Leestijd: 13 minuten
de agile benadering van softwareontwikkeling is al lang een gangbare praktijk. Volgens de HP online enquête, 16 procent van de IT-professionals kiezen voor pure agile, 51 procent leunen in de richting van het, en 24 procent kiezen voor een agile hybride aanpak. Vandaag de dag, waterval ontwikkeling wordt het vaakst genoemd als een agile differentiator, wat agile is niet. In onze whitepaper over agile Project management methodologieën hebben we de belangrijkste verschillen uitvoerig besproken.
ondanks het aanpassingsvermogen en de flexibiliteit van agile management en de snelle reactie op veranderingen, kan de workflow gecentraliseerd en gecontroleerd blijven. Agile KPI ‘ s (key performance Indicators) bieden begeleiding voor strategische planning, evaluatie en verbetering van operationele processen.
traditionele waardebeheersystemen richten zich meestal op het voltooien van taken binnen het kader van categorisch schema en kosten. Met agile zien klanten en teamleden echter onmiddellijk resultaten en passen ze de termijnen en inspanningen aan om een product te leveren dat voldoet aan de vereisten van het schema. Welke instrumenten en technieken vraagt deze kennis? Hier is ons overzicht van agile development metrics performance assessment.
Agile software development KPI ‘s
in dit artikel gaan we niet alle mogelijke agile development metrics en KPI’ s verkennen. Op de top van dat, kunt u uw eigen degenen die passen bij uw project het beste uitvinden. We zullen echter de meest voorkomende KPI ‘ s beschrijven die worden gebruikt voor meerdere aspecten van softwareontwikkeling:
- Snelheid
- Sprint burndown
- Release burndown
- cyclustijd
- Cumulatieve debiet
- Flow-efficiëntie
- Code coverage door geautomatiseerde tests
- Test automatisering tegen een handmatige testen
- McCabe Cyclometrische Complexiteit (MCC)
- Code churn
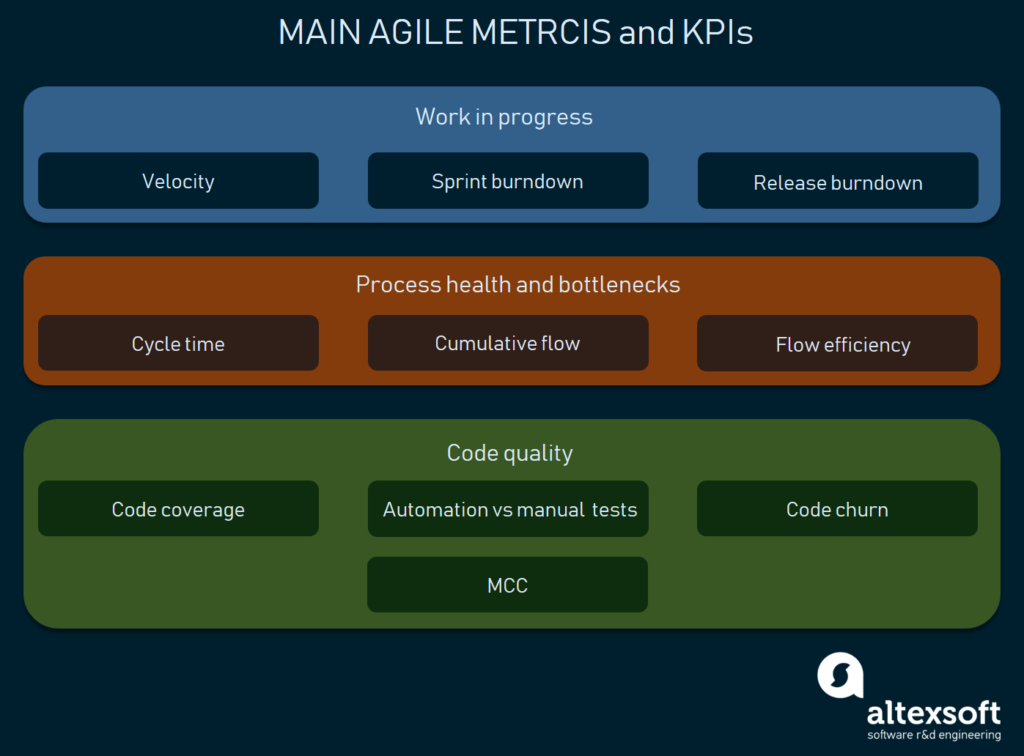
Dit zijn de belangrijkste dingen die u moet verkennen eerste
het Meten van de work in progress
Snelheid
Snelheid meet de hoeveelheid werk (een aantal functies) ingevuld in een sprint. Hoewel het geen voorspelling of vergelijking tool, velocity biedt teams met een idee over hoeveel werk kan worden gedaan in de volgende sprint.
Velocity index is uniek voor elk team en moet worden ingesteld om te beoordelen hoe realistisch de inzet is. Bijvoorbeeld, als het project achterstand heeft 200 verhaal punten en gemiddeld het team voltooit 10 verhaal punten per sprint, betekent dit dat het team ongeveer 20 sprints nodig heeft om het project te voltooien.
