Lesetid: 13 minutter
den smidige tilnærmingen til programvareutvikling har lenge vært en vanlig praksis. IFØLGE HPS online-undersøkelse velger 16 prosent av IT-profesjonelle pure agile, 51 prosent lener seg mot it og 24 prosent bruker en agile hybrid-tilnærming. I dag nevnes fossutvikling oftest som en smidig differensiator, hvilken smidig er det ikke. Vi har bredt diskutert de viktigste forskjellene i vår whitepaper på agile prosjektledelse metoder.
til tross for tilpasningsevnen og fleksibiliteten til smidig administrasjon og rask respons på endringer, kan arbeidsflyten forbli sentralisert og kontrollert. Agile Kpier (key performance Indicators) gir veiledning for strategisk planlegging, evaluering og forbedring av operasjonelle prosesser.
Tradisjonelle verdistyringssystemer har en tendens til å fokusere på oppgavefullføring innenfor rammen av kategorisk tidsplan og kostnad. Men med agile ser kunder og teammedlemmer umiddelbare resultater og justerer tidsrammer og innsats for å levere et produkt som tilsvarer tidsplanskravene. Hvilke verktøy og teknikker krever slik kunnskap? Her er vår oversikt over agile development metrics performance assessment.
Agile software development Kpier
I denne artikkelen skal vi ikke utforske alle mulige agile development metrics og Kpier. På toppen av det kan du oppfinne dine egne som passer best til prosjektet ditt. Vi vil imidlertid beskrive de vanligste Kpi-ene som brukes på tvers av flere programvareutviklingsaspekter:
- Hastighet
- sprint burndown
- slipp burndown
- Syklustid
- Kumulativ strømning
- Strømningseffektivitet
- Kodedekning ved automatiserte tester
- testautomatisering mot manuell testing
- mccabe cyclomatic kompleksitet (mcc)
- kode churn
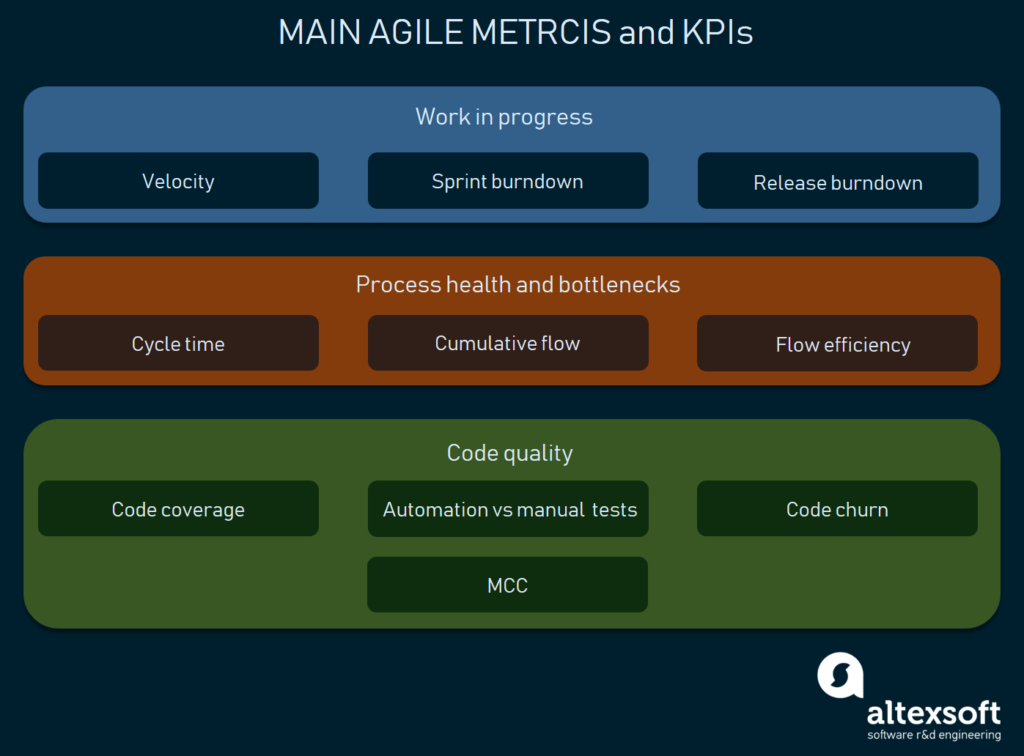
dette er de viktigste som du må utforske først
Måle arbeid pågår
Velocity
Velocity måler mengden arbeid (en rekke funksjoner) fullført i en sprint. Selv om det ikke er et prediksjons-eller sammenligningsverktøy, gir velocity lag en ide om hvor mye arbeid som kan gjøres i neste sprint.
Velocity index er unik for hvert lag og bør settes til å vurdere hvor realistisk engasjementet er. For eksempel, hvis prosjektet backlog har 200 historien poeng og i gjennomsnitt teamet fullfører 10 historien poeng per sprint, betyr det at teamet vil kreve ca 20 sprints å fullføre prosjektet.
