카트는 다른 레이블이 지정된 변수를 기반으로 변수를 찾는 데 도움이되는 예측 모델이기도합니다. 더 명확하게하기 위해 트리 모델은 일련의 다른 질문을함으로써 결과를 예측합니다. 트리 모델을 사용할 때 두 가지 주요 이점이 있습니다,
- 데이터 집합에서 비선형성을 캡처할 수 있습니다.
- 트리 모델을 사용할 때 데이터를 표준화 할 필요가 없습니다. 그들은 데이터 사이의 유클리드 거리 또는 기타 측정 요인을 계산하지 않기 때문입니다. 그냥 경우-다른.
나무 볼트와 너트

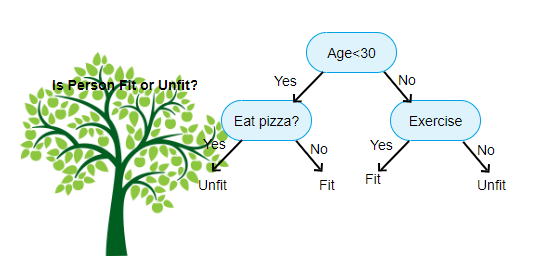
위의 그림은 의사 결정 트리 분류 자의 이미지이며 각 라운드는 노드라고합니다. 각 노드는 레이블이 지정된 변수를 기반으로 다른 경우 절을 갖습니다. 이 질문에 따라 각 입력 인스턴스는 최종 예측을 알려주는 특정 리프 노드로 이동/라우팅됩니다. 노드의 세 가지 유형이 있습니다,
- 루트 노드:어떤 부모 노드가없는,그리고 질문에 따라 두 개의 자식 노드를 제공합니다
- 내부 노드:그것은 부모 노드를해야합니다,두 개의 자식 노드를 제공합니다
- 리프 노드:그것은 또한 부모 노드를해야합니다,하지만 자식 노드가 없습니다
우리가 가지고있는 수준의 수는 최대 깊이로 알려져있다. 위의 다이어그램에서 최대 깊이=3. 최대 깊이가 증가함에 따라 모델 복잡도 또한 증가합니다. 우리가 그것을 증가하는 경우에 우리가 훈련하는 동안,훈련 과실은 항상 내려갈 것이다 또는 동일에 남아 있을 것이다. 그러나 때때로 테스트 오류를 증가시킬 수 있습니다. 그래서 우리는 모델에 대한 최대 깊이를 선택할 때 까다로워해야합니다.
노드에 대한 또 다른 흥미로운 요소는 정보 이득(적외선)입니다. 이 노드의 순도를 측정하는 데 사용되는 기준이다. 순도는 노드가 항목을 얼마나 영리하게 분할할 수 있는지에 따라 측정됩니다. 당신이 노드에 있고 왼쪽 또는 오른쪽으로 가고 싶다고 가정 해 봅시다. 그러나 각 노드에서 동일한 양(50-50)의 두 클래스에 속하는 항목이 있습니다. 그렇다면 두 클래스의 순도는 어느 방향을 선택해야할지 모르기 때문에 낮습니다. 하나는 결정을 내리기 위해 다른 것보다 높아야합니다. 이것은 적외선을 사용하여 측정됩니다,
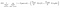

이름 자체가 말했듯이 카트의 목표는 레이블이 지정된 값을 기반으로 입력 인스턴스가 속한 클래스를 예측하는 것입니다. 이를 위해 의사 결정 경계를 사용하여 의사 결정 영역을 만들 것입니다. 우리가 2 차원 데이터 세트를 가지고 있다고 상상해 보세요,


분류 트리
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
회귀 트리
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
이 기사가 유용하기를 바랍니다.