Maximum Likelihood Estimation > EM-Algorithmus (Erwartungsmaximierung)
Vielleicht möchten Sie diesen Artikel zuerst lesen: Was ist eine Maximum-Likelihood-Schätzung?
Was ist der EM-Algorithmus?
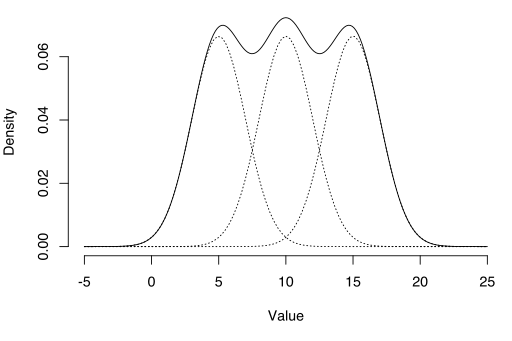
Mit dem EM-Algorithmus können latente Variablen geschätzt werden, z. B. solche, die aus Mischungsverteilungen stammen (Sie wissen, dass sie aus einer Mischung stammen, aber nicht aus welcher spezifischen Verteilung).
Der EM-Algorithmus (Expectation-Maximization) ist eine Methode zum Ermitteln von Maximum-Likelihood-Schätzungen für Modellparameter, wenn Ihre Daten unvollständig sind, fehlende Datenpunkte aufweisen oder unbeobachtete (versteckte) latente Variablen aufweisen. Es ist ein iterativer Weg, um die Maximum-Likelihood-Funktion zu approximieren. Während die Maximum-Likelihood-Schätzung das „Best-Fit“ -Modell für einen Datensatz finden kann, funktioniert sie bei unvollständigen Datensätzen nicht besonders gut. Der komplexere EM-Algorithmus kann Modellparameter auch dann finden, wenn Daten fehlen. Es funktioniert, indem zufällige Werte für die fehlenden Datenpunkte ausgewählt und diese Vermutungen verwendet werden, um einen zweiten Datensatz zu schätzen. Die neuen Werte werden verwendet, um eine bessere Schätzung für den ersten Satz zu erstellen, und der Vorgang wird fortgesetzt, bis der Algorithmus an einem festen Punkt konvergiert.
Siehe auch: EM-Algorithmus in einem Bild erklärt.
MLE vs. EM
Obwohl Maximum Likelihood Estimation (MLE) und EM beide „Best-Fit“ -Parameter finden können, sind die Modelle sehr unterschiedlich. MLE sammelt zuerst alle Daten und verwendet diese Daten dann, um das wahrscheinlichste Modell zu erstellen. EM nimmt zuerst eine Schätzung der Parameter vor – unter Berücksichtigung der fehlenden Daten – und optimiert dann das Modell, um es an die Vermutungen und die beobachteten Daten anzupassen. Die grundlegenden Schritte für den Algorithmus sind:
- Eine erste Vermutung wird für die Parameter des Modells gemacht und eine Wahrscheinlichkeitsverteilung wird erstellt. Dies wird manchmal als „E-Step“ für die „erwartete“ Verteilung bezeichnet.
- Neu beobachtete Daten werden in das Modell eingespeist.
- Die Wahrscheinlichkeitsverteilung aus dem E-Step wurde angepasst, um die neuen Daten einzubeziehen. Dies wird manchmal als „M-Schritt“ bezeichnet.“
- Die Schritte 2 bis 4 werden wiederholt, bis die Stabilität (d. h. Eine Verteilung, die sich vom E-Schritt zum M-Schritt nicht ändert) erreicht ist.
Der EM-Algorithmus verbessert durch diesen mehrstufigen Prozess immer die Schätzung eines Parameters. Manchmal sind jedoch einige zufällige Starts erforderlich, um das beste Modell zu finden, da der Algorithmus lokale Maxima verfeinern kann, die nicht so nahe an den (optimalen) globalen Maxima liegen. Mit anderen Worten, es kann eine bessere Leistung erbringen, wenn Sie einen Neustart erzwingen und diese „erste Vermutung“ aus Schritt 1 erneut ausführen. Aus allen möglichen Parametern können Sie dann den mit der größten maximalen Wahrscheinlichkeit auswählen.
In Wirklichkeit beinhalten die Schritte einige ziemlich schwere Berechnungen (Integration) und bedingte Wahrscheinlichkeiten, was den Rahmen dieses Artikels sprengt. Wenn Sie eine technischere (dh auf Kalkül basierende) Aufschlüsselung des Prozesses benötigen, empfehle ich Ihnen dringend, das Papier von Gupta und Chen aus dem Jahr 2010 zu lesen.
Anwendungen
Der EM-Algorithmus hat viele Anwendungen, darunter:
- Dis-Verschränkung überlagerter Signale,
- Schätzen von Gaußschen Mischungsmodellen (GMMs),
- Schätzen von Hidden-Markov-Modellen (HMMs),
- Schätzen von Parametern für zusammengesetzte Dirichlet-Verteilungen,
- Finden optimaler Mischungen fester Modelle.
Einschränkungen
Der EM-Algorithmus kann selbst auf dem schnellsten Computer sehr langsam sein. Es funktioniert am besten, wenn Sie nur einen kleinen Prozentsatz fehlender Daten haben und die Dimensionalität der Daten nicht zu groß ist. Je höher die Dimensionalität, desto langsamer der E-Step; bei Daten mit größerer Dimensionalität kann es vorkommen, dass der E-Step extrem langsam ausgeführt wird, wenn sich die Prozedur einem lokalen Maximum nähert.
Dempster, A., Laird, N. und Rubin, D. (1977) Maximale Wahrscheinlichkeit aus unvollständigen Daten über den EM-Algorithmus, Journal der Royal Statistical Society. Reihe B (Methodisch), vol. 39, Nr. 1, S. 1938.
Gupta, M. & Chen, Y. (2010) Theorie und Verwendung des EM-Algorithmus. Grundlagen und Trends in der Signalverarbeitung, Vol. 4, Nr. 3 223-296.
Stephanie Glen. „EM-Algorithmus (Erwartungsmaximierung): Einfache Definition“ Von StatisticsHowTo.com : Elementare Statistiken für den Rest von uns! https://www.statisticshowto.com/em-algorithm-expectation-maximization/
——————————————————————————
Benötigen Sie Hilfe bei einer Hausaufgabe oder Testfrage? Mit Chegg Study erhalten Sie Schritt-für-Schritt-Lösungen für Ihre Fragen von einem Experten auf diesem Gebiet. Deine ersten 30 Minuten mit einem Chegg Tutor sind kostenlos!