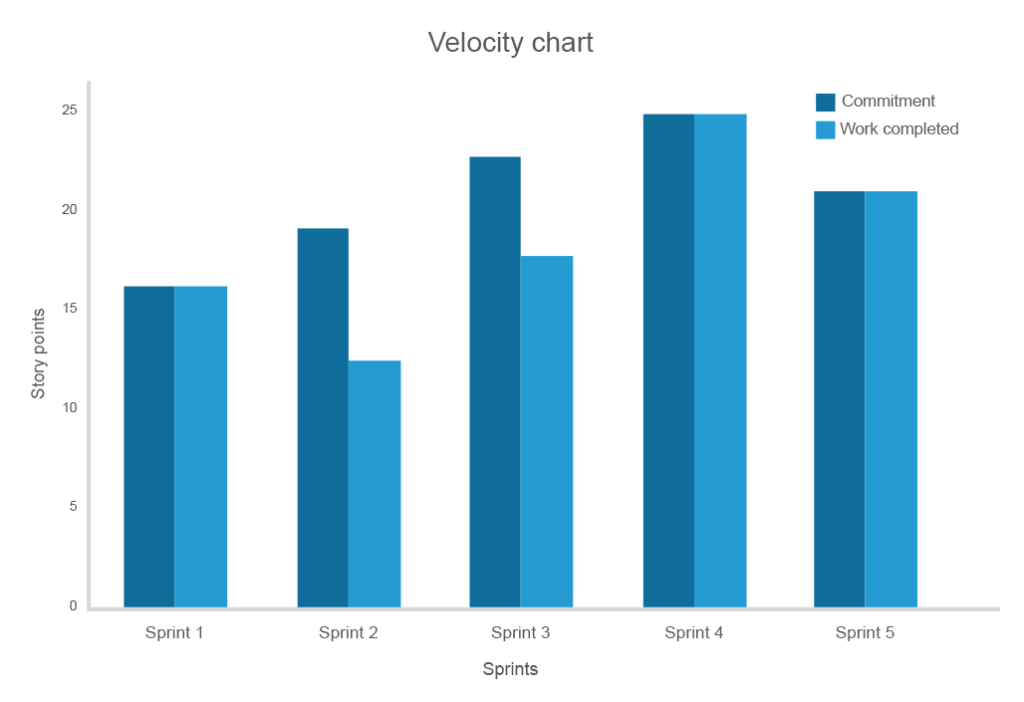
jo lenger du sporer hastigheten, desto høyere er nøyaktigheten av korrespondansen mellom forpliktelser og kostnader
For et lag som nettopp har vedtatt agile-metoden eller til og med startet et nytt produkt, vil hastighetsestimatene for de første sprintene trolig være uberegnelige. Men etter hvert som lagene får erfaring, vil hastigheten toppe og nå et platå med forutsigbar flyt og forventet ytelse. En nedgang i konsekvent flyt vil indikere problemer i utviklingen og avsløre behovet for endring.
Tips for bruk av hastighetsmålingen
Bekjempe inkonsekvens etter 3-5 spurter. Hvis hastigheten forblir inkonsekvent etter en lang periode, bør du vurdere å vurdere både eksterne og interne faktorer som forhindrer klar estimering.
Endre hastighetssporingen etter team-og oppgaveendringer. Når et teammedlem forlater prosjektet eller flere medlemmer/oppgaver er lagt til, beregne hastighet eller starte beregningen helt.
Tre spurter er nok for tidlige prognoser. For å forutsi fremtidig ytelse, bruk gjennomsnittet av de tre foregående spurtene.
sprint burndown chart
sprint burndown chart viser hvor mye arbeid som gjenstår før slutten av en sprint. Verktøyet er spesielt verdifullt fordi det viser fremdriften mot målet i stedet for å notere fullførte elementer. Det er også veldig nyttig å avdekke planleggingsfeil som et lag gjorde i begynnelsen av en sprint.
på diagrammet under representerer den svarte linjen den forventede (ideelle trend) linjen som viser i hvilken hastighet laget trenger å brenne ned historikkpoeng for å fullføre sprinten i tide. Den blå linjen indikerer den totale mengden arbeid og fremdriften gjennom sprinten. Du kan se at i løpet av dagene fem og seks, klarte ikke ett lag å oppnå den forventede fremgangen. Men på dag syv ble problemet løst og arbeidet var tilbake på sporet. Slike løpende oppdateringer tillater team å løse nye problemer under daglige stand-up møter.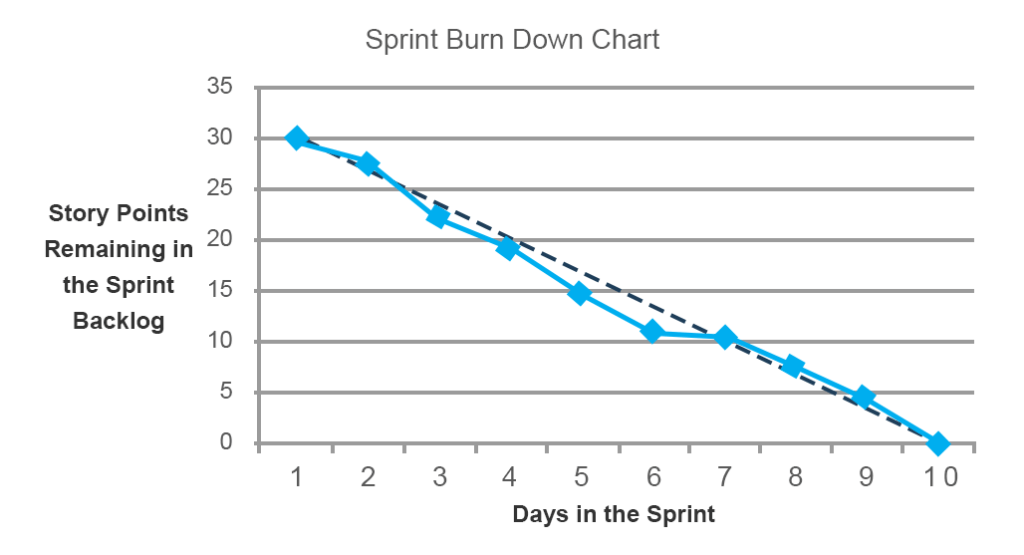
Foruten arbeidet ytelse selv, burndown diagrammer kan avsløre planlegging problemer
Tips for å nærme sprint burndown
Story poeng bør være enda i omfang. Hvis arbeidsflyten ikke er konsekvent, kan enkelte oppgaver ha blitt brutt ned i ujevne biter. Omfanget av avvik mellom en ideell trend og virkeligheten fremhever dette problemet tydelig.
