Sie haben vielleicht schon lange Baummodelle verwendet oder einen Neuling, aber haben Sie sich jemals gefragt, wie es tatsächlich funktioniert und wie es sich von anderen Algorithmen unterscheidet? Hier, Ich teile einen kurzen Überblick über mein Verständnis.
CART ist auch ein Vorhersagemodell, das hilft, eine Variable basierend auf anderen markierten Variablen zu finden. Um klarer zu sein, sagen die Baummodelle das Ergebnis voraus, indem sie eine Reihe von if-else-Fragen stellen. Es gibt zwei Hauptvorteile bei der Verwendung von Baummodellen,
- Sie sind in der Lage, die Nichtlinearität im Datensatz zu erfassen.
- Keine Notwendigkeit zur Standardisierung von Daten bei der Verwendung von Baummodellen. Weil sie keine euklidische Entfernung oder andere Messfaktoren zwischen Daten berechnen. Nur wenn-sonst.
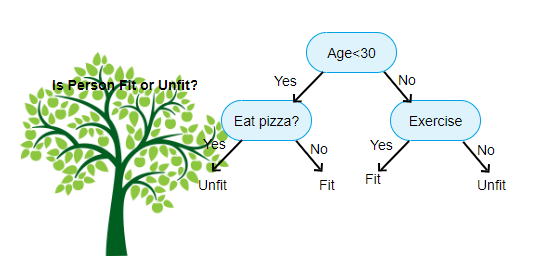
Schrauben und Muttern von Bäumen

Oben gezeigt ist ein Bild des Entscheidungsbaumklassifikators, jede Runde wird als Knoten bezeichnet. Jeder Knoten verfügt über eine if-else-Klausel, die auf einer beschrifteten Variablen basiert. Basierend auf dieser Frage wird jede Instanz der Eingabe an einen bestimmten Blattknoten geleitet / weitergeleitet, der die endgültige Vorhersage angibt. Es gibt drei Arten von Knoten,
- Wurzelknoten: hat keinen übergeordneten Knoten und gibt zwei untergeordnete Knoten basierend auf der Frage
- Interner Knoten: Er hat einen übergeordneten Knoten und zwei untergeordnete Knoten
- Blattknoten: Er hat auch einen übergeordneten Knoten, hat jedoch keine untergeordneten Knoten
Die Anzahl der Ebenen, die wir haben, wird als max_depth bezeichnet. Im obigen Diagramm ist max_depth = 3. Mit zunehmender max_depth nimmt auch die Modellkomplexität zu. Während wir trainieren, wenn wir es erhöhen, wird der Trainingsfehler immer sinken oder gleich bleiben. Aber es kann manchmal den Testfehler erhöhen. Wir müssen also wählerisch sein, wenn wir die max_depth für ein Modell auswählen.
Ein weiterer interessanter Faktor bei Node ist der Informationsgewinn(IR). Dies ist ein Kriterium zur Messung der Reinheit eines Knotens. Die Reinheit wird daran gemessen, wie clever ein Knoten Elemente aufteilen kann. Angenommen, Sie befinden sich an einem Knoten und möchten entweder nach links oder rechts gehen. Sie haben jedoch Elemente, die zu beiden Klassen gehören, in derselben Menge (50-50) an jedem Knoten. Dann ist die Reinheit beider Klassen gering, weil Sie nicht wissen, welche Richtung Sie wählen sollen. Einer muss höher sein als der andere, um eine Entscheidung zu treffen. dies wird mit IR gemessen,
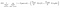

Wie der Name schon sagt, besteht das Ziel von CART darin, anhand der beschrifteten Werte vorherzusagen, zu welcher Klasse eine Eingabeinstanz gehört. Um dies zu erreichen, werden Entscheidungsregionen mithilfe von Entscheidungsgrenzen erstellt. Stellen Sie sich vor, wir haben einen 2D-Datensatz,

Auf diese Weise wird unser mehrdimensionaler Datensatz basierend auf den If-else-Fragen an jedem Knoten in Entscheidungsregionen unterteilt. CART-Modelle können genauere Entscheidungsbereiche finden als lineare Modelle. Und die Entscheidungsbereiche von CART sind typischerweise rechteckig geformt, da nur ein Merkmal an jedem Knoten an der Entscheidungsfindung beteiligt ist. Sie können es unten visualisieren,

Ich denke, es ist genug von Einführungen, sehen wir uns einige Beispiele an, wie man CART-Modelle auf Scikit Learn erstellt.
Klassifikationsbaum
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regressionsbaum
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Ich hoffe, dieser Artikel ist nützlich.