verfügen, um Muster zu finden. Algorithmen, die mit Daten ohne ausreichende Granularität trainiert werden, übersehen kritische Muster. Sobald der Algorithmus über die Trainingsphase hinausgegangen ist, wird er weiterhin keine ähnlichen Muster mehr identifizieren können. Sie erhalten ein Modell, das so aussieht:
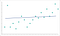
Dies ist underfitting das Modell. Der Algorithmus kommt nahe daran, die richtigen Vorhersagen zu treffen, aber sie werden niemals so genau sein, wie sie hätten sein können. Wie bei der Überanpassung handelt es sich um eine Vergrößerung des anfänglichen Granularitätsproblems.
Wenn Sie ein Modell für Ihre Analyse erstellen, wird die richtige Granularität exponentiell wichtiger als wenn Sie einen stabilen Algorithmus haben. Aus diesem Grund entscheiden sich viele Unternehmen, diesen Teil des Prozesses an Experten auszulagern. Es ist eine zu heikle und kostspielige Phase für Fehler.
Vollständige Anpassung der Granularität der falschen Daten.
Der vielleicht kostspieligste Fehler bei der Datengranularität besteht lediglich darin, sich so sehr auf die Optimierung der Granularität der KPIs zu konzentrieren, die Sie derzeit messen, dass Sie nicht erkennen, dass es sich um die falschen KPIs handelt. Unser Ziel ist es, die richtige Datengranularität zu erreichen, nicht um eine bestimmte KPI-Leistung zu optimieren, sondern um Muster in den Daten zu erkennen, die umsetzbare und wertvolle Erkenntnisse liefern. Wenn Sie beispielsweise den Umsatz verbessern möchten, untergraben Sie möglicherweise Ihren Erfolg, indem Sie nur Preismuster betrachten. Andere Faktoren sind beteiligt.
Nehmen Sie ein Beispiel von meinem Kollegen. Ein neuer Evo-Kunde wollte den Umsatz steigern, und ein erster Test mit unseren Supply-Chain-Tools zeigte eine Verbesserung von 10% in weniger als zwei Wochen. Unser CEO war von diesen beispiellosen Ergebnissen mehr als begeistert, aber zu seiner Überraschung war der Supply Chain Manager nicht beeindruckt. Sein primärer KPI war die Produktverfügbarkeit, und laut internen Zahlen hatte sich das nie geändert. Sein Fokus auf die Verbesserung eines bestimmten KPI ging zu Lasten der Erkennung wertvoller Erkenntnisse aus anderen Daten.


Unabhängig davon, ob dieser KPI genau gemessen wurde oder nicht, hielt die Konzentration auf die Änderung seiner Leistung diesen Manager davon ab, den Wert in einem neuen Ansatz zu sehen. Er war ein kluger Mann, der in gutem Glauben handelte, aber die Daten führten ihn in die Irre — ein unglaublich häufiger, aber teurer Fehler. Korrekte Datengranularität ist wichtig, kann aber kein Ziel an und für sich sein. Sie müssen das Gesamtbild betrachten, um Ihre KI-Erträge zu maximieren. Wie genau Sie sich Ihre Daten ansehen, spielt keine Rolle, wenn Sie nicht über die richtigen Daten verfügen.
“ Ein häufiger Trugschluss des datengesteuerten Managements ist die Verwendung der falschen Daten, um die richtige Frage zu beantworten „. – Fabrizio Fantini, Gründer und CEO von Evo
Die Vorteile der richtigen Datengranularität
Es gibt kein Wundermittel, wenn es um Datengranularität geht. Sie müssen es sorgfältig und absichtlich auswählen, um diese und andere weniger häufige Fehler zu vermeiden. Die einzige Möglichkeit, die Rendite Ihrer Daten zu maximieren, besteht darin, sie kritisch zu betrachten — normalerweise mit Hilfe eines erfahrenen Datenwissenschaftlers. Sie werden wahrscheinlich beim ersten Versuch keine Granularität erhalten, also müssen Sie testen und anpassen, bis es perfekt ist.
Es lohnt sich jedoch. Wenn Sie genau, aber nicht zu genau hinschauen, sorgen Ihre Daten für optimale Business Intelligence. Richtig segmentiert und analysiert, verwandeln sich Daten in einen Wettbewerbsvorteil, auf den Sie sich verlassen können.