Konto for ikke-planlagte oppgaver. Burndown-diagrammet er nyttig for å forstå omfanget av skjulte og usporede oppgaver. Hvis mengden arbeid øker i stedet for å redusere, har prosjektet mange ikke-estimerte eller ikke-planlagte oppgaver som skal løses.
Bruk et burndown-diagram for å vurdere lagets tillit. Med tanke på dagens priser, spør teamet ditt hvor trygg de er om å fullføre sprinten i tide. Jo lenger du bruker denne beregningen, desto mer nøyaktige er sprintestimatene dine.
Estimere utgivelsen med et burndown-diagram
et burndown-diagram angir hvor mye arbeid som må fullføres før en utgivelse. Diagrammet illustrerer fremdriftsoversikten og lar deg implementere endringer for å sikre levering til rett tid.
en tradisjonell versjon av diagrammet ligner sprint burndown-diagrammet, men gir en oversikt over hele prosjektet der y-aksen er spurter og x-aksen er et mål på gjenværende arbeid (dager, timer eller historiepoeng). Men hva om mer arbeid legges til prosjektet eller ditt estimerte arbeid ikke oppfyller forventningene?
på diagrammet nedenfor planla et team å fullføre et prosjekt i fire spurter og hadde i utgangspunktet 45 historiepoeng. Mens fremdriften gikk som planlagt i løpet av første og andre sprint, økte det estimerte arbeidet ved tredje sprint, noe som reflekteres på y-aksen i negative verdier. Under den tredje sprinten oppstod 5 nye historiepoeng. De ble ikke fullført, og den fjerde sprint lagt til en annen 5 historie poeng. Derfor måtte fremdriften og utgivelsestiden justeres.
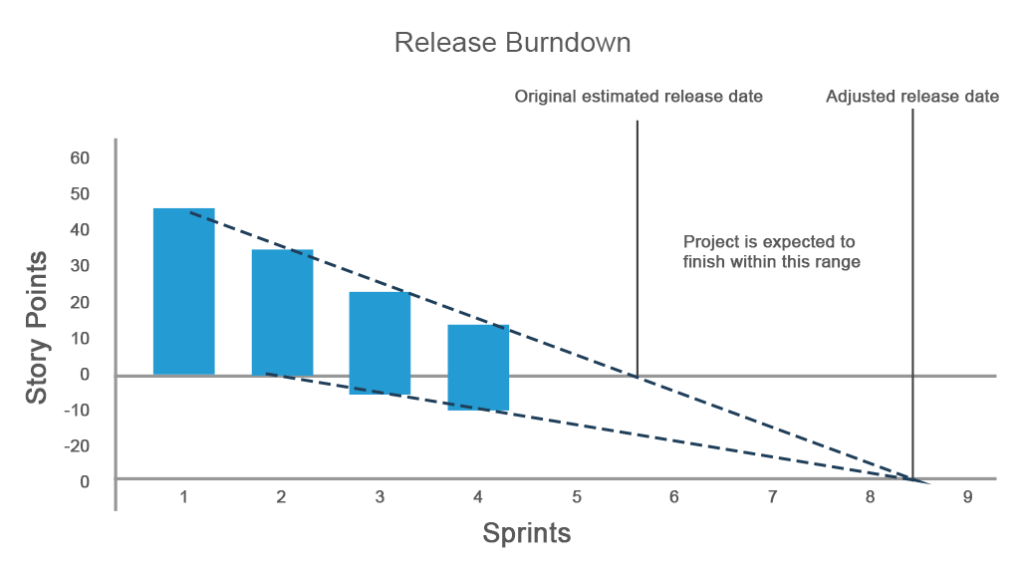
release burndown chart er super effektivt for situasjoner med mange endrede krav og lar et lag holde seg på sporet under hver sprint
Hvordan kan release burndown chart hjelpe?
real-time prediksjon på utgivelsen. Når prosjektet gjennomgår endringer, som skjer hver gang med iterativt utvikling av produkter, må du se hvordan disse endringene påvirker utgivelsesdatoen. Utgivelsen burndown chart gjør det mulig å forutsi utgivelsesdatoen i sanntid i henhold til oppdateringer i arbeidsomfanget.
Tidsfrist spådommer. Du kan anslå om teamet kan fullføre en produktutgivelse i tide eller forutse at fristen skal gå videre med tanke på ekstra oppgaver.
Estimering av antall sprint. Vurdere hvor mange spurter er nødvendig for å fullføre arbeidet er også en viktig faktor å vurdere med utgivelsen burndown diagram.
Vurdere prosesshelse og finne flaskehalser
Syklustid
syklustidmetrikken beskriver hvor mye tid som ble brukt på en oppgave, inkludert hver gang arbeidet måtte gjenåpnes og fullføres på nytt. Beregning av syklustiden gir informasjon om den generelle ytelsen og gjør det mulig å estimere ferdigstillelse av fremtidige oppgaver. Mens kortere syklustid illustrerer bedre ytelse, er lagene som leverer innenfor en konsistent syklus verdsatt mest.
ved hjelp av diagrammet nedenfor kan du identifisere den gjennomsnittlige tiden det tar å fullføre en aktivitet, tegne en median-eller kontrollgrenselinje som ikke bør krysses, og legge merke til hvilke aktiviteter som tok uvanlig lang tid å fullføre.
