Temps de lecture : 13 minutes
L’approche agile du développement logiciel est depuis longtemps une pratique courante. Selon le sondage en ligne de HP, 16% des professionnels de l’informatique optent pour l’agilité pure, 51% se tournent vers l’informatique et 24% adoptent une approche hybride agile. Aujourd’hui, le développement en cascade est mentionné le plus souvent comme un différenciateur agile, ce qu’agile n’est pas. Nous avons largement discuté des principales différences dans notre livre blanc sur les méthodologies de gestion de projet agile.
Malgré l’adaptabilité et la flexibilité de la gestion agile et sa réponse rapide aux changements, le flux de travail peut rester centralisé et contrôlé. Les KPI agiles (indicateurs clés de performance) fournissent des conseils pour la planification stratégique, l’évaluation et l’amélioration des processus opérationnels.
Les systèmes traditionnels de gestion de la valeur ont tendance à se concentrer sur l’achèvement des tâches dans le cadre d’un calendrier et d’un coût catégoriels. Cependant, avec agile, les clients et les membres de l’équipe voient des résultats immédiats et ajustent les délais et les efforts pour livrer un produit qui correspond aux exigences du calendrier. Quels outils et techniques ces connaissances exigent-elles ? Voici notre aperçu de l’évaluation des performances des métriques de développement agile.
KPI de développement logiciel Agile
Dans cet article, nous n’allons pas explorer toutes les métriques et KPI de développement agile possibles. En plus de cela, vous pouvez inventer les vôtres qui correspondent le mieux à votre projet. Cependant, nous décrirons les indicateurs de performance clés les plus courants utilisés dans plusieurs aspects du développement logiciel:
- Vitesse
- Burndown de sprint
- Burndown de libération
- Temps de cycle
- Débit cumulatif
- Efficacité du débit
- Couverture de code par des tests automatisés
- Automatisation des tests par rapport aux tests manuels
- Complexité cyclomatique de McCabe (MCC)
- Churn de code
Ce sont les clés que vous devez d’abord explorer
Mesure des travaux en cours
Vitesse
La vitesse mesure la quantité de travail (un certain nombre de fonctionnalités) accomplie dans un sprint. Bien qu’il ne s’agisse pas d’un outil de prédiction ou de comparaison, velocity fournit aux équipes une idée de la quantité de travail qui peut être effectuée lors du prochain sprint.
L’indice de vélocité est unique pour chaque équipe et doit être défini pour évaluer le réalisme de l’engagement. Par exemple, si le carnet de commandes du projet compte 200 points d’histoire et que l’équipe termine en moyenne 10 points d’histoire par sprint, cela signifie que l’équipe aura besoin d’environ 20 sprints pour terminer le projet.
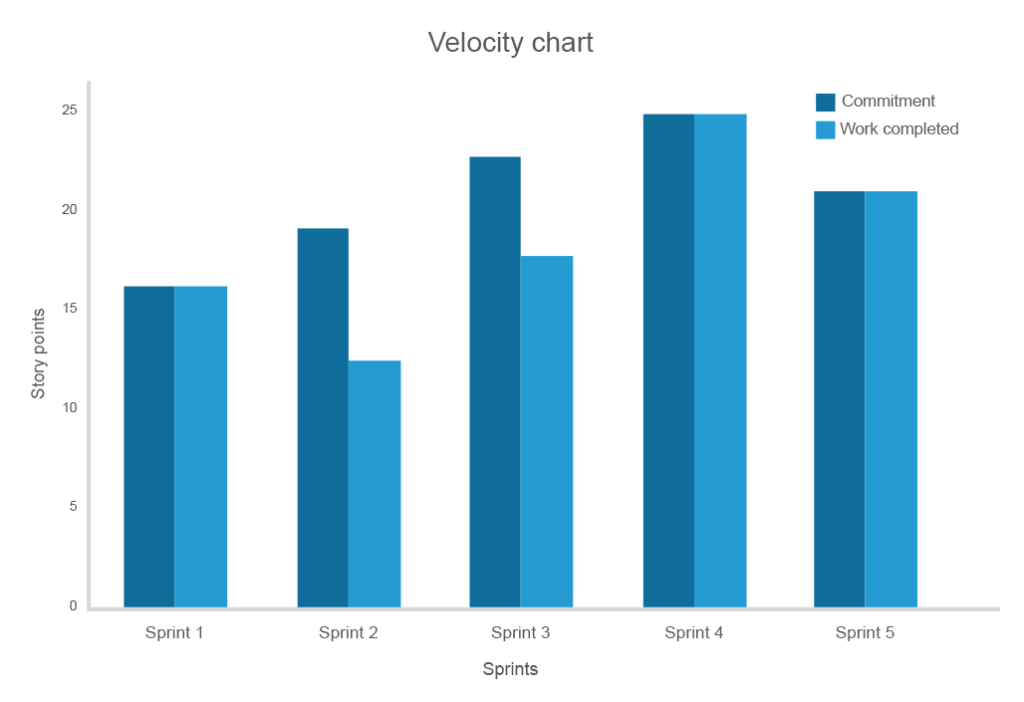
Plus vous suivez la vitesse longtemps, plus la précision de la correspondance entre les obligations et les coûts
Pour une équipe qui vient d’adopter la méthodologie agile ou même de se lancer dans un nouveau produit, les estimations de vélocité des premiers sprints seront probablement erratiques. Mais au fur et à mesure que les équipes acquièrent de l’expérience, la vitesse culminera, puis atteindra un plateau d’espérance de flux et de performances prévisibles. Une diminution du flux constant indiquera des problèmes dans le développement et révélera la nécessité d’un changement.
