La perdita MSE viene utilizzata per le attività di regressione. Come suggerisce il nome, questa perdita viene calcolata prendendo la media delle differenze quadrate tra valori effettivi(target) e previsti.
Esempio
Ad esempio, abbiamo una rete neurale che prende i dati della casa e predice il prezzo della casa. In questo caso, è possibile utilizzare la perdita MSE. Fondamentalmente, nel caso in cui l’output sia un numero reale, dovresti usare questa funzione di perdita.
Binary Crossentropy
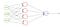
La perdita BCE viene utilizzata per le attività di classificazione binaria. Se si utilizza la funzione di perdita BCE, è sufficiente un nodo di output per classificare i dati in due classi. Il valore di uscita deve essere passato attraverso una funzione di attivazione sigmoid e l’intervallo di uscita è (0 – 1).
Esempio
Ad esempio, abbiamo una rete neurale che prende i dati dell’atmosfera e predice se pioverà o meno. Se l’output è maggiore di 0,5, la rete lo classifica come rain e se l’output è inferiore a 0,5, la rete lo classifica come not rain. (potrebbe essere opposto a seconda di come si allena la rete). Più il valore del punteggio di probabilità, più la possibilità di pioggia.
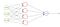
Mentre si allena la rete, il valore target alimentato alla rete dovrebbe essere 1 se piove altrimenti 0.
Nota 1
Una cosa importante, se si utilizza la funzione di perdita BCE l’output del nodo dovrebbe essere compreso tra (0-1). Significa che devi usare una funzione di attivazione sigmoid sul tuo output finale. Poiché sigmoid converte qualsiasi valore reale nell’intervallo tra (0-1).
Nota 2
Cosa succede se non si utilizza l’attivazione sigmoid sul livello finale? Quindi puoi passare un argomento chiamato from logits come true alla funzione loss e applicherà internamente il sigmoid al valore di output.
Crossentropy categoriale
Quando abbiamo un’attività di classificazione multi-classe, una delle funzioni di perdita che puoi andare avanti è questa. Se si utilizza la funzione di perdita CCE, deve esserci lo stesso numero di nodi di output delle classi. E l’output del livello finale dovrebbe essere passato attraverso un’attivazione softmax in modo che ogni nodo emetta un valore di probabilità compreso tra (0-1).
Esempio
Ad esempio, abbiamo una rete neurale che prende un’immagine e la classifica in un gatto o un cane. Se il nodo cat ha un punteggio di probabilità elevata, l’immagine viene classificata in un gatto altrimenti cane. Fondamentalmente, qualunque nodo di classe abbia il punteggio di probabilità più alto, l’immagine viene classificata in quella classe.

Per alimentare il valore target al momento dell’allenamento, dobbiamo codificarli a caldo. Se l’immagine è di gatto, il vettore di destinazione sarebbe (1, 0) e se l’immagine è di cane, il vettore di destinazione sarebbe (0, 1). Fondamentalmente, il vettore di destinazione sarebbe della stessa dimensione del numero di classi e la posizione dell’indice corrispondente alla classe effettiva sarebbe 1 e tutti gli altri sarebbero zero.
Nota
Cosa succede se non si utilizza l’attivazione softmax sul livello finale? Quindi puoi passare un argomento chiamato from logits come true alla funzione loss e applicherà internamente il softmax al valore di output. Come nel caso precedente.
Crossentropy categoriale sparso
Questa funzione di perdita è quasi simile a CCE ad eccezione di una modifica.
Quando si utilizza la funzione di perdita SCCE, non è necessario codificare a caldo il vettore di destinazione. Se l’immagine di destinazione è di un gatto, si passa semplicemente 0, altrimenti 1. Fondamentalmente, qualunque sia la classe, basta passare l’indice di quella classe.