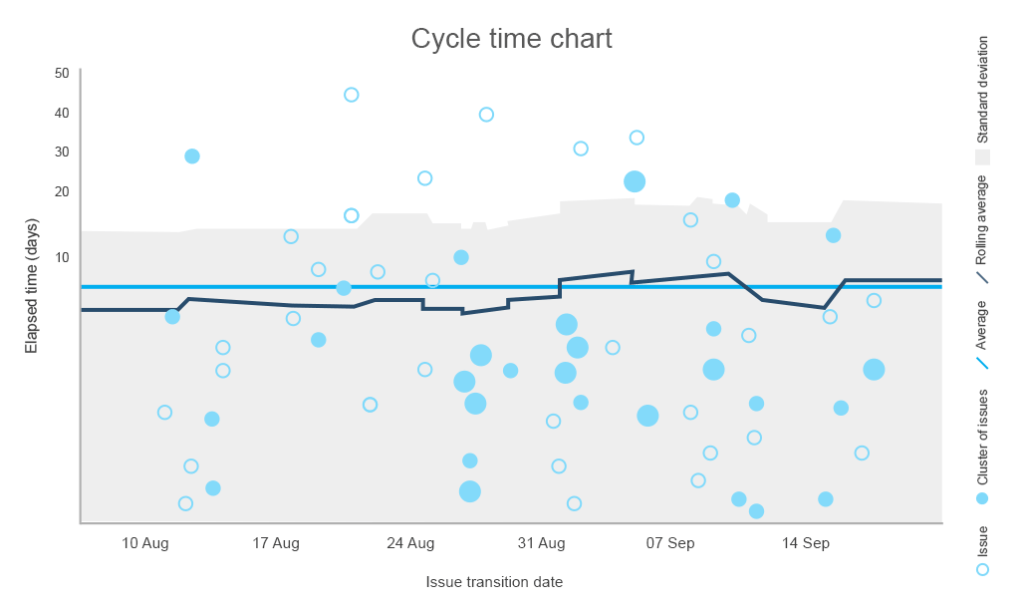
standardavviket trekker en linje mellom normal og ikke anbefalt antall dager for å fullføre oppgaven
du kan også stable alle sykluser for en bestemt periode og trekke innsikt fra å sammenligne den med andre data. Ved å gjennomføre en videre undersøkelse kan du trekke konklusjoner om kvaliteten på arbeidet.
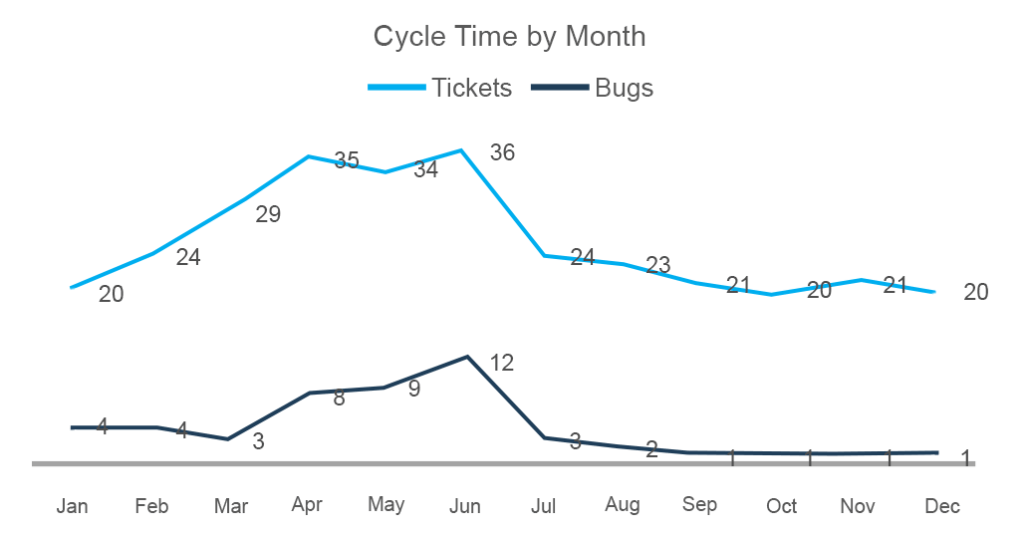
Her kan du se at antall fullførte oppgaver Fra Mars til juni har vokst som gjorde antall feil
hvordan bruke syklus tid
Se etter likheter. En god praksis er å finne lignende elementer som tar uforutsigbare syklustider å fullføre, og avslører gjentatte problemer, enten i ingeniørfag eller ledelse.
Tegn spådommer. Du kan ta datadrevne beslutninger ved å forutsi tiden for å fullføre nye oppgaver basert på lignende fra fortiden.
Spor tempoet. Diagrammet beskriver hvordan du holder samme tempo i arbeidet og definerer om det er interne problemer som reduserer arbeidets hastighet.
Kumulativt Flytdiagram (CFC)
den kumulative flytmetrikken er beskrevet av diagramområdet som viser antall forskjellige typer aktiviteter i hvert trinn i prosjektet med x-aksen som angir datoene og y-aksen som viser antall artikkelpunkter. Hovedmålet er å gi en enkel visualisering av hvordan oppgaver distribueres på ulike stadier. Linjene på diagrammet bør bo mer eller mindre selv mens bandet med «ferdig» oppgaver skal vokse kontinuerlig.
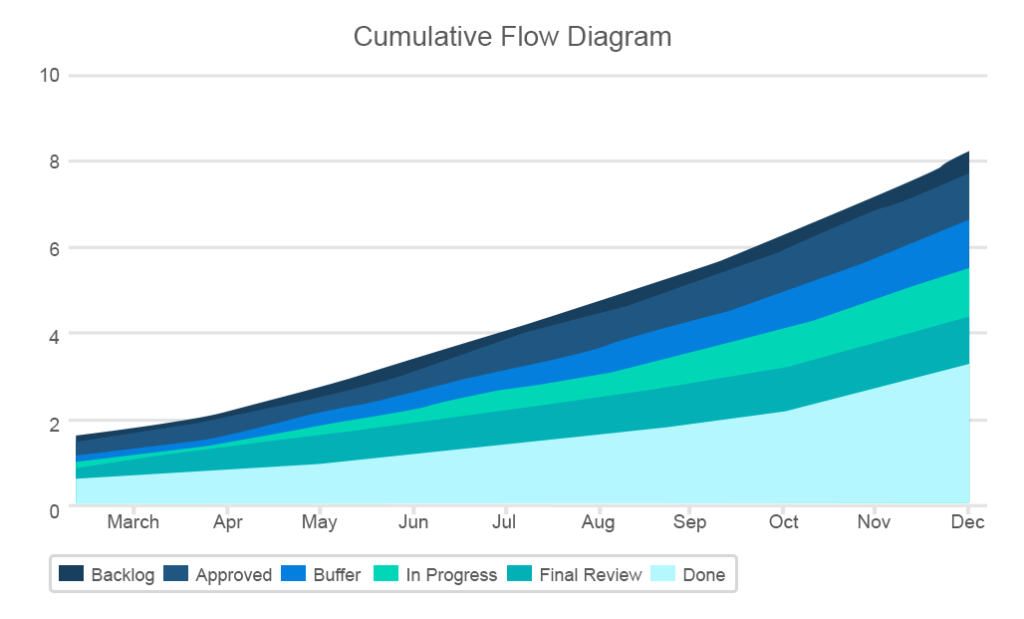
diagrammet avslører mye kritisk informasjon som plutselige flaskehalser eller stiger i noen av bandene
CFC vil være til stor nytte For kanban-lag som en enkel visualisering av lagets arbeid. Diagrammet samsvarer også Med Kanbans tre-trinns arbeidsflyt. Her kan du også kartlegge tre viktigste oppgave kategorier: gjøremål, pågår, og fullført.
