あなたは長い間、または初心者のためのツリーモデルを使用している可能性がありますが、あなたは今までそれが実際にどのように動作し、それ ここで、私は私の理解の簡単なものを共有しています。
CARTは、他のラベル付き変数に基づいて変数を見つけるのに役立つ予測モデルでもあります。 より明確にするために、ツリーモデルはif-else質問のセットを尋ねることによって結果を予測します。 ツリーモデルの使用には、主に2つの利点があります。,
- 彼らは、データセット内の非線形性をキャプチャすることができます。
- ツリーモデルを使用するときにデータを標準化する必要はありません。 彼らはデータ間のユークリッド距離やその他の測定因子を計算しないからです。 ちょうどif-else。

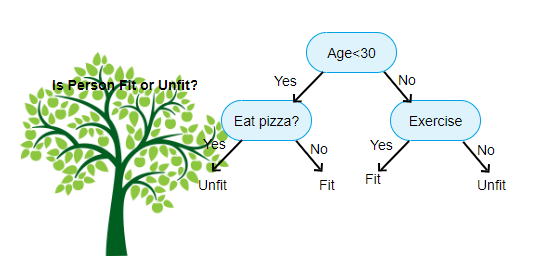
上に示されているのは、決定木分類器の画像であり、各ラウンドはノードとして知られています。 各ノードには、ラベル付き変数に基づいたif-else節があります。 その質問に基づいて、入力の各インスタンスは、最終的な予測を伝える特定のリーフノードに向けられ/ルーティングされます。 ノードには3つのタイプがあります,
- ルートノード:親ノードを持たず、質問に基づいて二つの子ノードを与えます
- 内部ノード:親ノードを持ち、二つの子ノードを与えます
- リーフノード:親ノードも持っていますが、子ノードはありません
私たちが持っているレベルの数はmax_depthとして知られています。 上の図では、max_depth=3です。 Max_depthが増加すると、モデルの複雑さも増加します。 私たちがそれを増やすと訓練している間、訓練エラーは常に下がるか、同じままになります。 しかし、それは時々テストエラーを増加させる可能性があります。 したがって、モデルのmax_depthを選択するときは、選択する必要があります。
ノードに関するもう一つの興味深い要因は情報利得(IR)です。 これは、ノードの純度を測定するために使用される基準です。 純度は、ノードがアイテムをどのように巧妙に分割できるかに基づいて測定されます。 あなたがノードにいて、左または右のいずれかに行きたいとしましょう。 しかし、各ノードで同じ量(50-50)の両方のクラスに属しているアイテムがあります。 どちらの方向を選択するかわからないため、両方のクラスの純度は低くなります。 決定を下すには、一方が他方よりも高くなければなりません。 これはIRを使用して測定されます,
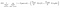

名前自体が言うように、CARTの目標は、ラベルされた値に基づいて入力インスタンスが属するクラスを予測することです。 これを達成するために、決定境界を使用して決定領域を作成します。 2Dデータセットがあるとします,

このように、各ノードのif-else質問に基づいて多次元データセットを決定領域に分離します。 CARTモデルは、線形モデルよりも正確な決定領域を見つけることができます。 そして、カートによる意思決定領域は、意思決定に各ノードに関与する唯一の特徴であるため、典型的には長方形である。 あなたはそれを以下に視覚化することができます,

紹介で十分だと思いますが、Scikit learnでカートモデルを構築する方法の例をいくつか見てみましょう。
分類ツリー
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
回帰ツリー
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
この記事が役に立つことを願っています。