À l’ère du big data, le défi n’est plus d’accéder à suffisamment de données; le défi consiste à trouver les bonnes données à utiliser. Dans un article précédent, je me suis concentré sur la valeur des données alternatives, qui sont un atout vital pour l’entreprise. Cependant, même avec les avantages des données alternatives, une mauvaise granularité des données peut compromettre le retour sur investissement de la gestion axée sur les données.
» Nous sommes tellement obsédés par les données que nous oublions comment les interpréter « . – Danah Boyd, Chercheuse principale chez Microsoft Research
Alors, à quelle distance devriez-vous regarder vos données? Parce qu’une mauvaise granularité des données pourrait vous coûter plus cher que vous ne le pensez.
En termes simples, la granularité des données fait référence au niveau de détail de nos données. Plus vos données sont granulaires, plus il y a d’informations contenues dans un point de données particulier. La mesure des transactions annuelles dans tous les magasins d’un pays aurait une faible granularité, car vous en sauriez très peu sur le moment et l’endroit où les clients effectuent ces achats. Mesurer les transactions des magasins individuels à la seconde, en revanche, aurait une granularité incroyablement élevée.
La granularité idéale des données dépend du type d’analyse que vous effectuez. Si vous recherchez des modèles de comportement des consommateurs sur plusieurs décennies, une faible granularité convient probablement. Pour automatiser le réapprovisionnement du magasin, cependant, vous auriez besoin de données beaucoup plus granulaires.
Lorsque vous choisissez la mauvaise granularité pour votre analyse, vous vous retrouvez avec une intelligence moins précise et moins utile. Pensez à quel point le réapprovisionnement hebdomadaire du magasin basé uniquement sur les données annuelles du système serait désordonné! Vous subissez continuellement des stocks excédentaires et des ruptures de stock, ce qui entraîne des coûts énormes et des niveaux élevés de déchets. Dans toute analyse, une mauvaise granularité des données peut avoir des conséquences tout aussi graves sur votre efficacité et vos résultats.
Utilisez-vous donc la granularité des données correcte pour votre business intelligence? Voici cinq erreurs courantes — et coûteuses — de granularité des données.
Regroupement de plusieurs tendances commerciales en un seul modèle (lorsque les données ne sont pas suffisamment granulaires).
La Business intelligence doit être claire et directe pour pouvoir être mise en œuvre, mais parfois, dans un souci de simplicité, les gens ne plongent pas assez profondément dans les données. C’est dommage car vous passerez à côté de précieuses informations. Lorsque la granularité des données est trop faible, vous ne voyez que de grands motifs qui apparaissent à la surface. Vous risquez de manquer des données critiques.
Dans beaucoup trop de cas, le fait de ne pas examiner suffisamment vos données conduit à compresser des tendances disparates en un seul résultat. Les entreprises qui commettent cette erreur se retrouvent avec des résultats inégaux. Ils sont plus susceptibles d’avoir des valeurs aberrantes imprévisibles et extrêmes qui ne correspondent pas au modèle global — parce que ce modèle ne reflète pas la réalité.
C’est un problème courant dans de nombreux systèmes de prévision de la chaîne d’approvisionnement traditionnels. Ils ne peuvent pas gérer le niveau de granularité nécessaire pour prédire la demande au niveau SKU dans les magasins individuels, ce qui signifie qu’un seul magasin peut faire face à la fois à des stocks excédentaires et à des ruptures de stock en même temps. Les systèmes automatisés alimentés par l’IA peuvent gérer la complexité requise pour segmenter correctement les données, ce qui est l’une des raisons pour lesquelles ils améliorent l’efficacité de la chaîne d’approvisionnement. Une granularité suffisante des données est essentielle pour une intelligence d’affaires plus précise.