videre hjelper diagrammet med å identifisere når GRENSENE for ARBEID i fremgang (VIA) overskrides. Å være et av de mest verdifulle verktøyene i smidig utvikling, er WIP limits ment å dyrke kulturen for etterbehandling og eliminere multitasking ved å sette maksimal mengde arbeid for hver prosjektstatus.
Hvilke problemer er påpekt AV CFC?
- Tilbakeslagsvekst indikerer de uløste oppgavene som enten er for lav prioritet til å takle for øyeblikket eller er foreldet
- Inkonsekvent flyt og plutselige flaskehalser indikerer hvilke områder som skal glattes ut i de senere stadiene
- bredden på hvert bånd viser gjennomsnittlig syklustid
- den betydelige utvidelsen av «pågår» – området kan bety at laget ikke vil kunne fullfør hele prosjektet i tide
strømningseffektivitet
strømningseffektivitet er en veldig nyttig metrisk i kanban-utvikling, for Det meste oversett Av Utvikling team. Mens flyteffektivitet utfyller kumulativ flyt, gir den innsikt i fordelingen mellom faktisk arbeid og venteperioder. Det er et sjeldent tilfelle når en utvikler jobber på en ting om gangen uten å vente. Virkeligheten er vanligvis mer kompleks. Og «work-in-progress» er et navn som ikke alltid samsvarer med status.
koden kan for eksempel ha mange avhengigheter, og du kan ikke begynne å jobbe med en funksjon før en annen er ferdig, eller prioriteringene endres, eller du venter på godkjenning fra en interessent. Å måle hvor mye tid du venter mot arbeid kan være enda mer nyttig enn å effektivisere prosesser knyttet til faktisk arbeid.
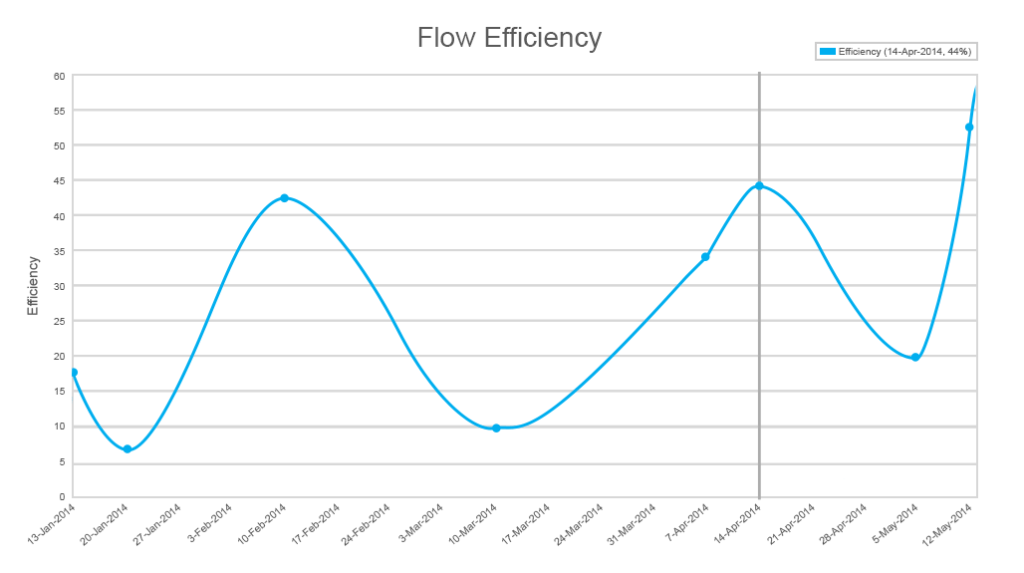
ved å se på de laveste effektivitetsindikatorene, kan du forstå de viktigste flaskehalsene
Hvordan du bruker strømningseffektivitet
Beregningsformel. Med mindre du bruker noen prosjektstyringsprogramvare som inneholder disse beregningene, kan du beregne flyteffektivitet med Denne enkle formelen: Arbeid / (arbeid+vent) * 100%. Deretter kan du visualisere det digitalt eller til og med tegne grafen på tavlen på kontoret.
Definer din normale strømningseffektivitet. Som med alle andre beregninger er det umulig å kreve normale tall for alle prosjekter. Noen sier at 15 prosent-merket er greit for de fleste prosjekter, noe som i utgangspunktet betyr at et historiepunkt eller et annet arbeid venter 85 prosent mot 15 prosent behandlingstid. David J. Anderson, en ledelsesekspert Fra LeanKanban School Of Management, antyder at 40 prosent og høyere bør være målet for de fleste lag.
