kunnen kosten In het tijdperk van big data, is de uitdaging niet langer toegang tot genoeg gegevens; de uitdaging is het uitzoeken van de juiste gegevens om te gebruiken. In een vorig artikel richtte ik me op de waarde van alternatieve data, wat een essentieel bedrijfsmiddel is. Zelfs met de voordelen van alternatieve data, echter, de verkeerde data granulariteit kan ondermijnen de ROI van data-driven management.
“we zijn zo geobsedeerd door data, dat we vergeten hoe we het moeten interpreteren”. – Danah Boyd, Principal Researcher bij Microsoft Research
dus hoe goed moet u kijken naar uw gegevens? Omdat de verkeerde data granulariteit je meer kan kosten dan je denkt.
simpel gezegd, data granulariteit verwijst naar de mate van gedetailleerdheid van onze gegevens. Hoe gedetailleerder uw gegevens, hoe meer informatie in een bepaald gegevenspunt. Het meten van jaarlijkse transacties in alle winkels in een land zou een lage granulariteit hebben, omdat je heel weinig weet over wanneer en waar klanten die aankopen doen. Het meten van de transacties van individuele winkels door de tweede, aan de andere kant, zou ongelooflijk hoge granulariteit.
de ideale datagranulariteit hangt af van het soort analyse dat u doet. Als u op zoek bent naar patronen in consumentengedrag over decennia, lage granulariteit is waarschijnlijk prima. Om te automatiseren Store aanvulling, echter, je zou veel meer gedetailleerde gegevens nodig.
wanneer u de verkeerde granulariteit kiest voor uw analyse, krijgt u minder accurate en minder bruikbare intelligentie. Denk na over hoe rommelig wekelijkse Store aanvulling alleen gebaseerd op jaarlijkse systeembrede gegevens zou zijn! Je zou continu ervaren zowel overtollige voorraad en voorraden, het vergaren van enorme kosten en hoge niveaus van afval in het proces. In elke analyse, de verkeerde data granulariteit kan net zo ernstige gevolgen hebben voor uw efficiëntie en bottom line.
gebruikt u de juiste datakorreligheid voor uw business intelligence? Hier zijn vijf veel voorkomende — en dure-data granulariteit fouten.
groepeer meerdere bedrijfstrends in één patroon (wanneer gegevens niet gedetailleerd genoeg zijn).Business intelligence moet duidelijk en duidelijk zijn om actiebaar te zijn, maar soms duiken mensen in een poging om eenvoud te bereiken niet diep genoeg in de gegevens. Dat is jammer, want je zult waardevolle inzichten missen. Wanneer de gegevensgranulariteit te laag is, zie je alleen grote patronen die aan het oppervlak verschijnen. U kunt kritieke gegevens missen.
in veel te veel gevallen leidt het niet goed genoeg bekijken van uw gegevens tot het comprimeren van ongelijksoortige trends in één resultaat. Bedrijven die deze fout maken eindigen met ongelijke resultaten. Ze hebben meer kans op onvoorspelbare en extreme uitschieters die niet passen bij het algemene patroon — omdat dat patroon niet de realiteit weerspiegelt.
dit is een veel voorkomend probleem in veel traditionele voorspellingssystemen voor de toeleveringsketen. Ze kunnen niet omgaan met het niveau van granulariteit die nodig is om SKU-niveau vraag te voorspellen in individuele winkels, wat betekent dat een enkele winkel kan worden omgaan met zowel overstocks en aandelen op hetzelfde moment. Geautomatiseerde systemen aangedreven door AI kunnen omgaan met de complexiteit die nodig is om gegevens goed te segmenteren, dat is een van de redenen waarom deze de efficiëntie van de toeleveringsketen verbeteren. Voldoende data granulariteit is van cruciaal belang voor meer accurate business intelligence.