Conseils pour utiliser la métrique de vitesse
Combattez l’incohérence après 3-5 sprints. Si la vitesse reste incohérente après une longue période de temps, envisagez d’évaluer des facteurs externes et internes empêchant une estimation claire.
Modifiez le suivi de la vitesse en suivant les changements d’équipe et de tâche. Lorsqu’un membre de l’équipe quitte le projet ou que plusieurs membres/tâches sont ajoutés, recalculez la vitesse ou redémarrez entièrement le calcul.
Trois sprints suffisent pour les premières prévisions. Pour prédire les performances futures, utilisez la moyenne des trois sprints précédents.
Graphique de burndown de sprint
Le graphique de burndown de sprint montre la quantité de travail restant à faire avant la fin d’un sprint. L’outil est particulièrement utile car il affiche la progression vers l’objectif au lieu de lister les éléments terminés. C’est également très utile pour découvrir les erreurs de planification qu’une équipe a commises au début d’un sprint.
Sur le graphique ci-dessous, la ligne noire représente la ligne prévue (tendance idéale) indiquant à quel rythme l’équipe doit brûler des points d’histoire pour terminer le sprint à temps. La ligne bleue indique la quantité totale de travail et sa progression tout au long du sprint. Vous pouvez voir que pendant les cinq et six jours, une équipe n’a pas réussi à accomplir les progrès prévus. Cependant, au septième jour, la question a été abordée et les travaux ont repris. Ces mises à jour continues permettent aux équipes de résoudre les problèmes émergents lors de réunions de stand-up quotidiennes.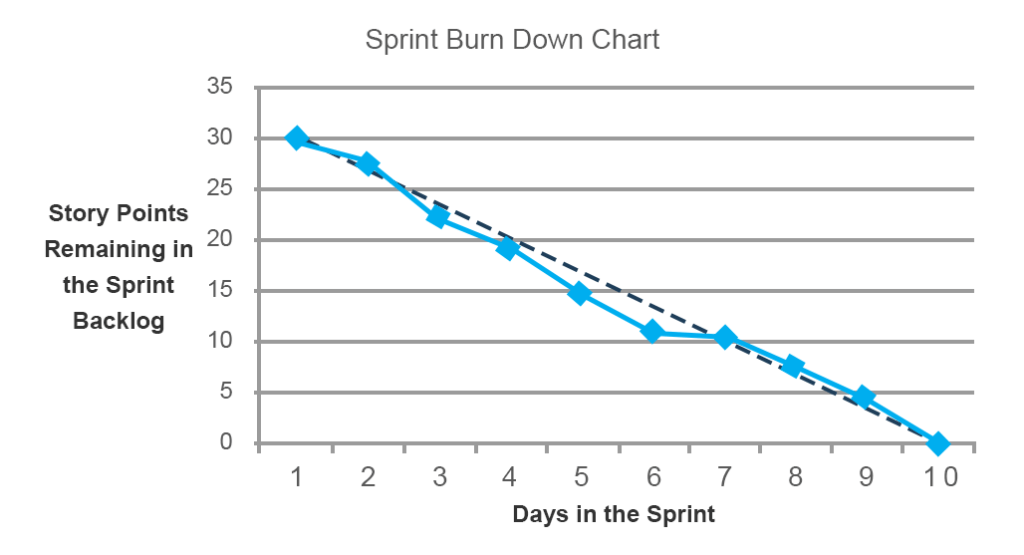
Outre la performance de travail elle-même, les graphiques de burndown peuvent révéler des problèmes de planification
Conseils pour aborder le burndown sprint
Les points d’histoire devraient être même dans la portée. Si le flux de travail n’est pas cohérent, certaines tâches peuvent avoir été divisées en morceaux inégaux. La portée de l’écart entre une tendance idéale et la réalité met clairement en évidence ce problème.
Compte des tâches non planifiées. Le graphique de burndown est utile pour comprendre la portée des tâches cachées et non suivies. Si la quantité de travail augmente au lieu de diminuer, le projet comporte de nombreuses tâches non estimées ou non planifiées qui doivent être traitées.
Utilisez un graphique de burndown pour évaluer la confiance de l’équipe. Compte tenu des taux actuels, demandez à votre équipe à quel point elle est confiante de terminer le sprint à temps. Plus vous appliquez cette métrique longtemps, plus vos estimations de sprint sont précises.
Estimation de la version à l’aide d’un graphique de réduction de la version
Un graphique de réduction de la version indique la quantité de travail à effectuer avant une version. Le graphique illustre la vue d’ensemble des progrès et vous permet de mettre en œuvre des modifications pour assurer une livraison dans les délais.
Une version traditionnelle du graphique est similaire au graphique de burndown de sprint, mais donne un aperçu de l’ensemble du projet où l’axe des ordonnées est des sprints et l’axe des abscisses est une mesure du travail restant (jours, heures ou points d’histoire). Mais que se passe-t-il si plus de travail est ajouté au projet ou si votre travail estimé ne répond pas aux attentes?
Sur le graphique ci-dessous, une équipe prévoyait de terminer un projet en quatre sprints et avait initialement 45 points d’histoire. Alors que la progression s’est déroulée comme prévu lors des premier et deuxième sprints, au troisième sprint, le travail estimé a augmenté, ce qui se reflète sur l’axe des ordonnées en valeurs négatives. Lors du troisième sprint, 5 nouveaux points d’histoire sont apparus. Ils n’étaient pas terminés et le quatrième sprint a ajouté 5 autres points d’histoire. Par conséquent, la progression et le temps de sortie ont dû être ajustés.
