MSE損失は回帰タスクに使用されます。 名前が示すように、この損失は、実際の(目標)値と予測値との間の二乗差の平均を取ることによって計算されます。
例
たとえば、家のデータを取得し、家の価格を予測するニューラルネットワークがあります。 この場合、MSE損失を使用できます。 基本的に、出力が実数の場合は、この損失関数を使用する必要があります。
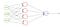
バイナリクロスエントロピー
BCE損失は、バイナリ分類タスクに使用されます。 BCE損失関数を使用している場合は、データを2つのクラスに分類するために1つの出力ノードが必要です。 出力値はシグモイド活性化関数を介して渡され、出力の範囲は(0–1)である必要があります。
例
たとえば、大気データを取得し、雨が降るかどうかを予測するニューラルネットワークがあります。 出力が0.5より大きい場合、ネットワークはそれをrainとして分類し、出力が0.5より小さい場合、ネットワークはそれをnot rainとして分類します。 (それはあなたがネットワークを訓練する方法に応じて反対になる可能性があります)。 確率スコアの値が多いほど、雨の可能性が高くなります。
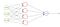
ネットワークを訓練している間、ネットワークに供給される目標値は、雨が降っている場合は1、それ以外の場合は0にする必要があります。
注1
一つの重要なことは、あなたがBCE損失関数を使用している場合、ノードの出力は(0-1)の間にある必要があります。 それはあなたがあなたの最終的な出力でシグモイド活性化関数を使わなければならないことを意味します。 Sigmoidは(0-1)の範囲内の任意の実数値を変換するためです。
注2
最終層でシグモイド活性化を使用していない場合はどうなりますか? 次に、from logitsという引数をtrueとしてloss関数に渡すと、内部的にシグモイドが出力値に適用されます。
カテゴリカルクロスエントロピー
マルチクラス分類タスクがある場合、先に進むことができる損失関数の1つはこれです。 損失関数CCEを使用している場合は、クラスと同じ数の出力ノードが存在する必要があります。 そして、最終的な層出力は、各ノードが(0-1)の間の確率値を出力するように、softmax活性化を通過する必要があります。
例
たとえば、画像を取得してそれを猫や犬に分類するニューラルネットワークがあります。 猫ノードが高い確率スコアを有する場合、画像は、そうでなければ犬の猫に分類される。 基本的に、どのクラスノードが最も高い確率スコアを持っているか、画像はそのクラスに分類されます。

トレーニング時の目標値を供給するためには、それらをワンホットエンコードする必要があります。 画像がcatの場合、ターゲットベクトルは(1、0)になり、画像がdogの場合、ターゲットベクトルは(0、1)になります。 基本的に、ターゲットベクトルはクラス数と同じサイズになり、実際のクラスに対応するインデックス位置は1になり、他のすべてはゼロになります。
注
最終層でsoftmaxアクティベーションを使用していない場合はどうなりますか? 次に、from logitsという引数をtrueとしてloss関数に渡すと、出力値にsoftmaxが内部的に適用されます。 上記の場合と同じです。
Sparse Categorical Crossentropy
この損失関数は、一つの変更を除いてCCEとほぼ似ています。
SCCE損失関数を使用している場合、ターゲットベクトルをホットエンコードする必要はありません。 ターゲット画像が猫の場合は、単に0を渡し、それ以外の場合は1を渡します。 基本的には、どちらのクラスでも、そのクラスのインデックスを渡すだけです。