Potresti aver usato modelli ad albero per molto tempo o un principiante, ma ti sei mai chiesto come funziona e come è diverso da altri algoritmi? Qui, condivido una breve delle mie intese.
CART è anche un modello predittivo che aiuta a trovare una variabile basata su altre variabili etichettate. Per essere più chiari, i modelli ad albero prevedono il risultato ponendo una serie di domande if-else. Ci sono due vantaggi principali nell’utilizzo di modelli ad albero,
- Sono in grado di catturare la non linearità nel set di dati.
- Non è necessario standardizzare i dati quando si utilizzano modelli ad albero. Perché non calcolano alcuna distanza euclidea o altri fattori di misurazione tra i dati. Solo se-altro.
Dadi e bulloni di alberi

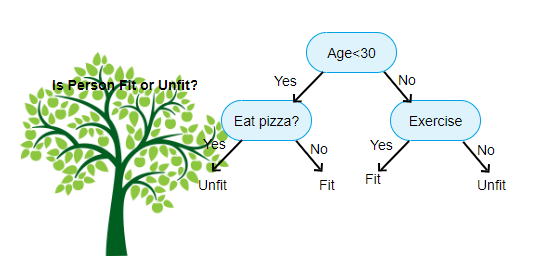
Sopra mostrato è un’immagine del classificatore dell’albero decisionale, ogni round è noto come Nodi. Ogni nodo avrà una clausola if-else basata su una variabile etichettata. Sulla base di questa domanda ogni istanza di input verrà diretta / instradata a uno specifico nodo foglia che dirà la previsione finale. Ci sono tre tipi di nodi,
- il Nodo Radice: non ha alcun nodo padre, e dà due nodi figli in base alla domanda
- Nodo Interno: avrà un nodo padre, e dà due nodi figli
- Nodo Foglia: sarà anche un nodo padre, ma non avere figli nodi
Il numero di livelli di noi è noto come il max_depth. Nel diagramma sopra max_depth = 3. All’aumentare di max_depth, aumenterà anche la complessità del modello. Mentre ci alleniamo se lo aumentiamo, l’errore di allenamento diminuirà sempre o rimarrà lo stesso. Ma a volte può aumentare l’errore di test. Quindi dobbiamo essere esigenti quando selezioniamo il max_depth per un modello.
Un altro fattore interessante sul Nodo è il guadagno di informazioni(IR). Questo è un criterio utilizzato per misurare la purezza di un Nodo. La purezza viene misurata in base a quanto intelligente un nodo può dividere gli elementi. Diciamo che sei in un Nodo e vuoi andare a sinistra oa destra. Ma hai elementi che appartengono a entrambe le classi alla stessa quantità (50-50) in ogni nodo. Quindi la purezza di entrambe le classi è bassa perché non sai quale direzione scegliere. Uno deve essere più alto dell’altro per prendere una decisione. questo è misurato utilizzando IR,
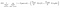

Come dice il nome stesso, l’obiettivo di CART è prevedere a quale classe appartiene un’istanza di input in base ai suoi valori etichettati. Per fare questo farà Regioni decisionali utilizzando i confini decisionali. Immagina di avere un set di dati 2D,

in questo modo, separerà il nostro set di dati multidimensionali in regioni decisionali basate sulle domande if-else su ciascun nodo. I modelli di carrello possono trovare regioni decisionali più accurate rispetto ai modelli lineari. E le regioni decisionali per CARRELLO sono in genere di forma rettangolare perché, solo una caratteristica coinvolta in ogni nodo nel processo decisionale. Si può visualizzare qui sotto,

penso che sia abbastanza di introduzione, vediamo alcuni esempi su come costruire il CARRELLO modelli Scikit imparare.
Albero di classificazione
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Albero di regressione
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Spero che questo articolo sia utile, se avete discussioni o suggerimenti si prega di lasciare una nota privata.