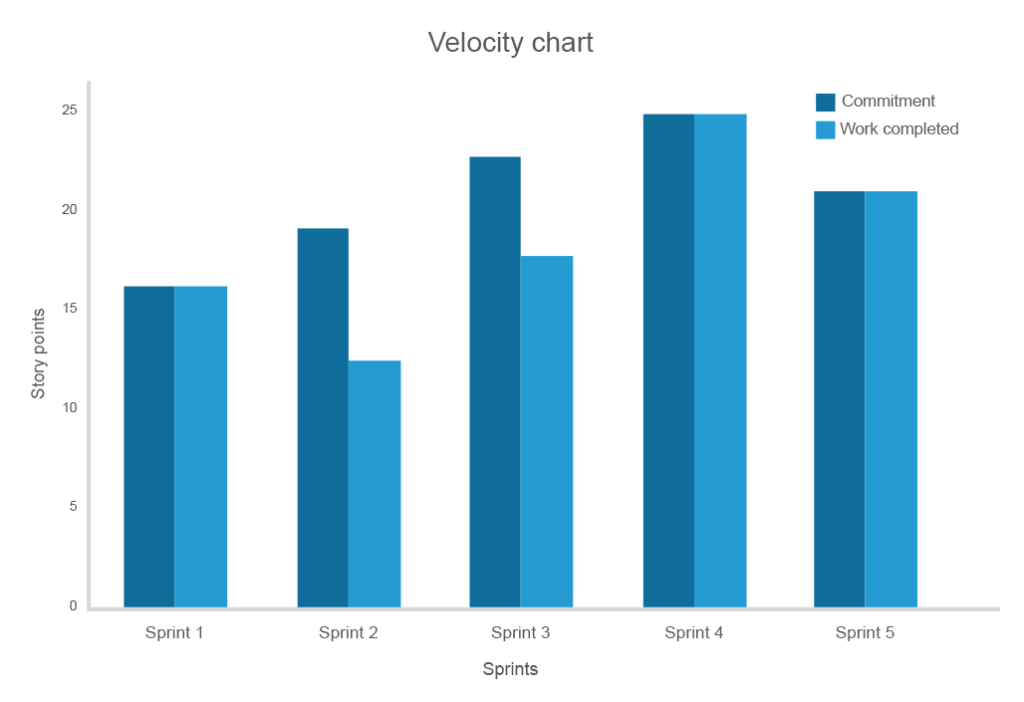
hoe langer u de snelheid volgt, hoe groter de nauwkeurigheid van de overeenkomst tussen verplichtingen en kosten
voor een team dat net de agile methodologie heeft aangenomen of zelfs een nieuw product heeft ontwikkeld, zullen de snelheidsschattingen van de eerste sprints waarschijnlijk onregelmatig zijn. Maar als teams ervaring opdoen, zal de snelheid pieken en dan een plateau van voorspelbare flow en prestatieverwachting bereiken. Een afname van de consistente stroom zal wijzen op problemen in de ontwikkeling en de noodzaak van verandering onthullen.
Tips for use the velocity metric
Combat inconsistentie na 3-5 sprints. Als de snelheid na een lange periode inconsistent blijft, overweeg dan om zowel externe als interne factoren te beoordelen die een duidelijke schatting voorkomen.
Verander de snelheid tracking na team en taak veranderingen. Wanneer een teamlid het project verlaat of er meer leden/taken worden toegevoegd, herberekent u de snelheid of herstart u de berekening volledig.
drie sprints zijn voldoende voor vroege voorspellingen. Voor het voorspellen van toekomstige prestaties, gebruik maken van het gemiddelde van de drie vorige sprints.
Sprint burndown chart
de sprint burndown chart toont de hoeveelheid werk die nog moet worden gedaan voor het einde van een sprint. De tool is bijzonder waardevol omdat het toont de vooruitgang naar het doel in plaats van een lijst voltooide items. Het is ook erg handig bij het blootleggen van planningsfouten die een team maakte in het begin van een sprint.
op de grafiek onder de zwarte lijn staat de voorspelde (ideale trend) lijn die aangeeft in welk tempo de ploeg story points moet afbranden om de sprint op tijd te voltooien. De blauwe lijn geeft de totale hoeveelheid werk en de voortgang tijdens de sprint aan. Je kunt zien dat tijdens de dagen vijf en zes, een team er niet in geslaagd om de voorspelde vooruitgang te bereiken. Op dag zeven werd het probleem echter aangepakt en was het werk weer op schema. Dergelijke voortdurende updates stellen teams in staat om opkomende problemen aan te pakken tijdens dagelijkse stand-up vergaderingen.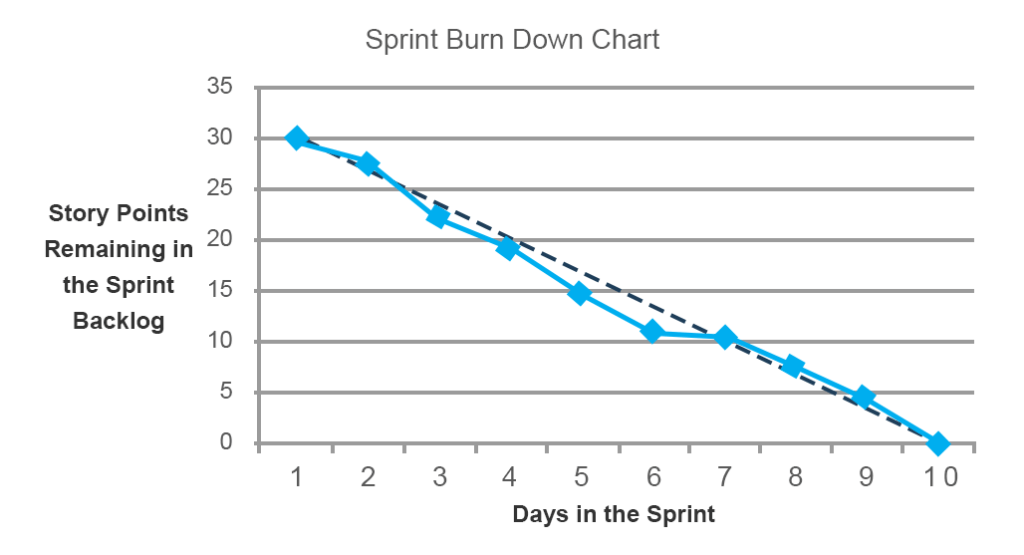
naast de werkprestaties zelf, kunnen burndown charts planningsproblemen onthullen
Tips om sprint burndown
te benaderen Story points zouden zelfs in scope moeten zijn. Als de workflow niet consistent is, kunnen sommige taken zijn opgesplitst in ongelijke brokken. De omvang van de afwijking tussen een ideale trend en de realiteit benadrukt dit probleem duidelijk.
