olet saattanut käyttää puumalleja pitkään tai vasta-alkajana, mutta oletko koskaan miettinyt, miten se toimii ja miten se eroaa muista algoritmeista? Tässä kerron lyhyesti ymmärryksistäni.
CART on myös ennustemalli, joka auttaa löytämään muuttujan, joka perustuu muihin merkittyihin muuttujiin. Selvyyden vuoksi puumallit ennustavat lopputuloksen kysymällä joukon if-else-kysymyksiä. Puumallien käytössä on kaksi suurta etua,
- ne pystyvät vangitsemaan ei-lineaarisuus aineisto.
- tietoja ei tarvitse standardoida puumalleja käytettäessä. Koska ne eivät laske mitään euklidista etäisyyttä tai muita mittauskertoimia datan välillä. Vain jos …
puiden mutterit ja pultit

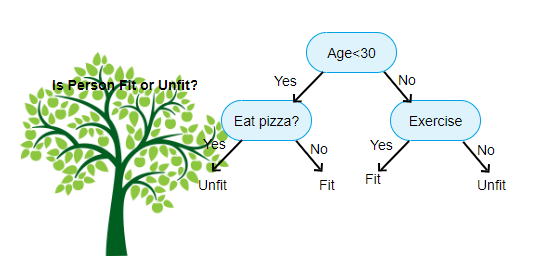
yllä esitetty on kuva päätöksenteon Puu luokittelija, jokainen kierros tunnetaan solmuja. Jokaisella solmulla on merkittyyn muuttujaan perustuva if-else-lauseke. Tämän kysymyksen perusteella jokainen tuloesimerkki ohjataan / reititetään tiettyyn lehtisolmuun, joka kertoo lopullisen ennusteen. Solmuja on kolmenlaisia,
- Juurisolmu: ei ole kantasolmua, ja antaa kahdelle lapselle solmuja kysymyksen
- sisäisen solmun perusteella: sillä on kantasolmu, ja antaa kahdelle lapselle solmut
- lehtisolmu: sillä on myös kantasolmu, mutta ei yhtään lasten solmua
meidän tasojen lukumäärä tunnetaan nimellä max_depth. Yllä olevassa kaaviossa max_depth = 3. Kun max_depth kasvaa, mallin monimutkaisuus myös kasvaa. Kun harjoittelemme, jos lisäämme sitä, harjoitusvirhe laskee aina tai pysyy samana. Mutta se voi joskus lisätä testausvirhe. Joten meidän täytyy olla valikoiva valitessamme max_depth mallille.
toinen kiinnostava tekijä solmussa on Information gain (IR). Tämä on kriteeri, jolla mitataan solmun puhtautta. Puhtautta mitataan sen perusteella, kuinka näppärästi solmu osaa jakaa kohteita. Oletetaan, että olet solmussa ja haluat mennä joko vasemmalle tai oikealle. Mutta sinulla on kohteita kuuluu molempiin luokkiin sama määrä (50-50) kussakin solmussa. Silloin molempien luokkien puhtaus on alhainen, koska ei tiedä, minkä suunnan valitsee. Toisen on oltava toista korkeampi tehdäkseen päätöksen. tämä mitataan IR: llä,

kuten nimikin sanoo, CART: n tavoitteena on ennustaa, mihin luokkaan tuloesitys kuuluu sen merkittyjen arvojen perusteella. Tämän saavuttamiseksi se tekee päätöksen alueilla käyttäen päätöksen rajoja. Kuvittele, että meillä on 2D-aineisto,

näin se erottaa moniulotteisen tietokokonaisuutemme Päätösalueiksi kunkin solmun if-else-kysymysten perusteella. CART-Mallit voivat löytää tarkempia päätösalueita kuin lineaariset mallit. Ja päätösalueet CART ovat tyypillisesti suorakaiteen muotoinen, koska, vain yksi ominaisuus mukana jokaisessa solmussa päätöksenteossa. Voit visualisoida sen alla,

mielestäni se riittää esittelyjä, Katsotaanpa joitakin esimerkkejä siitä, miten rakentaa CART malleja Scikit oppia.
Luokituspuu
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regressiopuu
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Toivottavasti tämä artikkeli on hyödyllinen, jos sinulla on keskusteluja tai ehdotuksia, Jätä yksityisviesti.