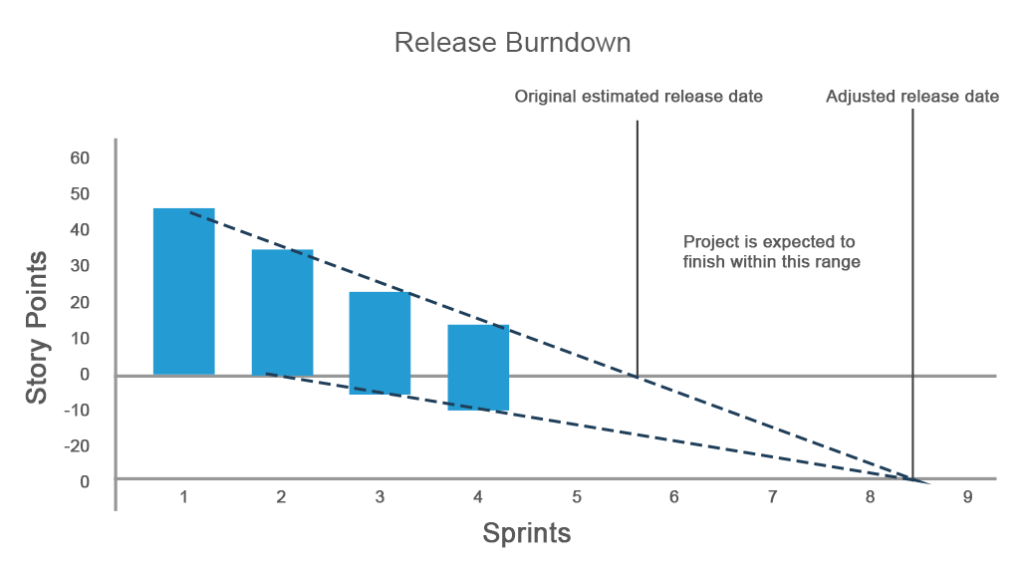
Le graphique de burndown des versions est super efficace pour les situations avec de nombreuses exigences changeantes et permet à une équipe de rester sur la bonne voie lors de chaque sprint
Comment le graphique de burndown des versions peut-il aider?
Prédiction en temps réel à la sortie. Une fois que votre projet subit des modifications, ce qui se produit à chaque fois avec des produits en développement itératif, vous devez voir comment ces modifications affectent la date de sortie. Le graphique de burndown des versions permet de prédire la date de sortie en temps réel en fonction des mises à jour de la portée de travail.
Prévisions d’échéance. Vous pouvez estimer si l’équipe peut terminer une version du produit à temps ou anticiper que la date limite devrait avancer en tenant compte des tâches supplémentaires.
Estimation du nombre de sprints. L’évaluation du nombre de sprints nécessaires pour terminer le travail est également un facteur important à prendre en compte avec le tableau de burndown de libération.
Évaluation de la santé du processus et détection des goulots d’étranglement
Temps de cycle
La mesure du temps de cycle décrit le temps consacré à une tâche, y compris chaque fois que le travail devait être rouvert et terminé à nouveau. Le calcul du temps de cycle fournit des informations sur la performance globale et permet d’estimer l’achèvement des tâches futures. Alors que le temps de cycle plus court illustre de meilleures performances, les équipes qui livrent dans un cycle cohérent sont les plus appréciées.
En utilisant le graphique ci-dessous, vous pouvez identifier le temps moyen nécessaire pour terminer une tâche, tracer une ligne médiane ou une limite de contrôle qui ne doit pas être franchie et remarquer quelles tâches ont pris un temps inhabituellement long à terminer.
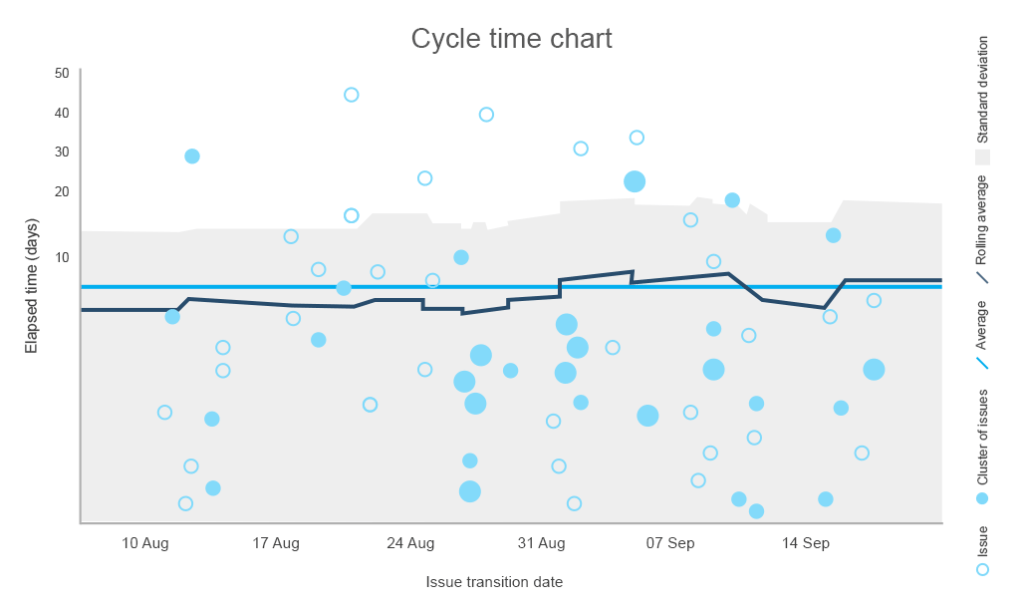
L’écart type trace une ligne entre le nombre de jours normal et non recommandé pour terminer la tâche
Vous pouvez également empiler tous les cycles pour une période particulière et tirer des informations en les comparant à d’autres données. En menant une enquête plus approfondie, vous pouvez tirer des conclusions sur la qualité du travail.