verdwalen in de gegevens zonder een focuspunt (wanneer de gegevens te korrelig zijn).
hebt u ooit per ongeluk veel te ver in een kaart ingezoomd online? Het is zo frustrerend! Je kunt geen nuttige informatie vinden omdat er geen context is. Dat gebeurt ook in data.
als uw gegevens te korrelig zijn, verdwaalt u; U kunt niet genoeg focussen om een nuttig patroon te vinden binnen alle externe gegevens. Het is verleidelijk om het gevoel dat meer detail is altijd beter als het gaat om gegevens, maar te veel detail kan uw gegevens vrijwel nutteloos te maken. Veel leidinggevenden geconfronteerd met zoveel gegevens vinden zichzelf bevroren met analyse verlamming. Je eindigt met onbetrouwbare aanbevelingen, een gebrek aan zakelijke context, en onnodige verwarring.
te gedetailleerde gegevens zijn een bijzonder kostbare fout als het gaat om AI-voorspellingen. De gegevens kunnen het algoritme verleiden om aan te geven dat het genoeg gegevens heeft om aannames te maken over de toekomst die niet mogelijk is met de technologie van vandaag. In mijn supply chain werk bij Evo is het bijvoorbeeld nog steeds onmogelijk om de dagelijkse omzet per SKU te voorspellen. Uw foutmarge zal te groot zijn om nuttig te zijn. Dit niveau van granulariteit ondermijnt doelen en vermindert ROI.
niet doelbewust de granulariteit van tijdvariabelen kiezen.
de meest voorkomende fouten in de granulariteit van gegevens houden verband met tijdsintervallen, d.w.z. het meten van variabelen per uur, per dag, per week, per jaar, enz. basis. Temporale granulariteitsfouten komen vaak voor omwille van het gemak. De meeste bedrijven hebben standaard manieren om getimede variabelen te rapporteren. Het voelt alsof het te veel moeite zou vergen om ze te veranderen, dus dat doen ze niet.maar dit is zelden de ideale granulariteit om het probleem geanalyseerd aan te pakken.
wanneer u de kosten afweegt van het veranderen van de manier waarop uw systeem KPI ‘ s rapporteert versus de kosten van het consequent verkrijgen van onvoldoende business intelligence, de voordelen van het doelbewust kiezen van het juiste granulariteitsregister. Afhankelijk van de granulariteit van de tijd, herkent u zeer verschillende inzichten uit dezelfde gegevens. Neem bijvoorbeeld seizoensgebonden trends in retail. Kijken naar transacties over een enkele dag kan seizoensgebonden trends onzichtbaar maken of, op zijn minst, bevatten zo veel gegevens dat patronen zijn gewoon witte ruis, terwijl maandelijkse gegevens deelt een verschillende volgorde die u daadwerkelijk kunt gebruiken. Als standaard KPI ‘ s Maandelijkse rapportage overslaan om rechtstreeks naar kwartaalpatronen te gaan, verliest u waardevolle inzichten die voorspellingen nauwkeuriger zouden maken. Je kunt geen tijd granulariteit nemen op het eerste gezicht als je de beste intelligentie wilt krijgen.


Overfitting of underfitting uw model naar het punt dat de patronen die je ziet, zijn zinloos.
AI-modellen moeten goed generaliseren op basis van bestaande en toekomstige gegevens om nuttige aanbevelingen te kunnen doen. In wezen een goed model zou kunnen kijken naar deze gegevens:

En stel dat dit een werkend model op basis van de informatie:

Het patroon niet perfect vertegenwoordigen de gegevens, maar het doet zijn werk goed te voorspellen typische gedrag zonder concessies te veel intelligentie.
als u echter niet de juiste gegevensgranulariteit hebt, kunt u het verkeerde model krijgen. Zoals we eerder besproken, kunnen al te korrelige gegevens ruis veroorzaken dat het vinden van een patroon moeilijk maakt. Als uw algoritme consequent traint met dit lawaaierige detailniveau, zal het ruis leveren op zijn beurt. Je eindigt met een model dat er zo uitziet:

We noemen dit overfitting uw model. Elk datapunt heeft een buitenmaatse impact, in die mate dat het model niet meer nuttig kan generaliseren. De problemen die aanvankelijk door hoge granulariteit werden veroorzaakt, worden vergroot en een permanent probleem in het model gemaakt.
een te lage gegevensgranulariteit kan ook op lange termijn schade toebrengen aan uw model. Een algoritme moet voldoende gegevens hebben om patronen te vinden. Algoritmen getraind met data zonder voldoende granulariteit zullen kritische patronen missen. Zodra het algoritme voorbij de trainingsfase is gegaan, zal het blijven falen om vergelijkbare patronen te identificeren. Je eindigt met een model dat er zo uitziet:
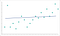
dit past niet bij het model. Het algoritme komt dicht bij het maken van de juiste voorspellingen, maar ze zullen nooit zo nauwkeurig zijn als ze hadden kunnen zijn. Net als overbevissing is het een vergroting van het aanvankelijke granulariteitsprobleem.
wanneer u een model voor uw analyse maakt, wordt de juiste granulariteit exponentieel belangrijker dan wanneer u een stabiel algoritme hebt. Daarom kiezen veel bedrijven ervoor om dit deel van het proces uit te besteden aan experts. Het is een te delicate en kostbare fase voor fouten.
de granulariteit van de onjuiste gegevens volledig aanpassen.
misschien is de duurste fout in de granulariteit van gegevens alleen maar zozeer gericht op het optimaliseren van de granulariteit van KPI ’s die u momenteel meet, dat u niet beseft dat ze de verkeerde KPI’ s zijn. We streven ernaar om de juiste data granulariteit te bereiken, niet om specifieke KPI-prestaties te optimaliseren, maar om patronen in de data te herkennen die bruikbare en waardevolle inzichten opleveren. Als u wilt om de inkomsten te verbeteren, Bijvoorbeeld, kunt u ondermijnen uw succes door alleen te kijken naar patronen in de prijsstelling. Er zijn andere factoren bij betrokken.
neem een voorbeeld van mijn collega. Een nieuwe Evo-klant wilde de omzet verhogen en een eerste test met onze Supply Chain tools toonde een verbetering van 10% in minder dan twee weken. Onze CEO was meer dan enthousiast over deze ongekende resultaten, maar tot zijn verbazing was de supply chain manager niet onder de indruk. Zijn primaire KPI was productbeschikbaarheid, en volgens interne nummers, die nooit was veranderd. Zijn focus op het verbeteren van een bepaalde KPI kwam ten koste van het herkennen van waardevolle inzichten uit andere data.


of dat de KPI ‘ werd nauwkeurig gemeten, met de nadruk volledig op het veranderen van de voorstelling gehouden deze manager terug te zien de waarde in van een nieuwe aanpak. Hij was een slimme man die te goeder trouw handelde, maar de gegevens misleidden hem — een ongelooflijk veel voorkomende maar dure fout. Correcte data granulariteit is van vitaal belang, maar het kan geen doel op zich zijn. Je moet naar het grotere plaatje kijken om je rendement van AI te maximaliseren. Hoe goed je naar je gegevens kijkt maakt niet uit als je in de eerste plaats niet de juiste gegevens hebt.
“een veel voorkomende misvatting van data-driven management is het gebruik van de verkeerde gegevens om de juiste vraag te beantwoorden”. – Fabrizio Fantini, oprichter en CEO van Evo
de voordelen van de juiste data granulariteit
er is geen magische kogel als het gaat om data granulariteit. U moet het zorgvuldig en opzettelijk kiezen om deze en andere minder vaak voorkomende fouten te voorkomen. De enige manier om het rendement van uw gegevens te maximaliseren is om er kritisch naar te kijken — meestal met de hulp van een expert data scientist. Je krijgt waarschijnlijk niet meteen granulariteit bij je eerste poging, dus je moet testen en aanpassen totdat het perfect is.
het is echter de moeite waard. Als u goed, maar niet te goed kijkt, zorgt uw data voor optimale business intelligence. Gesegmenteerd en correct geanalyseerd, data transformeert in een concurrentievoordeel waar u op kunt rekenen.