rekening houden met ongeplande taken. De burndown grafiek is handig voor het begrijpen van de omvang van verborgen en niet-trackte taken. Als de hoeveelheid werk toeneemt in plaats van afneemt, heeft het project veel niet-Geschatte of ongeplande taken die moeten worden aangepakt.
gebruik een burndown grafiek om het vertrouwen van het team te beoordelen. Gezien de huidige tarieven, vraag uw team hoe zeker ze zijn over het voltooien van de sprint op tijd. Hoe langer u deze metriek toepast, hoe nauwkeuriger uw sprintschattingen zijn.
het schatten van de release met een burndown grafiek
een burndown grafiek geeft de hoeveelheid werk aan die moet worden voltooid voordat een release. De grafiek illustreert het voortgangsoverzicht en stelt u in staat om wijzigingen door te voeren om te zorgen voor tijdige levering.
een traditionele versie van de grafiek is vergelijkbaar met de sprint burndown grafiek, maar geeft een overzicht van het gehele project waar de y-as sprints is en de x-as een maat is voor het resterende werk (dagen, uren, of verhaalpunten). Maar wat als er meer werk aan het project wordt toegevoegd of uw geschatte werk niet aan de verwachtingen voldoet?
op de onderstaande grafiek was een team van plan om een project in vier sprints af te ronden en had in eerste instantie 45 story points. Terwijl de vooruitgang ging zoals gepland tijdens de eerste en tweede sprint, bij de derde sprint de geschatte werk toegenomen, die wordt weerspiegeld op de y-as in negatieve waarden. Tijdens de derde sprint verschenen er 5 nieuwe story points. Ze waren niet klaar en de vierde sprint voegde nog eens 5 verhaalpunten toe. Daarom moesten de voortgang en de releasetijd worden aangepast.
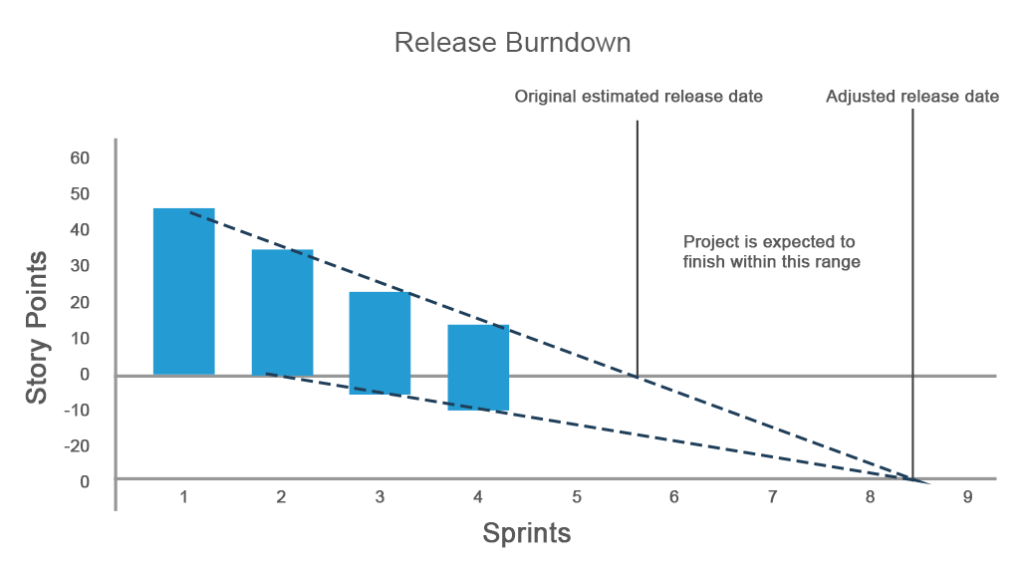
de release burndown chart is super effectief voor situaties met veel veranderende eisen en stelt een team in staat om op koers te blijven tijdens elke sprint
Hoe kan de release burndown chart helpen?
real-time voorspelling bij release. Zodra uw project veranderingen ondergaat, wat elke keer gebeurt bij het iteratief ontwikkelen van producten, moet u zien hoe deze veranderingen de releasedatum beïnvloeden. De burndown-grafiek van de release maakt het mogelijk om de release-datum in real-time te voorspellen op basis van updates in het werkbereik.
Termijnvoorspellingen. U kunt inschatten of het team een product release op tijd kan voltooien of anticiperen dat de deadline verder moet gaan met het overwegen van extra taken.
schatting van het aantal sprints. Beoordelen hoeveel sprints nodig zijn om het werk af te maken is ook een belangrijke factor om te overwegen met de release burndown chart.
beoordeling van de gezondheid van het proces en het vinden van knelpunten
cyclustijd
de cyclustijdmetrie beschrijft hoeveel tijd aan een taak werd besteed, inclusief elke keer dat het werk opnieuw moest worden heropend en voltooid. Het berekenen van de cyclustijd geeft informatie over de algehele prestaties en maakt het mogelijk om de voltooiing van toekomstige taken te schatten. Terwijl de kortere cyclustijd betere prestaties illustreert, worden de teams die binnen een consistente cyclus leveren het meest gewaardeerd.
met behulp van het diagram hieronder kunt u de gemiddelde tijd identificeren die nodig is om een taak te voltooien, een mediaan-of regellimietlijn tekenen die niet overschreden mag worden, en opmerken welke taken ongewoon lang duurde om te voltooien.