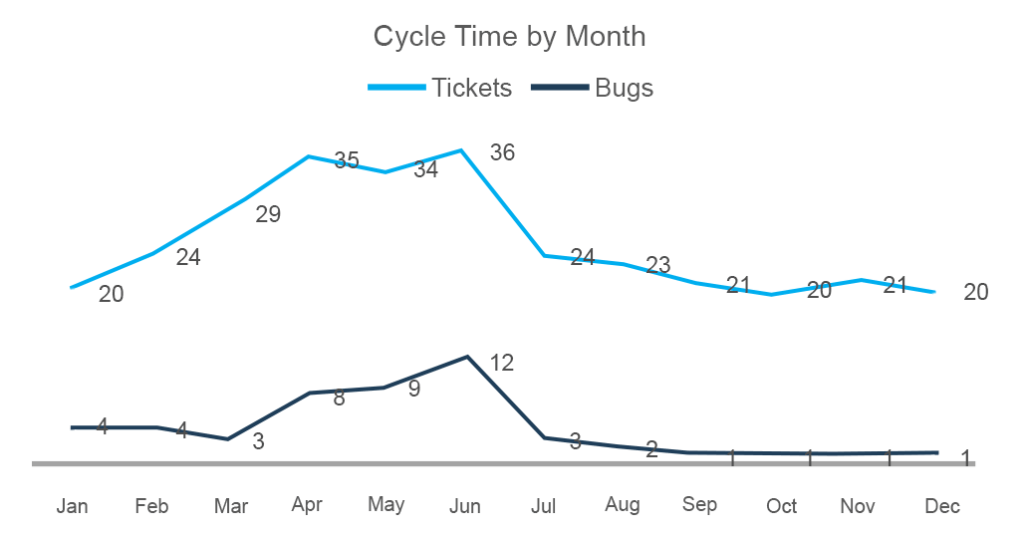
Ici, vous pouvez voir que le nombre de tâches terminées de mars à juin a augmenté, tout comme le nombre de bugs
Comment utiliser le temps de cycle
Recherchez des similitudes. Une bonne pratique consiste à trouver des éléments similaires qui nécessitent des temps de cycle imprévisibles, révélant des problèmes récurrents, que ce soit en ingénierie ou en gestion.
Dessinez des prédictions. Vous pouvez prendre des décisions basées sur les données en prédisant le temps nécessaire pour effectuer de nouvelles tâches sur la base de tâches similaires du passé.
Suivez le rythme. Le tableau décrit comment vous maintenez le même rythme de travail et définit s’il existe des problèmes internes qui réduisent la vitesse du travail.
Diagramme de flux cumulatif (CFC)
La métrique de flux cumulatif est décrite par la zone du graphique indiquant le nombre de différents types de tâches à chaque étape du projet, l’axe des abscisses indiquant les dates et l’axe des ordonnées indiquant le nombre de points d’histoire. Son objectif principal est de fournir une visualisation facile de la répartition des tâches à différentes étapes. Les lignes sur le graphique devraient rester plus ou moins uniformes tandis que le groupe avec les tâches « terminées » devrait croître continuellement.
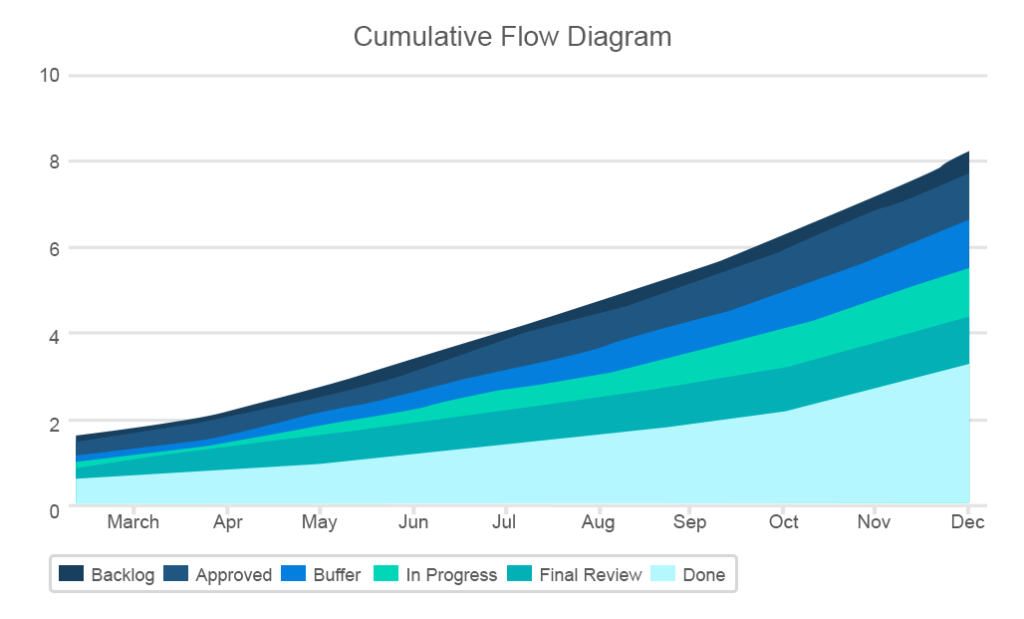
Le graphique divulgue de nombreuses informations critiques telles que des goulots d’étranglement soudains ou des hausses dans l’une des bandes
Le CFC sera d’une grande utilité pour les équipes Kanban en tant que simple visualisation du travail de l’équipe. Le graphique correspond également au flux de travail en trois étapes de Kanban. Ici, vous mappez également trois catégories de tâches principales: tâches à faire, en cours et terminées.