Se perdre dans les données sans point de focalisation (lorsque les données sont trop granulaires).
Avez-vous déjà accidentellement zoomé trop loin sur une carte en ligne? C’est tellement frustrant! Vous ne pouvez pas distinguer d’informations utiles car il n’y a pas de contexte. Cela se produit aussi dans les données.
Si vos données sont trop granulaires, vous vous perdez; vous ne pouvez pas vous concentrer suffisamment pour trouver un modèle utile dans toutes les données étrangères. Il est tentant de penser que plus de détails sont toujours meilleurs en matière de données, mais trop de détails peuvent rendre vos données pratiquement inutiles. De nombreux cadres confrontés à autant de données se retrouvent gelés par la paralysie de l’analyse. Vous vous retrouvez avec des recommandations peu fiables, un manque de contexte commercial et une confusion inutile.
Des données trop granulaires sont une erreur particulièrement coûteuse en matière de prévision de l’IA. Les données peuvent tromper l’algorithme en indiquant qu’il dispose de suffisamment de données pour émettre des hypothèses sur l’avenir qui ne sont pas possibles avec la technologie d’aujourd’hui. Dans mon travail de chaîne d’approvisionnement chez Evo, par exemple, il est toujours impossible de prévoir les ventes quotidiennes par SKU. Votre marge d’erreur sera trop grande pour être utile. Ce niveau de granularité sape les objectifs et diminue le retour sur investissement.
Ne pas choisir la granularité des variables temporelles à dessein.
Les erreurs de granularité des données les plus courantes sont liées aux intervalles de temps, c’est-à-dire à la mesure de variables horaires, quotidiennes, hebdomadaires, annuelles, etc. base. Les erreurs de granularité temporelle se produisent souvent pour des raisons de commodité. La plupart des entreprises ont des moyens standard de déclarer des variables chronométrées. On a l’impression que cela nécessiterait trop d’efforts pour les changer, alors ils ne le font pas. Mais c’est rarement la granularité idéale pour résoudre le problème analysé.
Lorsque vous évaluez le coût de la modification de la façon dont votre système rapporte les KPI par rapport au coût d’une veille stratégique inadéquate, les avantages de choisir délibérément le bon registre de granularité. Selon la granularité du temps, vous reconnaîtrez des informations très différentes à partir des mêmes données. Prenez les tendances saisonnières dans le commerce de détail, par exemple. L’examen des transactions sur une seule journée pourrait rendre les tendances saisonnières invisibles ou, à tout le moins, contenir tellement de données que les modèles ne sont que du bruit blanc, tandis que les données mensuelles partagent une séquence distincte que vous pouvez réellement utiliser. Si les indicateurs de performance clés standard sautent les rapports mensuels pour passer directement aux modèles trimestriels, vous perdez des informations précieuses qui rendraient les prévisions plus précises. Vous ne pouvez pas prendre la granularité du temps à sa valeur nominale si vous voulez obtenir la meilleure intelligence.


Surajustement ou sous-ajustement de votre modèle au point que les motifs que vous voyez n’ont aucun sens.
Les modèles d’IA doivent bien se généraliser à partir des données existantes et futures pour fournir des recommandations utiles. Essentiellement, un bon modèle pourrait examiner ces données:

Et supposons cela comme un modèle de travail basé sur les informations:

Le modèle peut ne pas représenter parfaitement les données, mais il fait un bon travail de prédiction du comportement typique sans sacrifier trop d’intelligence.
Si vous n’avez pas la bonne granularité de données, cependant, vous pouvez vous retrouver avec le mauvais modèle. Comme nous en avons parlé précédemment, des données trop granulaires peuvent causer du bruit qui rend difficile la recherche d’un modèle. Si votre algorithme s’entraîne systématiquement avec ce niveau de détail bruyant, il émettra du bruit à son tour. Vous vous retrouvez avec un modèle qui ressemble à ceci:

Nous appelons cela un surajustement de votre modèle. Chaque point de données a un impact démesuré, dans la mesure où le modèle ne peut plus se généraliser utilement. Les problèmes initialement causés par une granularité élevée sont amplifiés et deviennent un problème permanent dans le modèle.
Une granularité de données trop faible peut également endommager votre modèle à long terme. Un algorithme doit avoir suffisamment de données pour trouver des modèles. Les algorithmes formés à l’aide de données sans granularité suffisante manqueront les modèles critiques. Une fois que l’algorithme a dépassé la phase d’entraînement, il continuera à ne pas identifier de modèles similaires. Vous vous retrouvez avec un modèle qui ressemble à ceci:
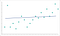
C’est sous-adapté au modèle. L’algorithme est proche de faire les bonnes prédictions, mais elles ne seront jamais aussi précises qu’elles auraient pu l’être. Comme le surajustement, il s’agit d’un grossissement du problème de granularité initial.
Lorsque vous créez un modèle pour votre analyse, une granularité appropriée devient exponentiellement plus importante qu’une fois que vous avez un algorithme stable. Pour cette raison, de nombreuses entreprises choisissent d’externaliser cette partie du processus à des experts. C’est une étape trop délicate et coûteuse pour les erreurs.
Ajuster entièrement la granularité des données incorrectes.
L’erreur de granularité des données la plus coûteuse consiste peut-être à se concentrer tellement sur l’optimisation de la granularité des KPI que vous mesurez actuellement que vous ne réalisez pas qu’il s’agit entièrement des mauvais KPI. Nous visons à atteindre la granularité correcte des données, non pas pour optimiser les performances des indicateurs clés de performance spécifiques, mais plutôt pour reconnaître les modèles dans les données qui fournissent des informations exploitables et précieuses. Si vous souhaitez améliorer vos revenus, par exemple, vous risquez de saper votre succès en ne regardant que les modèles de tarification. D’autres facteurs sont impliqués.
Prenons un exemple de mon collègue. Un nouveau client d’Evo souhaitait augmenter ses ventes, et un premier test d’application de nos outils de chaîne d’approvisionnement a montré une amélioration de 10% en moins de deux semaines. Notre PDG était au-delà de l’enthousiasme de ces résultats sans précédent, mais à sa grande surprise, le responsable de la chaîne d’approvisionnement n’a pas été impressionné. Son principal indicateur de performance clé était la disponibilité des produits, et selon les chiffres internes, cela n’avait jamais changé. Il s’est concentré sur l’amélioration d’un KPI particulier au prix de la reconnaissance d’informations précieuses provenant d’autres données.


Que ce KPI ait été mesuré avec précision ou non, en se concentrant entièrement sur l’évolution de ses performances, ce gestionnaire n’a pas pu voir la valeur d’une nouvelle approche. C’était un homme intelligent agissant de bonne foi, mais les données l’ont induit en erreur — une erreur incroyablement courante mais coûteuse. La granularité correcte des données est essentielle, mais cela ne peut pas être un objectif en soi. Vous devez examiner la situation dans son ensemble pour maximiser vos retours de l’IA. Peu importe à quel point vous examinez vos données si vous ne disposez pas des bonnes données en premier lieu.
» Une erreur courante de gestion axée sur les données consiste à utiliser les mauvaises données pour répondre à la bonne question « . – Fabrizio Fantini, fondateur et PDG d’Evo
Les avantages de la bonne granularité des données
Il n’y a pas de solution miracle en matière de granularité des données. Vous devez le choisir avec soin et intentionnellement pour éviter ces erreurs et d’autres moins courantes. La seule façon de maximiser les rendements de vos données est de les examiner de manière critique, généralement avec l’aide d’un expert en data scientist. Vous n’obtiendrez probablement pas de granularité dès votre premier essai, vous devez donc tester et ajuster jusqu’à ce qu’elle soit parfaite.
Cela en vaut la peine, cependant. En regardant de près, mais pas trop, vos données garantissent une intelligence d’affaires optimale. Segmentées et analysées correctement, les données se transforment en un avantage concurrentiel sur lequel vous pouvez compter.