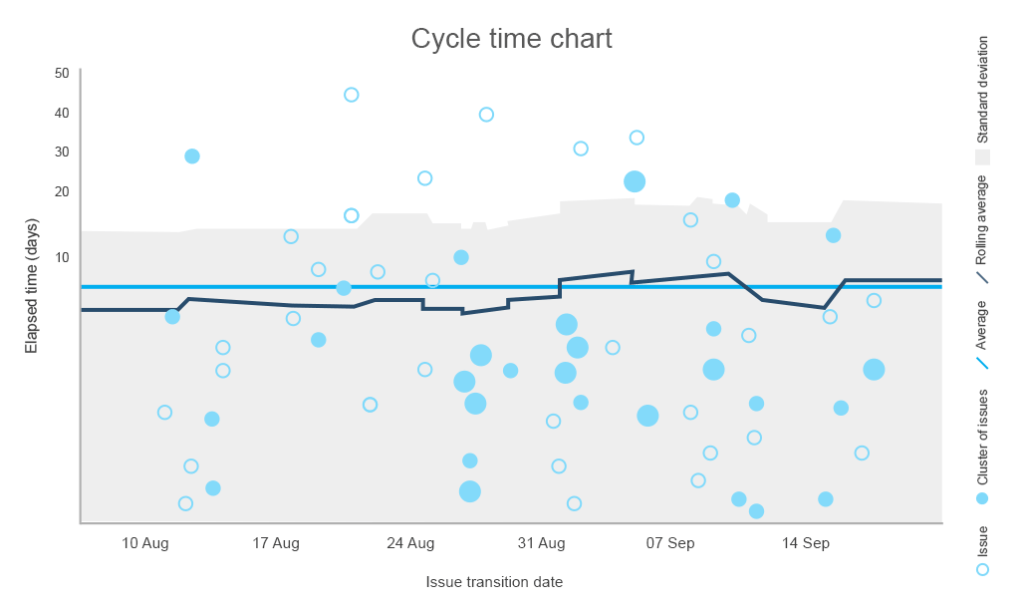
te voltooien de standaardafwijking tekent een lijn tussen het normale en niet aanbevolen aantal dagen om de taak
te voltooien U kunt ook alle cycli voor een bepaalde periode stapelen en inzicht trekken door deze met andere gegevens te vergelijken. Door nader onderzoek kun je conclusies trekken over de kwaliteit van het werk.
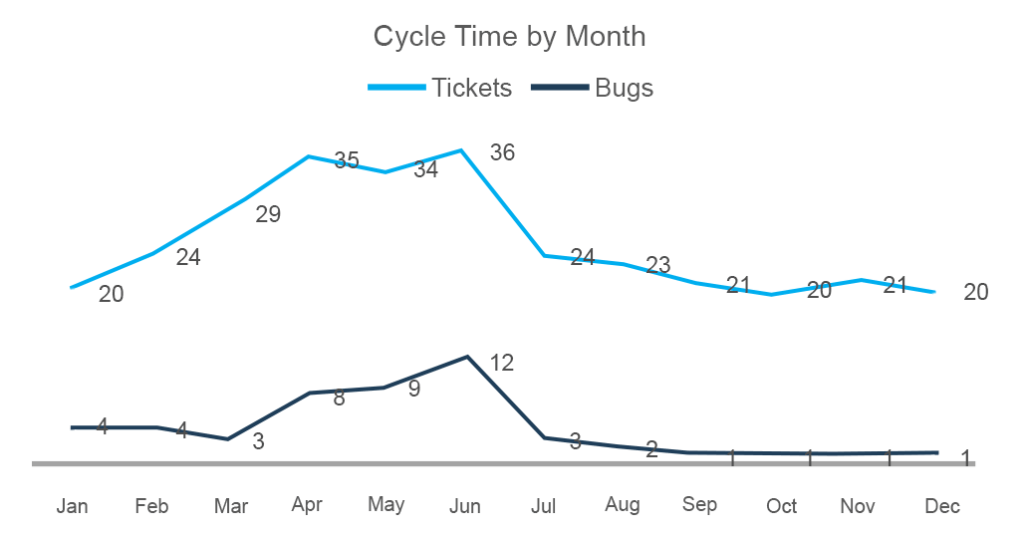
Hier kunt u zien dat het aantal voltooide taken van maart tot juni is toegenomen, evenals het aantal bugs
hoe de cyclustijd
te gebruiken zoek naar overeenkomsten. Een goede praktijk is om soortgelijke items te vinden die onvoorspelbare cyclustijden vergen om te voltooien, waardoor terugkerende problemen worden onthuld, hetzij in engineering of management.
teken voorspellingen. U kunt data-driven beslissingen te nemen door het voorspellen van de tijd om nieuwe taken te voltooien op basis van soortgelijke uit het verleden.
volg het tempo. De grafiek beschrijft hoe u hetzelfde tempo van het werk te houden en te bepalen of er interne problemen die de snelheid van het werk te verminderen.
cumulatief stroomdiagram (CFC)
de cumulatieve stroommeting wordt beschreven door het diagramgebied dat het aantal verschillende soorten taken in elke fase van het project toont, met de x-as die de data aangeeft en de y-as die het aantal story points toont. Het belangrijkste doel is om een eenvoudige visualisatie van hoe taken worden verdeeld in verschillende stadia. De lijnen op de grafiek moeten min of meer blijven, terwijl de band met de “done” taken voortdurend moet groeien.