De plus, le graphique permet d’identifier quand les limites de travail en cours (WIP) sont dépassées. Étant l’un des outils les plus précieux du développement agile, les limites WIP sont destinées à cultiver la culture du travail de finition et à éliminer le multitâche en définissant la quantité maximale de travail pour chaque statut de projet.
Quels sont les problèmes signalés par le CFC ?
- La croissance du carnet de commandes indique les tâches non résolues qui sont soit trop peu prioritaires pour le moment, soit obsolètes
- Flux incohérent et goulots d’étranglement soudains indiquent quelles zones doivent être lissées aux étapes ultérieures
- La largeur de chaque bande indique la durée moyenne du cycle
- L’élargissement significatif de la zone « En cours » peut signifier que l’équipe ne sera pas en mesure de terminer l’ensemble du projet dans les délais
Efficacité du débit
L’efficacité du débit est une mesure très utile dans le développement Kanban, principalement négligée par le développement Equipe. Bien que l’efficacité du flux complète le flux cumulé, elle donne un aperçu de la répartition entre le travail réel et les périodes d’attente. C’est un cas rare lorsqu’un développeur travaille sur une chose à la fois sans attendre. La réalité est généralement plus complexe. Et « work-in-progress » est un nom qui ne correspond pas toujours au statut.
Par exemple, le code peut avoir de nombreuses dépendances et vous ne pouvez pas commencer à travailler avec une fonctionnalité avant qu’une autre ne soit terminée, ou que vos priorités changent, ou que vous attendiez l’approbation d’un intervenant. Mesurer le temps d’attente par rapport au travail peut être encore plus utile que de rationaliser les processus liés au travail réel.
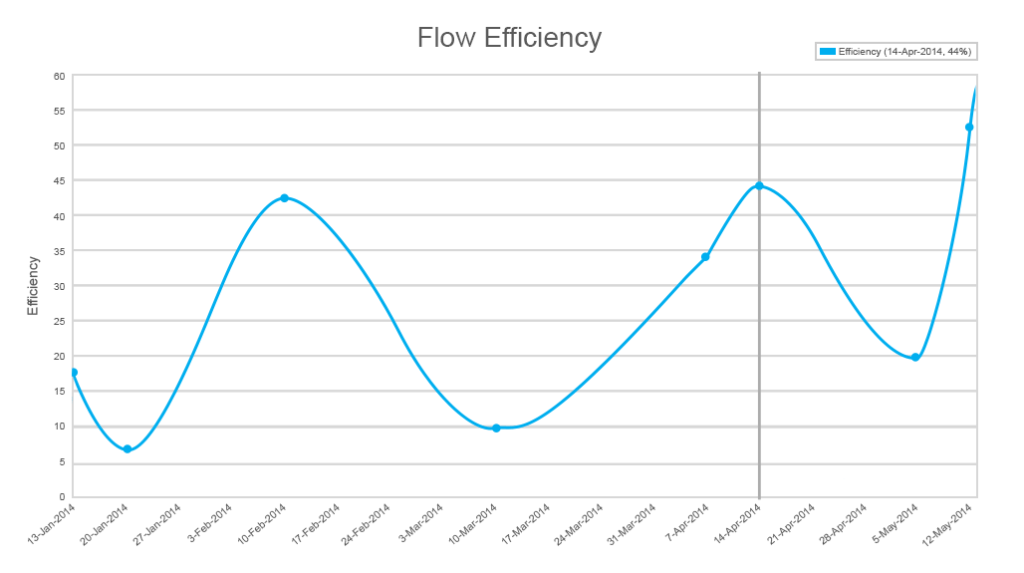
En examinant les indicateurs d’efficacité les plus bas, vous pouvez comprendre les principaux goulots d’étranglement
Comment utiliser la formule de calcul de l’efficacité du débit
. À moins d’appliquer un logiciel de gestion de projet qui intègre ces métriques, vous pouvez calculer l’efficacité du flux par cette formule simple: Travail / (travail + attente) * 100%. Ensuite, vous pouvez le visualiser numériquement ou même dessiner le graphique sur votre tableau blanc de bureau.
Définissez votre efficacité de débit normale. Comme pour toutes les autres mesures, il est impossible de réclamer des chiffres normaux pour tous les projets. Certains disent que la marque de 15% est acceptable pour la plupart des projets, ce qui signifie essentiellement qu’un point d’histoire ou un autre élément de travail attend 85% contre 15% de temps de traitement. David J. Anderson, expert en gestion de la LeanKanban School of Management, suggère que 40% et plus devraient être la cible de la plupart des équipes.
Décomposer les détails du travail avant de fixer l’efficacité du débit. Le graphique permettra de visualiser les périodes exactes pendant lesquelles votre efficacité était la plus faible. Et ces données doivent être analysées très attentivement, car la cause réelle et son remède ne se révèlent pas si facilement. Avant de commencer des actions intensives, faites une enquête approfondie sur les causes.
Augmentez l’efficacité du débit avec l’analyse du bloqueur. Un bon moyen de réaliser le point précédent est d’augmenter l’efficacité de votre flux avec une analyse de clustering de bloqueurs. Si un travail est bloqué, il mérite un autocollant coloré ou une autre forme de signal visuel pour porter ces bloqueurs à l’attention de l’équipe afin qu’elle puisse y réagir.
