Du har kanskje brukt tremodeller i lang tid eller en nybegynner, men har du noen gang lurt på hvordan det faktisk fungerer og hvordan det er forskjellig fra andre algoritmer? Her, jeg deler en kort av mine forståelser.
CART er også en prediktiv modell som bidrar til å finne en variabel basert på andre merkede variabler. For å være mer tydelig tre modeller forutsi utfallet ved å stille et sett av if-else spørsmål. Det er to store fordeler i å bruke tre modeller,
- de er i stand til å fange ikke-lineariteten i datasettet.
- Ingen Behov For Standardisering av data ved bruk av tremodeller. Fordi de ikke beregner noen euklidisk avstand eller andre målefaktorer mellom data. Bare hvis-annet.
Nøtter Og Bolter Av Trær

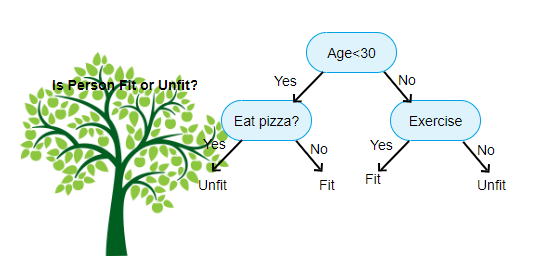
Over vist er et bilde Av Decision Tree Classifier, hver runde er kjent som Noder. Hver node vil ha en if-else-klausul basert på en merket variabel. Basert på det spørsmålet vil hver forekomst av inngang bli rettet / rutet til en bestemt bladknute som vil fortelle den endelige prediksjonen. Det finnes tre typer noder,
- Root Node: har ingen overordnet node, og gir to barn noder basert på spørsmålet
- Intern Node: Den vil ha en overordnet node, og gir to barn noder
- Leaf Node: Den vil også ha en overordnet node, men vil ikke ha noen barn noder
antall nivåer av vi har er kjent som max_depth. I diagrammet ovenfor max_depth = 3. Etter hvert som max_depth øker, vil modellkompleksiteten også øke. Mens vi trener hvis vi øker det, vil treningsfeilen alltid gå ned eller forbli den samme. Men det kan noen ganger øke testfeilen. Så vi må være kresen når du velger max_depth for en modell.
En annen interessant faktor om Node er informasjonsgevinst(IR). Dette er et kriterium som brukes til å måle renheten Til En Node. Renhet måles basert på hvor smart en node kan dele elementer. La oss si at du er På En Node, og du vil gå enten til venstre eller høyre. Men du har elementer tilhører begge klasser på samme beløp (50-50) på hver node. Da er renheten i begge klassene lav fordi du ikke vet hvilken retning du skal velge. Man må være høyere enn den andre for å ta en beslutning. dette måles VED HJELP AV IR,
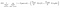

SOM navnet selv sier, er MÅLET MED CART å forutsi hvilken klasse en inngangsforekomst tilhører basert på sine merkede verdier. For å oppnå dette vil Det ta Beslutning Regioner ved Hjelp Av Beslutningsgrenser. Tenk deg at vi har ET 2d datasett,

som dette vil det skille vårt flerdimensjonale datasett i Beslutningsområder basert på if-else-spørsmålene på hver node. VOGNMODELLER kan finne mer nøyaktige beslutningsområder enn lineære modeller. Og beslutningsregionene etter VOGN er vanligvis rektangulære formet fordi bare en funksjon involvert i hver knutepunkt i beslutningsprosesser. Du kan visualisere det nedenfor,

jeg tror det er nok av introduksjoner, la oss se noen eksempler på hvordan du bygger VOGNMODELLER på Scikit learn.
Klassifiseringstreet
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regresjonstreet
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Håper denne artikkelen er nyttig, hvis du har noen diskusjoner eller forslag, vennligst legg igjen et privat notat.