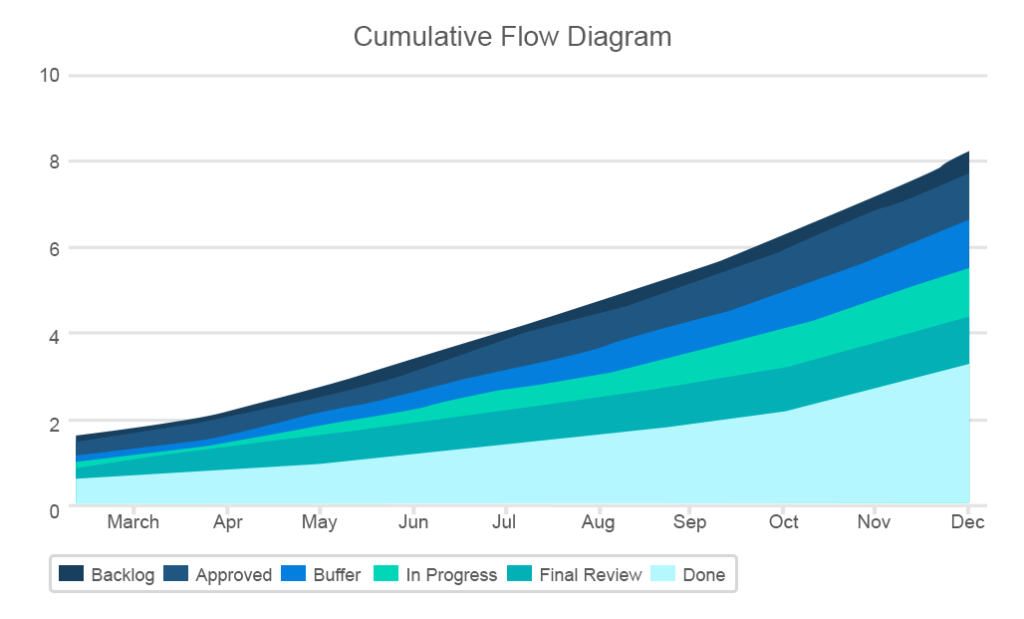
de grafiek geeft veel kritische informatie zoals plotselinge knelpunten of stijgingen in een van de banden
de CFC zal van groot nut zijn voor Kanban-teams als een eenvoudige visualisatie van het werk van het team. De grafiek komt ook overeen met de drie-stappen workflow van Kanban. Hier kunt u ook drie hoofdtaken in kaart brengen: taak, bezig en voltooid.
bovendien helpt de grafiek te bepalen wanneer de work-in-progress (WIP) limieten worden overschreden. Als een van de meest waardevolle tools in agile ontwikkeling, WIP limieten zijn bedoeld om de cultuur van afwerking te cultiveren en multitasking te elimineren door het instellen van de maximale hoeveelheid werk voor elk project status.
welke kwesties worden door de CFC naar voren gebracht?
- Achterstand groei geeft de onopgeloste taken die of te lage prioriteit te pakken op het moment of zijn verouderd
- Inconsistente flow en plotselinge knelpunten aangeven welke gebieden moeten worden gladgestreken in de latere stadia
- De breedte van de band geeft de gemiddelde cyclustijd
- De aanzienlijke stijging van de “In progress” gebied kan betekenen dat het team niet in staat zijn om te voltooien van het hele project op tijd
Flow-Efficiëntie
Flow-efficiëntie is een zeer nuttig gegeven in de Kanban-ontwikkeling grotendeels over het hoofd gezien door de ontwikkeling van team. Terwijl flow efficiency de cumulatieve flow aanvult, geeft het inzicht in de verdeling tussen de werkelijke werk-en wachttijden. Het is een zeldzaam geval wanneer een ontwikkelaar werkt aan één ding tegelijk zonder te wachten. De realiteit is meestal complexer. En “work-in-progress” is een naam die niet altijd overeenkomt met de status.
bijvoorbeeld, de code kan veel afhankelijkheden hebben en u kunt niet beginnen met het werken met een functie voordat een andere is voltooid, of uw prioriteiten veranderen, of u wacht op de goedkeuring van een stakeholder. Meten hoeveel tijd u wacht tegen het werk kan nog nuttiger zijn dan het stroomlijnen van processen met betrekking tot het werkelijke werk.
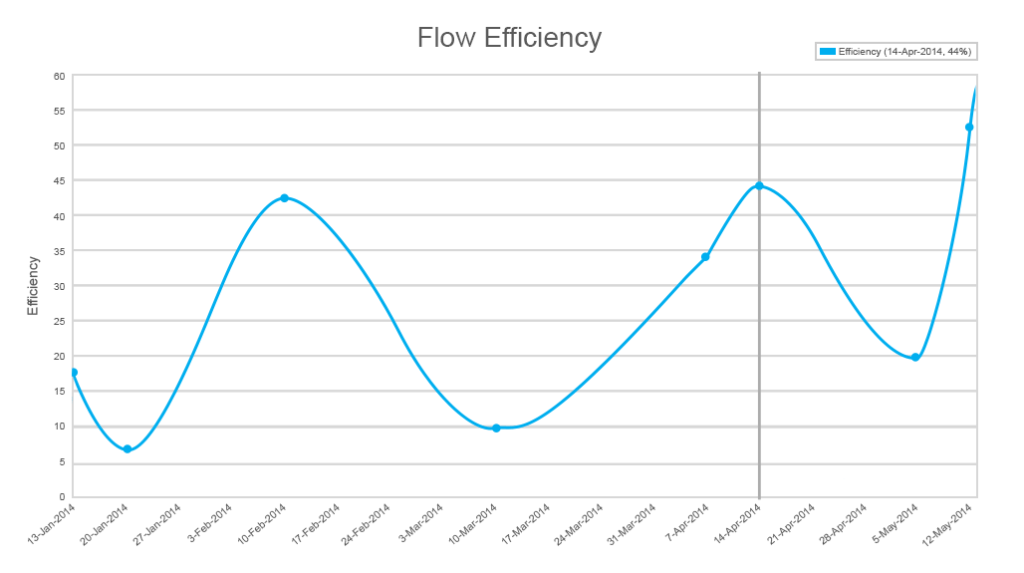
door te kijken naar de laagste efficiëntie-indicatoren, kunt u de belangrijkste knelpunten begrijpen
hoe flow efficiency
berekeningsformule te gebruiken. Tenzij u een aantal project management software die deze statistieken bevat toe te passen, kunt u de flow efficiëntie te berekenen door middel van deze eenvoudige formule: werk/(werk+wachten) * 100%. Dan kunt u het digitaal visualiseren of zelfs de grafiek op uw whiteboard op kantoor tekenen.