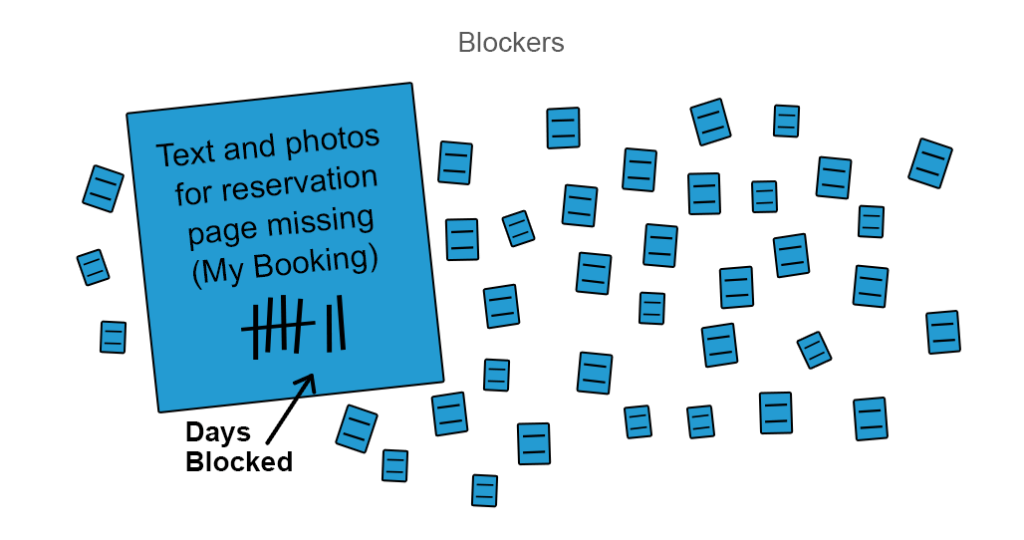
Vous pouvez marquer le nombre de jours pendant lesquels une partie du travail est bloquée et hiérarchiser la résolution
Habituellement, les bloqueurs s’accumulent dans des clusters car ils ont de nombreuses dépendances les uns avec les autres. Une meilleure analyse des bloqueurs peut être effectuée si vous les regroupez à partir de similitudes de haut niveau telles que les bloqueurs internes et externes, puis en spécifiant davantage par conception, le contenu manquant ou d’autres fonctionnalités manquantes. L’analyse du bloqueur est un moyen simple d’étudier les vallées dans l’efficacité de l’écoulement.
Mesure de la qualité du code
Couverture du code
La couverture du code définit le nombre de lignes de code ou de blocs exécutés pendant l’exécution des tests automatisés. La couverture de code est une mesure critique pour la pratique de développement piloté par les tests (TDD) et la livraison continue. Traditionnellement, la métrique est interprétée par une approche simple: Plus la couverture de code est élevée, meilleure est la couverture. Pour mesurer cela, vous aurez besoin de l’un des outils disponibles comme les combinaisons. Mais ils fonctionnent tous à peu près de la même manière: lorsque vous exécutez des tests, l’outil détectera quelles lignes de code sont appelées au moins une fois. Le pourcentage de lignes appelées est la couverture de votre code.
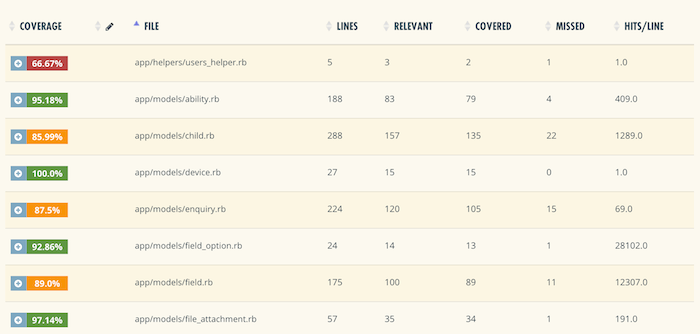

Les combinaisons, par exemple, décomposeront la couverture de code pour chaque mesure de fichier et mettront en évidence les lignes couvertes et non couvertes
Comment utiliser la couverture de code
Concentrez-vous sur les lignes non couvertes et ne surestimez pas celles couvertes. Si la ligne de code est appelée une fois ou même plus, cela ne signifie pas nécessairement que la fonctionnalité qu’elle prend en charge fonctionne parfaitement et que les utilisateurs resteront satisfaits. Appeler une ligne de code n’est pas toujours suffisant pour fermer la tâche de test. D’autre part, le pourcentage de lignes non couvertes montre ce qui n’a pas été couvert du tout et peut mériter des tests.
Priorisez le code couvert et ne visez pas 100%. Bien que cela semble contre-intuitif, une couverture à 100% ne signifie pas que vous avez correctement testé le code. Votre projet a le code qui compte et le reste d’une base de code. Comme l’automatisation des tests est généralement une initiative coûteuse, elle doit prioriser les fonctionnalités et les morceaux de code correspondants.
Automatisation des tests par rapport aux tests manuels
Cette mesure définit le nombre de lignes de code d’une entité déjà couvertes par des tests automatisés par rapport à celles qui sont testées manuellement. Cela suit directement la métrique précédente mais a un cas d’utilisation spécifique. La proportion d’automatisation des tests par rapport aux tests manuels est utilisée uniquement lorsque vous avez un besoin critique d’automatisation pour couvrir les régressions. Des tests de régression sont effectués pour vérifier si quelque chose s’est cassé après les mises à jour des fonctionnalités. Et si votre produit subit des améliorations constantes – ce qu’il devrait faire – les tests de régression doivent être automatisés. Si ce n’est pas le cas, vos spécialistes de l’assurance qualité manuelle devront répéter les mêmes scénarios de test à plusieurs reprises après chaque validation de mise à jour.
