Vous utilisez peut-être des modèles d’arbres depuis longtemps ou un débutant, mais vous êtes-vous déjà demandé comment cela fonctionne réellement et en quoi il est différent des autres algorithmes? Ici, je partage un bref de mes compréhensions.
CART est également un modèle prédictif qui aide à trouver une variable basée sur d’autres variables étiquetées. Pour être plus clair, les modèles d’arbres prédisent le résultat en posant un ensemble de questions if-else. L’utilisation de modèles d’arbres présente deux avantages majeurs,
- Ils sont capables de capturer la non-linéarité dans l’ensemble de données.
- Pas besoin de standardisation des données lors de l’utilisation de modèles arborescents. Parce qu’ils ne calculent aucune distance euclidienne ou d’autres facteurs de mesure entre les données. Juste si – sinon.
Écrous et boulons d’arbres

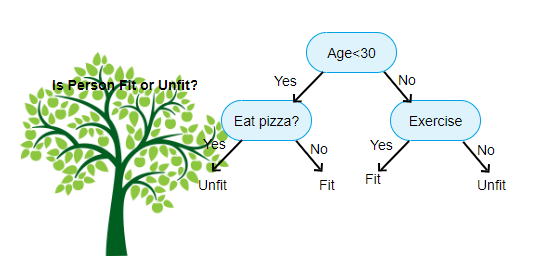
Ci-dessus est une image du classificateur d’arbre de décision, chaque tour est connu sous le nom de nœuds. Chaque nœud aura une clause if-else basée sur une variable étiquetée. Sur la base de cette question, chaque instance d’entrée sera dirigée / acheminée vers un nœud feuille spécifique qui indiquera la prédiction finale. Il existe trois types de nœuds,
- Nœud racine: n’a aucun nœud parent et donne deux nœuds enfants en fonction de la question
- Nœud interne: il aura un nœud parent et donne deux nœuds enfants
- Nœud feuille: il aura également un nœud parent, mais n’aura aucun nœud enfant
Le nombre de niveaux de nous est connu sous le nom de max_depth. Dans le diagramme ci-dessus max_depth=3. À mesure que la profondeur maximale augmente, la complexité du modèle augmente également. Pendant que nous nous entraînons si nous l’augmentons, l’erreur d’entraînement diminuera toujours ou restera la même. Mais cela peut parfois augmenter l’erreur de test. Nous devons donc être exigeants lors de la sélection de la profondeur maximale pour un modèle.
Un autre facteur intéressant sur le nœud est le gain d’informations (IR). C’est un critère utilisé pour mesurer la pureté d’un nœud. La pureté est mesurée en fonction de l’intelligence avec laquelle un nœud peut diviser des éléments. Disons que vous êtes à un nœud et que vous voulez aller à gauche ou à droite. Mais vous avez des éléments appartenant aux deux classes au même montant (50-50) à chaque nœud. Ensuite, la pureté des deux classes est faible car vous ne savez pas quelle direction choisir. L’un doit être plus haut que l’autre pour prendre une décision. ceci est mesuré en utilisant IR,
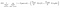

Comme son nom l’indique, le but de CART est de prédire à quelle classe appartient une instance d’entrée en fonction de ses valeurs étiquetées. Pour ce faire, il prendra des régions de décision en utilisant des limites de décision. Imaginez que nous ayons un jeu de données 2D,

comme ceci, il séparera notre jeu de données multidimensionnel en régions de décision en fonction des questions if-else à chaque nœud. Les modèles de CHARIOT peuvent trouver des régions de décision plus précises que les modèles linéaires. Et les régions de décision par CART sont généralement de forme rectangulaire car, une seule caractéristique impliquée à chaque nœud dans la prise de décision. Vous pouvez le visualiser ci-dessous,

Je pense qu’il suffit d’introductions, voyons quelques exemples sur la façon de construire des modèles de PANIER sur Scikit learn.
Arbre de classification
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Arbre de régression
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
J’espère que cet article est utile, si vous avez des discussions ou des suggestions, veuillez laisser une note privée.