Definieer uw normale stroomefficiëntie. Zoals met alle andere statistieken, is het onmogelijk om normale cijfers voor alle projecten te claimen. Sommigen zeggen dat de 15 procent mark is oke voor de meeste projecten, wat in feite betekent dat een verhaal punt of een ander item van het werk Wacht 85 procent tegen 15 procent verwerkingstijd. David J. Anderson, een managementexpert van de LeanKanban School of Management, stelt voor dat 40 procent en hoger het doel zou moeten zijn voor de meeste teams.
ontleden details van het werk alvorens het debietrendement vast te stellen. De grafiek zal toestaan voor het bekijken van exacte perioden van tijd wanneer uw efficiëntie was de laagste. En deze gegevens moeten zeer zorgvuldig worden geanalyseerd, omdat de echte oorzaak en de remedie niet zo gemakkelijk wordt onthuld. Voordat u begint met intensieve acties, Maak een grondig onderzoek van de oorzaken.
vergroot de flow-efficiëntie met blocker-analyse. Een goede manier om het vorige punt te realiseren is om uw flow-efficiëntie te vergroten met blocker clustering analyse. Als er werk wordt geblokkeerd, verdient het een gekleurde sticker of een andere vorm van visueel signaal om deze blokkers onder de aandacht van het team te brengen, zodat ze erop kunnen reageren.
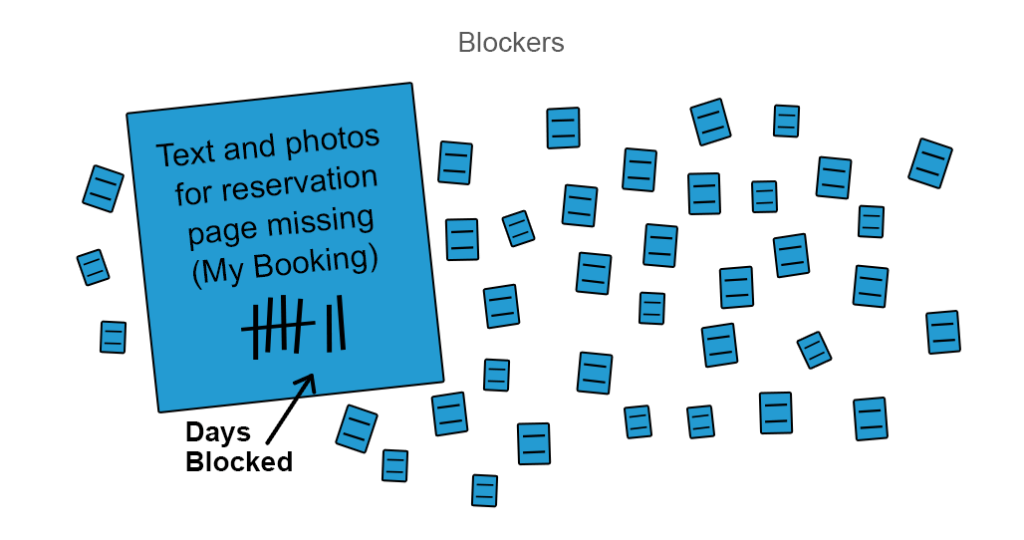
u kunt markeren hoeveel dagen een deel van het werk geblokkeerd is en prioriteit geven aan de resolutie
meestal stapelen blokkers zich op in clusters omdat ze veel afhankelijkheden met elkaar hebben. Betere blocker analyse kan worden gedaan als je ze te clusterize vanaf high-level overeenkomsten zoals interne en externe blokkers en vervolgens specificeren verder door ontwerp, ontbrekende inhoud, of andere ontbrekende functies. Blocker analyse is een eenvoudige manier om de valleien in flow efficiency te onderzoeken.
Measuring code quality
codedekking
codedekking bepaalt hoeveel regels code of blokken worden uitgevoerd terwijl geautomatiseerde tests worden uitgevoerd. Codedekking is een kritische maatstaf voor de test-driven development (TDD) praktijk en continue levering. Traditioneel wordt de metriek geïnterpreteerd door een eenvoudige benadering: hoe hoger de codedekking, hoe beter. Om dit te meten, heb je een van de beschikbare tools nodig, zoals overalls. Maar ze werken allemaal vrijwel hetzelfde: als je tests uitvoert, zal het gereedschap detecteren welke van de codelijnen minstens één keer worden aangeroepen. Het percentage aangeroepen lijnen is uw codedekking.
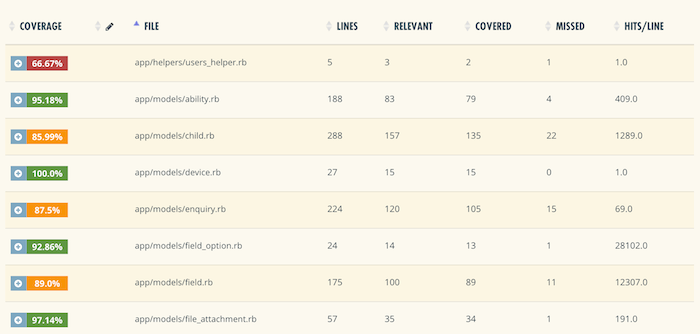

Overalls, bijvoorbeeld breekt de code coverage om elk bestand te meten en markeren overdekte en niet overdekte lijnen
Hoe te gebruiken code coverage
Focus op onbedekte lijnen en niet te overschatten de overdekte exemplaren. Als de regel code een keer of zelfs meer wordt genoemd, betekent dit niet noodzakelijkerwijs dat de functie die het ondersteunt perfect werkt en gebruikers tevreden zullen blijven. Het aanroepen van een regel code is niet altijd voldoende om de testtaak af te sluiten. Aan de andere kant toont het percentage ongedekte lijnen aan wat helemaal niet is gedekt en kan het testen waard zijn.
