Nell’era dei big data, la sfida non è più accedere a dati sufficienti; la sfida è capire i dati giusti da utilizzare. In un articolo passato, mi sono concentrato sul valore dei dati alternativi, che è una risorsa aziendale vitale. Anche con i vantaggi dei dati alternativi, tuttavia, la granularità dei dati errata può compromettere il ROI della gestione basata sui dati.
“Siamo così ossessionati dai dati che ci dimentichiamo come interpretarli”. – Danah Boyd, Ricercatore principale presso Microsoft Research
Così come da vicino si dovrebbe essere guardando i vostri dati? Perché la granularità dei dati sbagliata potrebbe costare più di quanto ti rendi conto.
In poche parole, la granularità dei dati si riferisce al livello di dettaglio dei nostri dati. Più i tuoi dati sono granulari, maggiori sono le informazioni contenute in un particolare punto dati. Misurare le transazioni annuali in tutti i negozi di un paese avrebbe una bassa granularità, poiché si sa molto poco su quando e dove i clienti effettuano tali acquisti. Misurare le transazioni dei singoli negozi dal secondo, d’altra parte, avrebbe una granularità incredibilmente alta.
La granularità dei dati ideale dipende dal tipo di analisi che si sta facendo. Se siete alla ricerca di modelli nel comportamento dei consumatori attraverso decenni, bassa granularità è probabilmente bene. Per automatizzare il rifornimento del negozio, tuttavia, avresti bisogno di dati molto più granulari.
Quando scegli la granularità sbagliata per la tua analisi, finisci con un’intelligenza meno accurata e meno utile. Pensa a quanto sarebbe disordinato il rifornimento settimanale del negozio basato solo su dati annuali a livello di sistema! Si verificano continuamente sia scorte in eccesso che scorte, accumulando enormi costi e alti livelli di rifiuti nel processo. In qualsiasi analisi, la granularità dei dati errata può avere conseguenze altrettanto gravi per l’efficienza e la redditività.
Quindi stai utilizzando la granularità dei dati corretta per la tua business intelligence? Qui ci sono cinque comuni — e costosi-errori di granularità dei dati.
Raggruppamento di più tendenze aziendali in un unico modello (quando i dati non sono abbastanza granulari).
La business intelligence deve essere chiara e semplice per essere attuabile, ma a volte nel tentativo di ottenere semplicità, le persone non si immergono abbastanza in profondità nei dati. È un peccato perché ti perderai preziose intuizioni. Quando la granularità dei dati è troppo bassa, vengono visualizzati solo motivi di grandi dimensioni che si presentano in superficie. Si può perdere i dati critici.
In troppi casi, non guardare abbastanza da vicino i tuoi dati porta a comprimere tendenze disparate in un unico risultato. Le aziende che fanno questo errore finiscono con risultati irregolari. È più probabile che abbiano valori anomali imprevedibili ed estremi che non si adattano al modello generale, perché quel modello non riflette la realtà.
Questo è un problema comune in molti sistemi tradizionali di previsione della supply chain. Non sono in grado di gestire il livello di granularità necessario per prevedere la domanda a livello di SKU nei singoli negozi, il che significa che un singolo negozio può occuparsi contemporaneamente di overstock e stockout. I sistemi automatizzati basati sull’IA sono in grado di gestire la complessità necessaria per segmentare correttamente i dati, motivo per cui migliorano l’efficienza della supply chain. Una granularità dei dati sufficiente è fondamentale per una business intelligence più accurata.

perdersi nei dati senza un punto di messa a fuoco (quando i dati è troppo granulare).
Hai mai accidentalmente ingrandito troppo in una mappa online? È così frustrante! Non puoi distinguere alcuna informazione utile perché non c’è contesto. Ciò accade anche nei dati.
Se i tuoi dati sono troppo granulari, ti perdi; non puoi concentrarti abbastanza per trovare un modello utile all’interno di tutti i dati estranei. Si è tentati di sentire come più dettagli è sempre meglio quando si tratta di dati, ma troppi dettagli possono rendere i dati praticamente inutili. Molti dirigenti di fronte a così tanti dati si ritrovano congelati con la paralisi dell’analisi. Si finisce con raccomandazioni inaffidabili, mancanza di contesto aziendale e confusione inutile.
I dati troppo granulari sono un errore particolarmente costoso quando si tratta di previsioni AI. I dati possono ingannare l’algoritmo a indicare che ha abbastanza dati per fare ipotesi sul futuro che non è possibile con la tecnologia di oggi. Nel mio lavoro di supply chain in Evo, ad esempio, è ancora impossibile prevedere le vendite giornaliere per SKU. Il tuo margine di errore sarà troppo grande per essere utile. Questo livello di granularità mina gli obiettivi e diminuisce il ROI.
Non scegliere la granularità delle variabili temporali intenzionalmente.
Gli errori di granularità dei dati più comuni sono legati agli intervalli di tempo, cioè alla misurazione delle variabili su base oraria, giornaliera, settimanale, annuale, ecc. base. Gli errori di granularità temporale si verificano spesso per motivi di convenienza. La maggior parte delle aziende hanno modi standard per segnalare variabili temporizzate. Sembra che richiederebbe troppo sforzo per cambiarli, quindi non lo fanno. Ma questo raramente è la granularità ideale per affrontare il problema analizzato.
Quando si pesa il costo di cambiare il modo in cui il sistema riporta i KPI rispetto al costo di ottenere costantemente una business intelligence inadeguata, i vantaggi della scelta mirata del registro di granularità giusto. A seconda della granularità del tempo, riconoscerai intuizioni molto diverse dagli stessi dati. Prendi le tendenze della stagionalità nella vendita al dettaglio, per esempio. Guardare le transazioni in un solo giorno potrebbe rendere invisibili le tendenze stagionali o, per lo meno, contenere così tanti dati che i pattern sono solo rumore bianco, mentre i dati mensili condividono una sequenza distinta che puoi effettivamente utilizzare. Se i KPI standard saltano i rapporti mensili per passare direttamente ai modelli trimestrali, si perdono informazioni preziose che renderebbero le previsioni più accurate. Non puoi prendere la granularità del tempo al valore nominale se vuoi ottenere la migliore intelligenza.