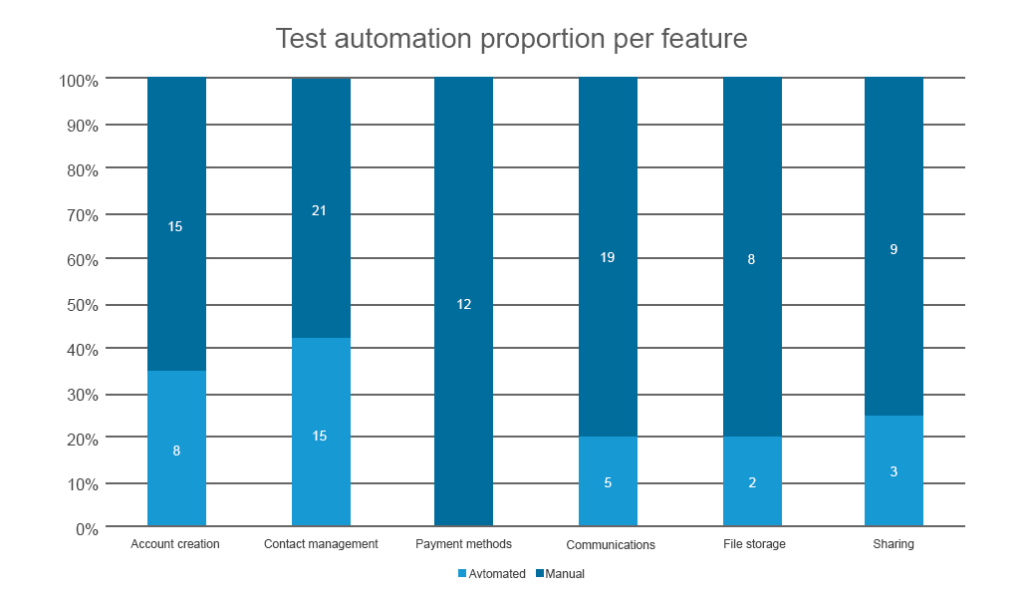
Vous pouvez utiliser les mêmes instruments utilisés pour la couverture de code pour dessiner cette métrique
En décrivant la couverture de test automatisée par fonctionnalité, vous pourrez hiérarchiser les fonctionnalités qui 1) peuvent souffrir de régression après les mises à jour et 2) pour lesquelles les tests automatisés sont critiques. Habituellement, vous n’avez pas assez de temps et de ressources humaines pour tout couvrir par des tests automatisés à la fois, sauf si vous travaillez dans le cadre de développement piloté par les tests. Il est donc préférable de prioriser les fonctionnalités qui auront certainement un impact sur l’expérience utilisateur.
Complexité cyclomatique McCabe (MCC) du code
Les mesures de complexité du code sont utilisées pour évaluer les risques de problèmes lors des tests et de la maintenance du code. Plus la complexité du code est élevée, plus il devient difficile de s’assurer qu’il contient un nombre acceptable de bogues et qu’il conserve une grande maintenabilité. L’approche la plus courante pour mesurer la complexité du code est la métrique de complexité cyclomatique de McCabe (MCC). L’une des formules pour dessiner des résultats de complexité pour MCC est la suivante:
MCC = edges–nœuds + instructions de retour
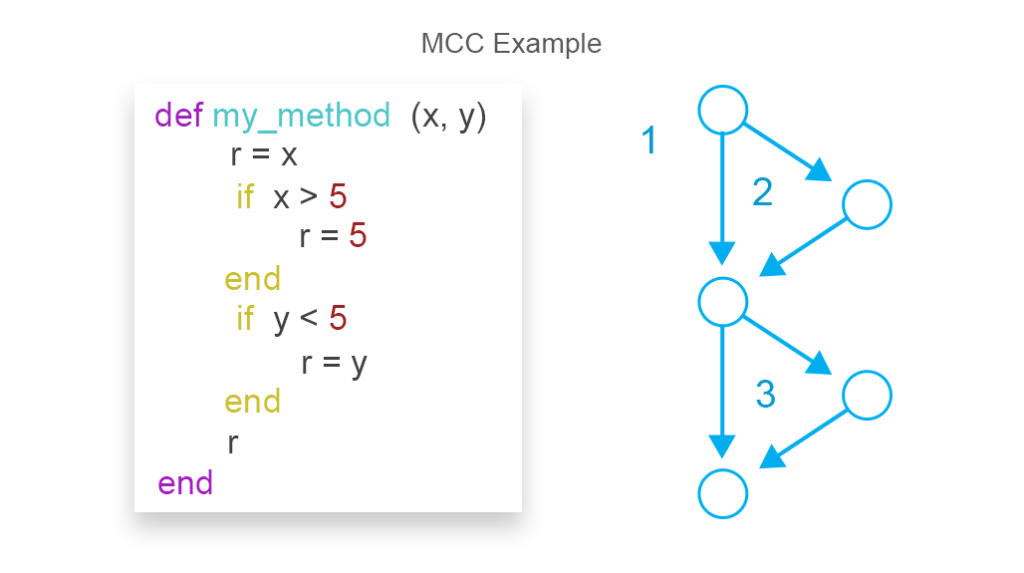
MCC sur l’image est égal à 3
Avec cette métrique, les développeurs n’estiment pas leur complexité de code en la regardant subjectivement. Comme les compétences des ingénieurs diffèrent, leurs évaluations varient, ce qui rend le refactoring du code ou la correction de bugs plus difficiles à plus long terme. Il existe de nombreux outils de mesure MCC sur le marché qui peuvent être combinés avec d’autres mesures de complexité de code telles que la profondeur de la hiérarchie de code et le nombre de lignes de code.
Les spécificités et les pièges de l’utilisation du MCC
Équilibrent la perception humaine et la perception machine de la complexité du code. L’une des principales raisons d’utiliser MCC est de rendre le code lisible pour les autres développeurs. La lisibilité du code réduit les risques d’intégration à long terme des nouveaux développeurs qui doivent gérer du code hérité. Cela simplifiera également le refactoring sur la route. Le problème ici est que le modèle MCC peut considérer certaines méthodes complexes mais lisibles comme inacceptables. Et si vous forcez un développeur à refactoriser des méthodes complexes en de nombreuses sous-méthodes, vous pouvez obtenir les résultats opposés: de nombreuses méthodes avec des logiques simples peuvent devenir encore plus difficiles à comprendre pour un humain qu’une méthode unique mais complexe.