Geef de covered code prioriteit en richt niet op 100 procent. Hoewel dit lijkt contra-intuïtief, 100 procent dekking betekent niet dat je goed hebt getest code. Uw project heeft de code die ertoe doet en de rest van een code base. Aangezien het testen van automatisering meestal een duur initiatief is, moet het prioriteit geven aan de functies en bijbehorende stukjes code.
testautomatisering tegen handmatige tests
deze meting bepaalt hoeveel regels code binnen een functie al worden behandeld met geautomatiseerde tests tegen die welke handmatig worden getest. Dit volgt direct de vorige metriek, maar heeft een specifieke use case. Test automation verhouding tegen handmatige tests wordt alleen gebruikt wanneer u kritisch automatisering nodig hebt om regressies te dekken. Regressie testen wordt gedaan om te controleren of er iets werd gebroken na functie-updates. En als uw product ondergaat constante verbeteringen – die het zou moeten-testen voor regressie moet worden geautomatiseerd. Als dat niet het geval is, zullen je handmatige QA specialisten dezelfde testscenario ‘ s herhaaldelijk moeten herhalen na elke update commit.
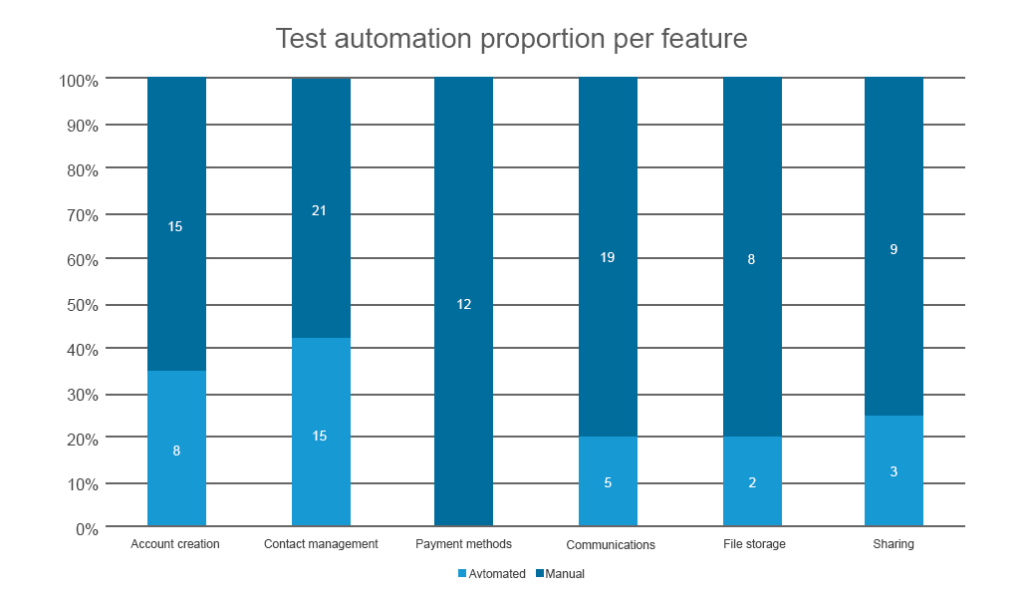
u kunt dezelfde instrumenten gebruiken die worden gebruikt voor codedekking om deze metriek te tekenen
waarin de geautomatiseerde testdekking per functie wordt weergegeven, kunt u prioriteit geven aan de functies die 1) na updates kunnen lijden aan regressie en 2) waarvoor geautomatiseerde tests van cruciaal belang zijn. Meestal heb je niet genoeg tijd en human resources om alles met geautomatiseerde tests tegelijk af te dekken, tenzij je binnen het test-driven development framework werkt. Dus, het is beter om prioriteit te geven aan de functies die zeker van invloed zijn op de gebruikerservaring.
McCabe Cyclomatic Complexity (MCC) of code
codecomplexiteitsmetingen worden gebruikt om de risico ‘ s van problemen tijdens codetests en onderhoud te beoordelen. Hoe hoger de complexiteit van de code, hoe moeilijker het wordt om ervoor te zorgen dat het een aanvaardbaar aantal bugs heeft en een hoge onderhoudbaarheid behoudt. De meest gebruikte methode voor het meten van codecomplexiteit is de McCabe Cyclomatic Complexity Metric (MCC). Een van de formules om complexe resultaten te tekenen voor MCC is de volgende:
MCC = edges-nodes + return statements
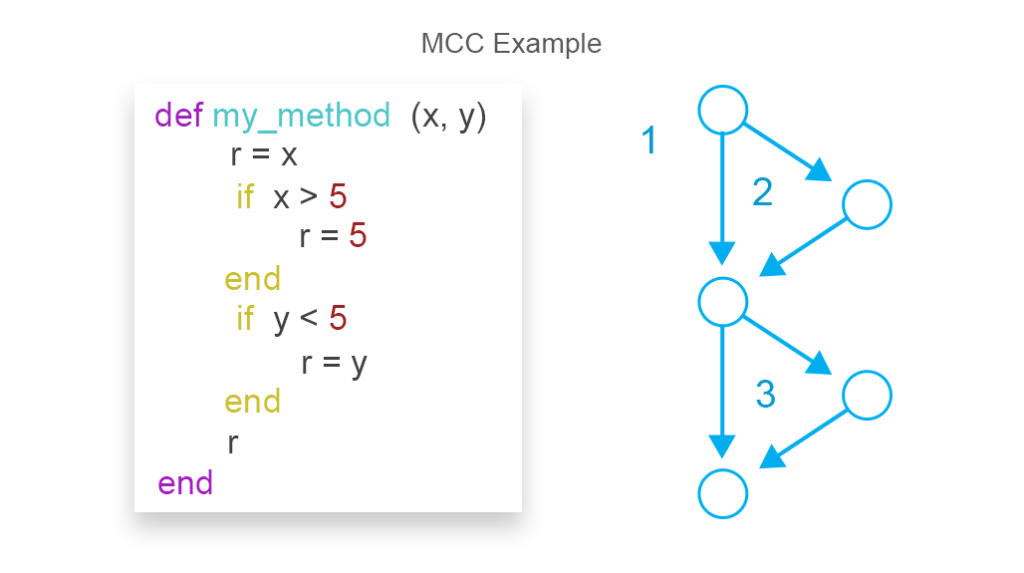
MCC op de afbeelding is gelijk aan 3
met deze metriek schatten ontwikkelaars hun codecomplexiteit niet door er subjectief naar te kijken. Als ingenieurs ‘ vaardigheden verschillen, hun beoordelingen variëren, waardoor code refactoring of het oplossen van bugs meer uitdagend op de langere termijn. Er zijn veel MCC-meetinstrumenten op de markt die kunnen worden gecombineerd met andere codecomplexiteitsmetingen, zoals de diepte van de codehiërarchie en het aantal codelijnen.
