Estimation du Maximum de Vraisemblance > Algorithme EM (Maximisation des attentes)
Vous voudrez peut-être lire cet article en premier: Qu’est-ce que l’Estimation du Maximum de Vraisemblance?
Qu’est-ce que l’algorithme EM ?
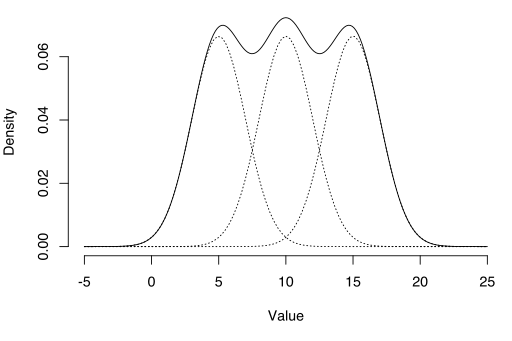
L’algorithme EM peut être utilisé pour estimer des variables latentes, comme celles qui proviennent de distributions de mélange (vous savez qu’elles proviennent d’un mélange, mais pas de quelle distribution spécifique).
L’algorithme de maximisation des attentes (EM) est un moyen de trouver des estimations de probabilité maximale pour les paramètres du modèle lorsque vos données sont incomplètes, ont des points de données manquants ou ont des variables latentes non observées (cachées). C’est une façon itérative d’approximer la fonction de maximum de vraisemblance. Bien que l’estimation du maximum de vraisemblance puisse trouver le modèle « le mieux adapté » à un ensemble de données, elle ne fonctionne pas particulièrement bien pour les ensembles de données incomplets. L’algorithme EM plus complexe peut trouver les paramètres du modèle même si vous avez des données manquantes. Il fonctionne en choisissant des valeurs aléatoires pour les points de données manquants et en utilisant ces suppositions pour estimer un deuxième ensemble de données. Les nouvelles valeurs sont utilisées pour créer une meilleure estimation pour le premier ensemble, et le processus se poursuit jusqu’à ce que l’algorithme converge vers un point fixe.
Voir aussi: Algorithme EM expliqué en une seule image.
MLE vs EM
Bien que l’Estimation du maximum de vraisemblance (MLE) et EM puissent toutes deux trouver les paramètres « les mieux adaptés », la façon dont elles trouvent les modèles est très différente. MLE accumule d’abord toutes les données, puis utilise ces données pour construire le modèle le plus probable. EM prend d’abord une estimation des paramètres — en tenant compte des données manquantes — puis modifie le modèle pour l’adapter aux suppositions et aux données observées. Les étapes de base de l’algorithme sont:
- Une première estimation est faite pour les paramètres du modèle et une distribution de probabilité est créée. Ceci est parfois appelé « E-Step » pour la distribution « Attendue ».
- Les données nouvellement observées sont introduites dans le modèle.
- La distribution de probabilité de l’étape E est modifiée pour inclure les nouvelles données. Ceci est parfois appelé le « pas en M. »
- Les étapes 2 à 4 sont répétées jusqu’à ce que la stabilité (c’est-à-dire une distribution qui ne change pas de l’étape E à l’étape M) soit atteinte.
L’algorithme EM améliore toujours l’estimation d’un paramètre grâce à ce processus en plusieurs étapes. Cependant, il faut parfois quelques démarrages aléatoires pour trouver le meilleur modèle car l’algorithme peut affiner un maximum local qui n’est pas si proche des maxima globaux (optimaux). En d’autres termes, il peut mieux fonctionner si vous le forcez à redémarrer et reprenez cette « supposition initiale » de l’étape 1. Parmi tous les paramètres possibles, vous pouvez ensuite choisir celui qui présente le maximum de vraisemblance.
En réalité, les étapes impliquent un calcul assez lourd (intégration) et des probabilités conditionnelles, ce qui dépasse le cadre de cet article. Si vous avez besoin d’une ventilation plus technique (c’est-à-dire basée sur le calcul) du processus, je vous recommande fortement de lire l’article de Gupta et Chen en 2010.
Applications
L’algorithme EM a de nombreuses applications, notamment:
- Dés-enchevêtrement des signaux superposés,
- Estimation des modèles de mélanges gaussiens (GMM),
- Estimation des modèles de Markov cachés (HMM),
- Estimation des paramètres pour les distributions de Dirichlet composées,
- Recherche de mélanges optimaux de modèles fixes.
Limitations
L’algorithme EM peut être très lent, même sur l’ordinateur le plus rapide. Cela fonctionne mieux lorsque vous n’avez qu’un faible pourcentage de données manquantes et que la dimensionnalité des données n’est pas trop grande. Plus la dimensionnalité est élevée, plus l’étape E est lente; pour les données de plus grande dimension, vous pouvez trouver que l’étape E s’exécute extrêmement lentement à mesure que la procédure approche d’un maximum local.
Dempster, A., Laird, N., et Rubin, D. (1977) Maximum de vraisemblance à partir de données incomplètes via l’algorithme EM, Journal of the Royal Statistical Society. Série B (méthodologique), vol. 39, no 1, p. 1ñ38.
Gupta, M. & Chen, Y. (2010) Théorie et utilisation de l’algorithme EM. Fondements et tendances du traitement du signal, Vol. 4, No 3 223-296.
Stephanie Glen. » Algorithme EM (maximisation des attentes): Définition simple « De StatisticsHowTo.com : Statistiques élémentaires pour le reste d’entre nous! https://www.statisticshowto.com/em-algorithm-expectation-maximization/
——————————————————————————
Besoin d’aide pour une question de devoirs ou de test? Avec Chegg Study, vous pouvez obtenir des solutions étape par étape à vos questions d’un expert dans le domaine. Vos 30 premières minutes avec un tuteur Chegg sont gratuites!