Dekomponere detaljer om arbeidet før fikse flyt effektivitet. Diagrammet vil tillate visning av nøyaktige tidsperioder når effektiviteten din var den laveste. Og disse dataene må analyseres veldig nøye, da den virkelige årsaken og dens rette ikke blir avslørt så lett. Før du starter intensive handlinger, gjør en grundig undersøkelse av årsaker.
Øk strømningseffektiviteten med blokkeringsanalyse. En god måte å realisere det forrige punktet på er å øke strømningseffektiviteten din med blocker clustering analysis. Hvis noe arbeid er blokkert, fortjener det et farget klistremerke eller en annen form for visuelt signal for å bringe disse blokkene til lagets oppmerksomhet, slik at de kan reagere på dem.
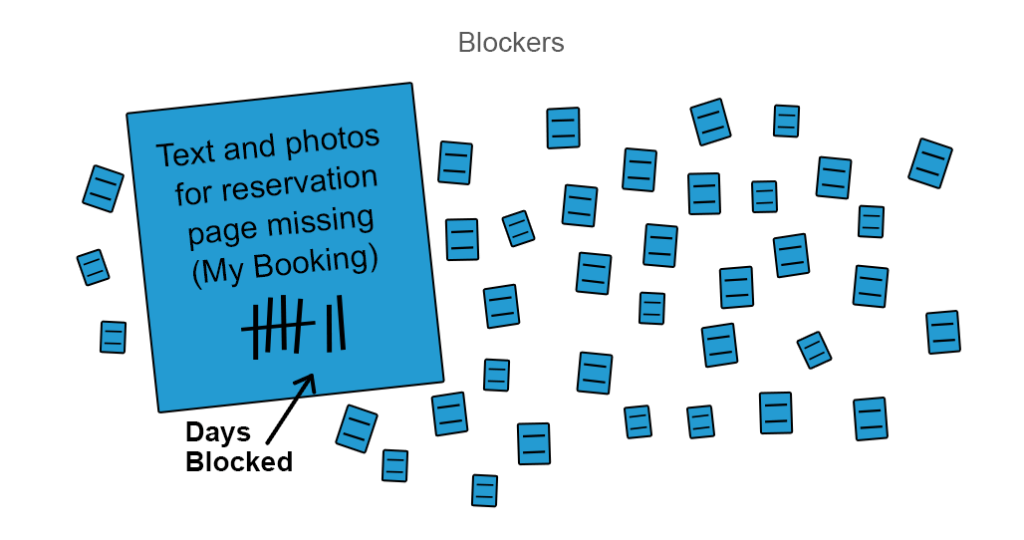
du kan merke hvor mange dager noe av arbeidet er blokkert og prioritere oppløsningen
vanligvis akkumuleres blokkere i klynger da de har mange avhengigheter med hverandre. Bedre blokkering analyse kan gjøres hvis du clusterize dem fra høyt nivå likheter som interne og eksterne blokkere og deretter spesifisere videre ved design, manglende innhold, eller andre mangler funksjoner. Blocker analyse er en enkel måte å undersøke dalene i flyt effektivitet.
Måling av kodekvalitet
Kodedekning
Kodedekning definerer hvor mange linjer med kode eller blokker som utføres mens automatiserte tester kjører. Kodedekning er en kritisk beregning for testdrevet utvikling (tdd) praksis og kontinuerlig levering. Tradisjonelt tolkes metriske med en enkel tilnærming: jo høyere kodedekning, desto bedre. For å måle dette trenger du et av de tilgjengelige verktøyene som Coveralls. Men de fungerer ganske mye det samme: når du kjører tester, vil verktøyet oppdage hvilken av kodelinjene som kalles minst en gang. Prosentandelen av kalt linjer er koden din dekning.
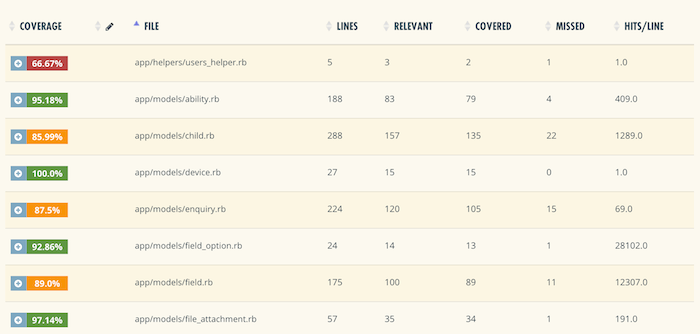

Kjeledresser, for eksempel, vil bryte ned koden dekning til hver fil måling og markere dekket og avdekket linjer
hvordan bruke kode dekning
Fokus på avdekket linjer og ikke overvurdere de dekket seg. Hvis kodelinjen kalles en gang eller enda mer, betyr det ikke nødvendigvis at funksjonen den støtter fungerer perfekt, og brukerne vil bli fornøyd. Å ringe en kodelinje er ikke alltid tilstrekkelig til å lukke testoppgaven. På den annen side viser prosentandelen av avdekkede linjer hva som ikke er dekket i det hele tatt, og kan fortjene testing.
Prioriter dekket kode og ikke sikte på 100 prosent. Selv om dette virker counterintuitive, betyr ikke 100 prosent dekning at du har riktig testet kode. Prosjektet ditt har koden som betyr noe og resten av en kodebase. Da testautomatisering vanligvis er et dyrt initiativ, bør det prioritere funksjonene og tilhørende biter av kode.
testautomatisering mot manuell testing
denne målingen definerer hvor mange linjer med kode i en funksjon som allerede er dekket med automatiserte tester mot de som testes manuelt. Dette følger direkte den forrige metriske, men har en bestemt brukstilfelle. Testautomatisering andel mot manuell testing brukes bare når du kritisk trenger automatisering for å dekke regresjoner. Regresjonstesting er gjort for å sjekke om noe ble ødelagt etter funksjonsoppdateringer. Og hvis produktet gjennomgår stadige forbedringer-som det bør-testing for regresjon bør automatiseres. Hvis det ikke er det, må de manuelle QA-spesialistene gjenta de samme testscenariene gjentatte ganger etter hver oppdatering.