l’overfitting o underfitting il tuo modello, al punto che i modelli che vedete sono prive di significato.
I modelli AI devono generalizzare bene dai dati esistenti e futuri per fornire consigli utili. Sostanzialmente un buon modello potrebbe guardare a questi dati:

E assumere questo come un modello di lavoro basato sulle informazioni:

Il modello può non essere perfettamente rappresentativa dati, ma è un buon lavoro per predire il comportamento tipico, senza sacrificare troppo l’intelligenza.
Se non si dispone della granularità dei dati corretta, tuttavia, si può finire con il modello sbagliato. Come abbiamo parlato prima, dati eccessivamente granulari possono causare rumore che rende difficile trovare un modello. Se il tuo algoritmo si allena costantemente con questo livello di dettaglio rumoroso, fornirà rumore a sua volta. Si finisce con un modello che assomiglia a questo:

Noi chiamiamo questo l’overfitting il vostro modello. Ogni punto dati ha un impatto fuori misura, nella misura in cui il modello non può più generalizzare utilmente. I problemi inizialmente causati dall’elevata granularità vengono ingranditi e resi un problema permanente nel modello.
La granularità dei dati troppo bassa può anche danneggiare a lungo termine il modello. Un algoritmo deve disporre di dati sufficienti per trovare i modelli. Algoritmi addestrati utilizzando dati senza granularità sufficiente mancheranno modelli critici. Una volta che l’algoritmo si è spostato oltre la fase di allenamento, continuerà a non riuscire a identificare modelli simili. Si finisce con un modello che assomiglia a questo:
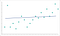
Questo è underfitting il modello. L’algoritmo si avvicina a fare le previsioni giuste, ma non saranno mai così accurate come avrebbero potuto essere. Come l’overfitting, è un ingrandimento del problema di granularità iniziale.
Quando si crea un modello per l’analisi, la granularità corretta diventa esponenzialmente più importante di una volta che si dispone di un algoritmo stabile. Per questo motivo, molte aziende scelgono di esternalizzare questa parte del processo agli esperti. È un palcoscenico troppo delicato e costoso per gli errori.
Regolazione completa della granularità dei dati errati.
Forse l’errore di granularità dei dati più costoso si sta semplicemente concentrando così tanto sull’ottimizzazione della granularità dei KPI che attualmente si misura che non si riesce a rendersi conto che sono completamente i KPI sbagliati. Miriamo a raggiungere la granularità dei dati corretta non per ottimizzare alcuna prestazione specifica di KPI, ma piuttosto per riconoscere i modelli nei dati che forniscono informazioni utili e utili. Se vuoi migliorare le entrate, ad esempio, potresti minare il tuo successo solo guardando i modelli nei prezzi. Altri fattori sono coinvolti.
Prendi un esempio dal mio collega. Un nuovo cliente Evo voleva aumentare le vendite e un test iniziale che applicava i nostri strumenti di Supply chain ha mostrato un miglioramento del 10% in meno di due settimane. Il nostro CEO era oltre eccitato da questi risultati senza precedenti, ma con sua sorpresa, il responsabile della supply chain non è rimasto colpito. Il suo principale KPI era la disponibilità del prodotto, e secondo i numeri interni, che non era mai cambiato. La sua attenzione sul miglioramento di un particolare KPI è venuto a costo di riconoscere preziose intuizioni da altri dati.


Se non KPI è stata misurata con precisione, focalizzato sulla cambiando la sua performance tenutasi questo gestore da vedendo il valore di un nuovo approccio. Era un uomo intelligente che agisce in buona fede, ma i dati lo fuorviato — un errore incredibilmente comune ma costoso. La granularità corretta dei dati è vitale, ma non può essere un obiettivo in sé e per sé. Devi guardare il quadro più ampio per massimizzare i rendimenti da AI. Quanto da vicino si guardano i dati non importa se non si hanno i dati giusti, in primo luogo.
“Un errore comune della gestione basata sui dati è l’utilizzo dei dati errati per rispondere alla domanda giusta”. – Fabrizio Fantini, Fondatore e CEO di Evo
I vantaggi della giusta granularità dei dati
Non c’è nessun magic bullet quando si tratta di granularità dei dati. È necessario scegliere con attenzione e intenzionalmente per evitare questi e altri errori meno comuni. L’unico modo per massimizzare i ritorni dai tuoi dati è guardarli in modo critico, di solito con l’aiuto di un esperto di dati. Probabilmente non otterrai la granularità al primo tentativo, quindi è necessario testare e regolare fino a quando non è perfetto.
Ne vale la pena, però. Guardando da vicino, ma non troppo da vicino, i tuoi dati garantiscono una business intelligence ottimale. Segmentati e analizzati correttamente, i dati si trasformano in un vantaggio competitivo su cui puoi contare.