Ne faites pas de MCC une métrique restrictive. Certaines organisations pratiquent la terminaison des commits de code qui ne passent pas le test MCC. Bien que cela puisse potentiellement augmenter la simplicité du code, il est naturel d’avoir un code complexe aux niveaux des classes, des méthodes et des fonctions. Les bloquer entièrement n’est pas toujours bénéfique. Une bonne pratique consiste à définir des KPI de complexité générale du code pour les développeurs, ce qui les encouragera à aborder le codage plus consciemment et à penser à la simplicité.
Appliquer MCC pour la révision du code. Une autre pratique utile pour les tests MCC consiste à l’appliquer lors des revues de code pour réduire la portée du travail à l’examen de morceaux de code spécifiques où les risques de défauts sont les plus élevés.
Churn de code
Le churn de code est une visualisation très utile des tendances et des fluctuations qui se produisent dans une base de code à la fois en termes de processus global et de délai avant une publication. Le taux de désabonnement mesure le nombre de lignes de code ajoutées, supprimées ou modifiées. Parfois, les graphiques montrent les trois mesures.
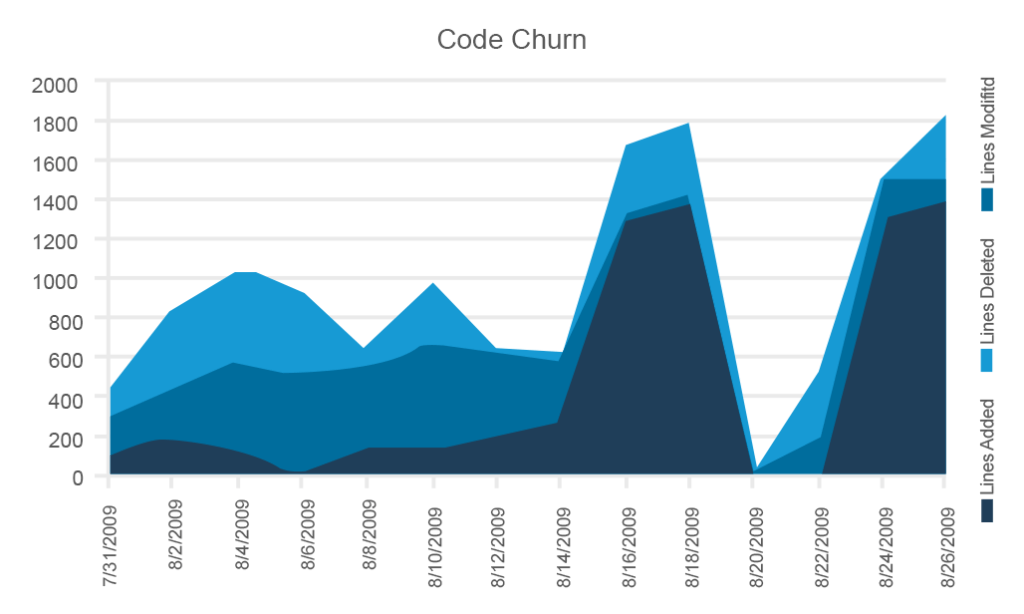
Cet exemple de Microsoft inclut les trois paramètres, mais vous pouvez les utiliser de manière sélective
Bien que le suivi du churn de code puisse sembler une métrique quelque peu primitive, il permet d’évaluer la stabilité du code à différents stades de développement. Vous devez vous attendre à la stabilité la plus faible lors des premiers sprints et à la stabilité la plus élevée – avec le taux de désabonnement le plus bas concomitant – juste avant une sortie. Si votre code est très instable et que la date de sortie approche, sonnez l’alarme.
Cas d’utilisation de désabonnement de code
Recherchez les régularités. Des pics réguliers de modifications de code peuvent révéler que l’approche de génération de tâches n’est pas suffisamment ciblée et produit de nombreuses tâches de grande taille de manière récurrente.
Des pointes irrégulières mais élevées nécessitent une enquête. Si vous avez des pics irréguliers mais puissants dans les changements de code, vous pouvez étudier quelles tâches ont provoqué de tels pics sismiques dans votre code et reconsidérer le niveau de dépendances, surtout si le nombre de nouvelles lignes de code augmentait également le nombre de lignes modifiées.
Faites attention aux tendances. La stabilité de votre produit devient très critique avant une sortie. Comme nous l’avons mentionné, le taux de désabonnement devrait avoir une tendance à la baisse plus votre équipe se rapproche d’une sortie. Une tendance croissante signifie une instabilité possible du produit après une sortie, car il est probable que le nouveau code ne sera pas soumis à des tests suffisants.
Visez le progrès, pas le contrôle
Comme tous les autres indicateurs de performance, les métriques agiles n’ont pas toujours de réponses distinctes ou de conseils exploitables qui scelleront votre succès. Cependant, vous devez utiliser les connaissances qu’ils fournissent pour entamer une discussion, effectuer une évaluation et proposer votre propre plan pour résoudre les problèmes problématiques.
Bien que les métriques fournissent un aperçu numérique de la performance d’une équipe et de la satisfaction globale du travail, ne vous y fixez pas. Étant donné que les métriques agiles ne sont pas standardisées, il est inutile de comparer les succès des différentes équipes. Assurez-vous plutôt d’accepter les commentaires de votre équipe, d’engager des discussions régulières et de nourrir une atmosphère d’objectifs et de soutien communs.