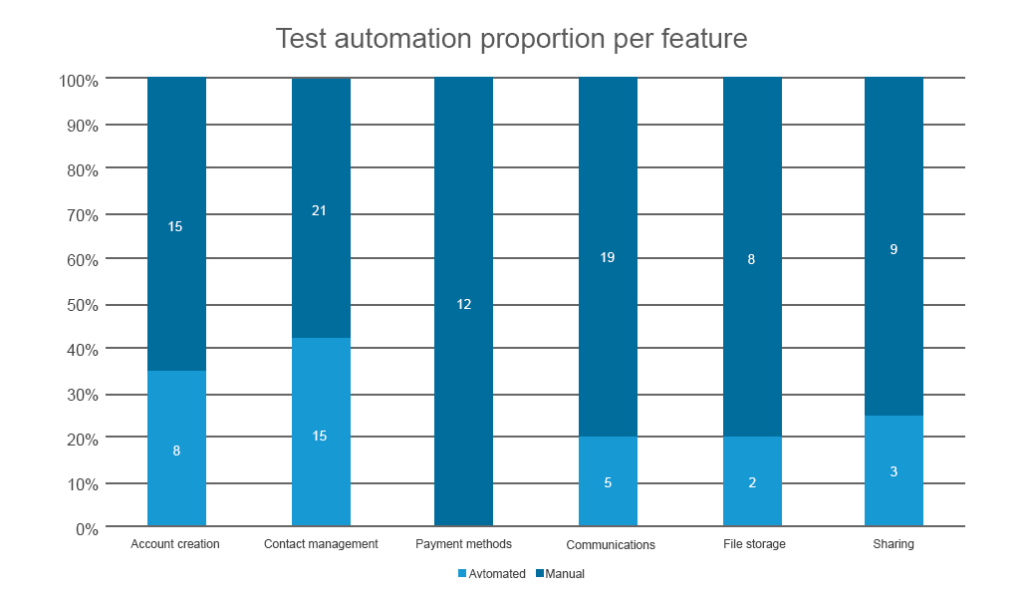
Du kan bruke de samme instrumentene som brukes til kodedekning for å tegne denne metriske
Som Beskriver den automatiserte testdekningen per funksjon, lar deg prioritere funksjonene som 1) kan lide av regresjon etter oppdateringer, og 2) for hvilke automatiserte tester er kritiske. Vanligvis har du ikke nok tid og menneskelige ressurser til å dekke alt ved automatiserte tester samtidig, med mindre du jobber innenfor det testdrevne utviklingsrammeverket. Så det er bedre å prioritere funksjonene som er sikker på å påvirke brukeropplevelsen.
McCabe Cyclomatic Complexity (MCC) med kode
kodekompleksmålinger brukes til å vurdere risikoen for problemer under kodetesting og vedlikehold. Jo høyere kodens kompleksitet, desto vanskeligere blir det å sikre at det har et akseptabelt antall feil og holder høy vedlikeholdsevne. Den vanligste tilnærmingen til å måle kodekompleksitet er McCabe Cyclomatic Complexity Metric (MCC). En av formlene for å tegne kompleksitetsresultater FOR MCC er følgende:
MCC = kanter-noder + retur setninger
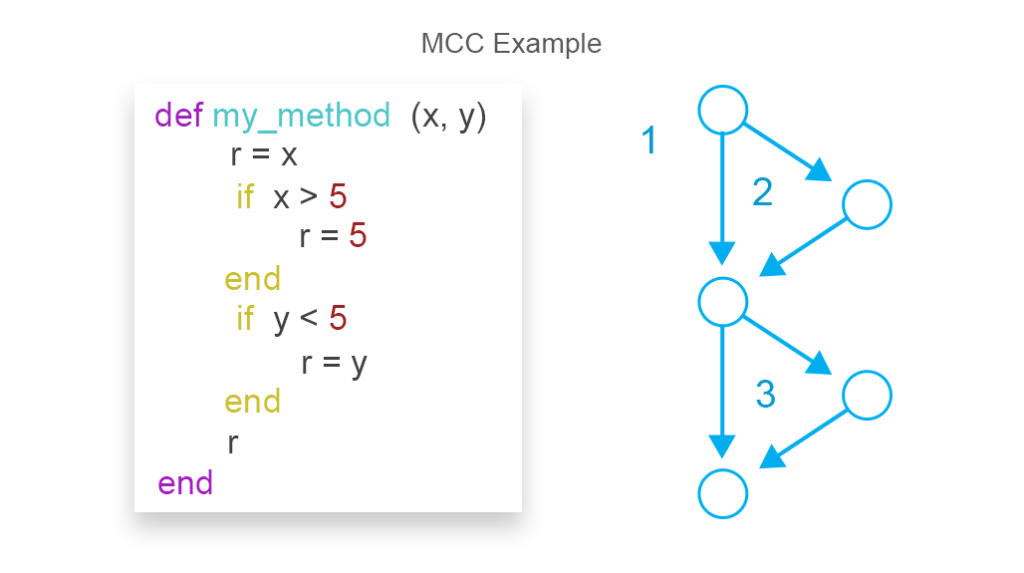
MCC på bildet er lik 3
med denne metriske, utviklere er ikke estimere sin kode kompleksitet ved subjektivt å se på det. Som ingeniører ferdigheter varierer, varierer deres vurderinger som gjør kode refactoring eller fikse bugs mer utfordrende på lengre sikt. DET er mange MCC måleverktøy på markedet som kan kombineres med andre kode kompleksitet beregninger som dybden av koden hierarki og antall kodelinjer.
MCC bruk detaljer og fallgruver
Balansere menneskelig og maskin oppfatning av kode kompleksitet. EN av hovedgrunnene til Å bruke MCC er å gjøre kode lesbar for andre utviklere. Lesbarheten av kode reduserer risikoen for langsiktig onboarding av nye utviklere som må håndtere eldre kode. Det vil også forenkle refactoring nedover veien. Problemet her er AT MCC-modellen kan vurdere noen komplekse, men lesbare metoder uakseptable. Og hvis du tvinger en utvikler til å refactor komplekse metoder i mange delmetoder, kan Du oppnå de motsatte resultatene: Mange metoder med enkle logikker kan bli enda vanskeligere å forstå for et menneske enn en enkelt, men kompleks metode.
IKKE gjør MCC til en restriktiv beregning. Noen organisasjoner praktiserer avslutningskode som ikke består MCC-testen. Selv om dette potensielt kan øke kodenes enkelhet, er det naturlig å ha kompleks kode på nivåene av klasser, metoder og funksjoner. Å blokkere dem helt er ikke alltid gunstig. En god praksis er å sette generell kode kompleksitet KPI for utviklere, som vil oppmuntre dem til å nærme koding mer bevisst og tenke på enkelhet.
Bruk MCC for kodegjennomgang. EN annen verdifull praksis FOR MCC-tester er å bruke DEN under kodevurderinger for å begrense omfanget av arbeidet med å gjennomgå bestemte kodebiter der risikoen for feil er høyest.
Kode churn
Kode churn Er en veldig nyttig visualisering av trender og svingninger som skjer med en kodebase både når det gjelder den totale prosessen og tiden før en utgivelse. Churn måler hvor mange linjer med kode som ble lagt til, fjernet eller endret. Noen ganger viser grafene alle tre målingene.
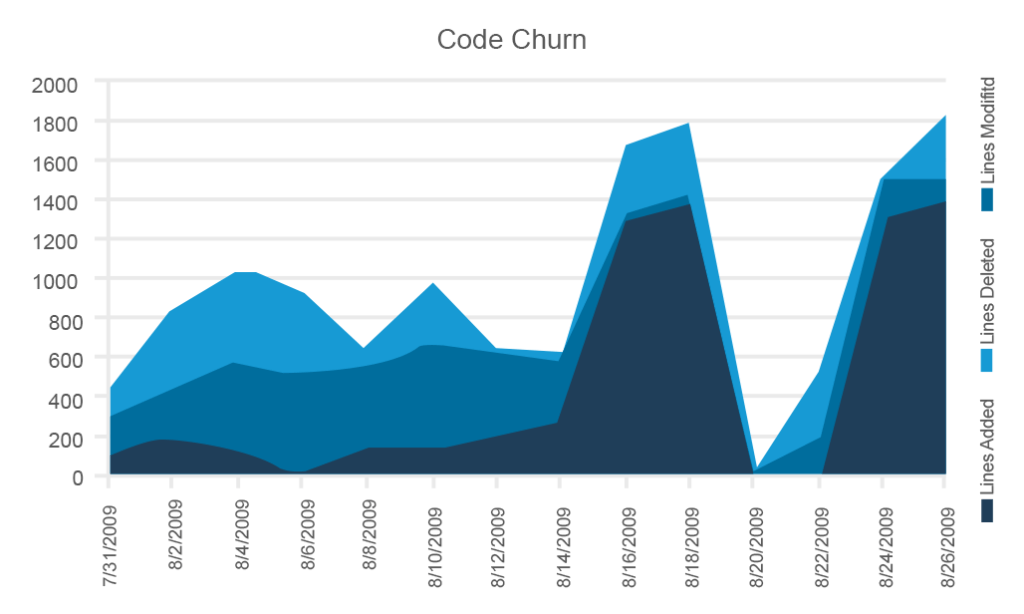
dette eksemplet fra Microsoft inneholder alle tre parametrene, men du kan bruke dem selektivt
selv om sporingskode churn kan virke som en noe primitiv metrisk, gjør det mulig å vurdere kodestabiliteten på forskjellige utviklingsstadier. Du bør forvente den laveste stabiliteten under de tidlige sprintene og den høyeste stabiliteten – med den samtidig laveste churn-rett før en utgivelse. Hvis koden din er svært ustabil og utgivelsesdatoen nærmer seg, høres alarmen.
bruk av kodet churn
Se etter regelmessigheter. Vanlige pigger i kodeendringer kan avsløre at oppgavegenereringstilnærmingen ikke er fokusert nok og produserer mange store oppgaver regelmessig.
Uregelmessige, men høye pigger krever etterforskning. Hvis du har uregelmessige, men kraftige pigger i kodeendringer, kan du undersøke hvilke oppgaver som forårsaket slike seismiske topper i koden din og revurdere nivået av avhengigheter, spesielt hvis antall nye kodelinjer økte antall endrede linjer også.
Vær oppmerksom på trender. Stabiliteten til produktet ditt blir ganske kritisk før en utgivelse. Som vi nevnte, bør churn-frekvensen ha en fallende trend jo nærmere teamet ditt kommer til en utgivelse. En økende trend betyr mulig produktstabilitet etter en utgivelse fordi det er sannsynlig at den nye koden ikke vil bli utsatt for tilstrekkelig testing.
Mål for fremgang, ikke kontroll
på samme måte som alle andre resultatindikatorer, har smidige beregninger ikke alltid forskjellige svar eller praktiske tips som vil forsegle suksessen din. Du bør imidlertid bruke kunnskapen de gir for å starte en diskusjon, gjennomføre en evaluering og tilby din egen plan for å håndtere problematiske problemer.
mens beregninger gir numerisk innsikt i et lags ytelse og generelle tilfredshet med arbeidet, må du ikke fokusere på dem. Med tanke på at smidige beregninger ikke er standardisert, er det ikke noe poeng i å sammenligne suksesser fra forskjellige lag. Sørg heller for å omfavne teamets tilbakemeldinger, starte regelmessige diskusjoner, og gi næring til en atmosfære av felles mål og støtte.