MCC gebruik specifieke kenmerken en valkuilen
balans tussen mens en machine perceptie van codecomplexiteit. Een van de belangrijkste redenen om MCC te gebruiken is om code leesbaar te maken voor collega-ontwikkelaars. De leesbaarheid van code vermindert de risico ‘ s van langdurige onboarding van nieuwe ontwikkelaars die te maken hebben met legacy code. Het zal ook vereenvoudigen refactoring op de weg. Het probleem hier is dat het MCC-model sommige complexe maar leesbare methoden onaanvaardbaar kan vinden. En als je een ontwikkelaar dwingt om complexe methoden om te zetten in vele submethoden, kun je het tegenovergestelde bereiken: veel methoden met eenvoudige logica kunnen nog moeilijker te begrijpen worden voor een mens dan een enkele maar complexe methode.
maak MCC geen beperkende maatstaf. Sommige organisaties oefenen in het beëindigen van code commits die niet slagen voor de MCC test. Hoewel dit de eenvoud van code kan vergroten, is het natuurlijk om complexe code te hebben op het niveau van klassen, methoden en functies. Ze volledig blokkeren is niet altijd gunstig. Een goede praktijk is om algemene code complexiteit KPI voor ontwikkelaars, die hen zal aanmoedigen om codering bewuster te benaderen en te denken aan eenvoud.
MCC toepassen voor codecontrole. Een andere waardevolle praktijk voor MCC-tests is om het toe te passen tijdens code reviews om de reikwijdte van het werk te beperken tot het beoordelen van specifieke code chunks waar de risico ‘ s van defecten het grootst zijn.
Code churn
Code churn is een zeer nuttige visualisatie van trends en fluctuaties die gebeuren met een code base zowel in termen van het totale proces en de tijd voor een release. Churn meet hoeveel regels code zijn toegevoegd, verwijderd of gewijzigd. Soms tonen de grafieken alle drie de metingen.
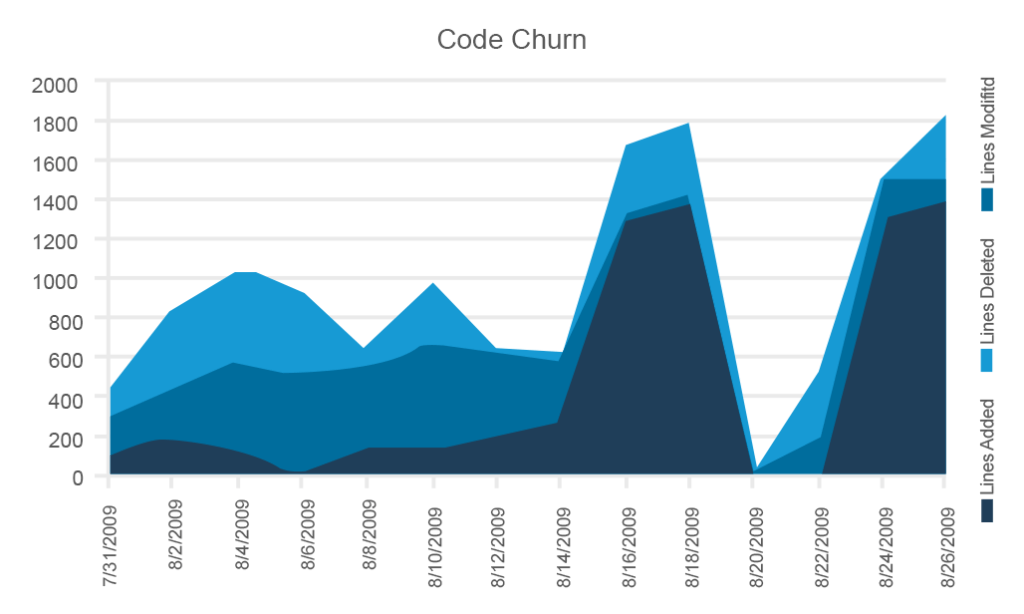
dit voorbeeld van Microsoft bevat alle drie de parameters, maar u kunt ze selectief gebruiken
hoewel het volgen van code churn een enigszins primitieve metriek lijkt, maakt het het mogelijk om de stabiliteit van de code in verschillende ontwikkelingsstadia te beoordelen. U moet de laagste stabiliteit verwachten tijdens de vroege sprints en de hoogste stabiliteit – met de bijbehorende laagste churn – vlak voor een release. Als uw code zeer onstabiel is en de releasedatum nadert, luidt het alarm.
use cases
zoeken naar regelmatigheden. Regelmatige pieken in code veranderingen kunnen onthullen dat de taak-generatie aanpak is niet genoeg gericht en produceert veel grote taken op een terugkerende basis.
onregelmatige maar hoge pieken vereisen onderzoek. Als u onregelmatige maar krachtige pieken in code wijzigingen, kunt u onderzoeken welke taken veroorzaakt dergelijke seismische pieken in uw code en heroverwegen het niveau van afhankelijkheden, vooral als het aantal nieuwe code regels verhoogd het aantal gewijzigde regels ook.
aandacht besteden aan trends. De stabiliteit van uw product wordt vrij kritisch voor een release. Zoals we al zeiden, de churn rate moet een dalende trend hoe dichter uw team krijgt om een release. Een groeiende trend betekent mogelijke product instabiliteit na een release, omdat het waarschijnlijk is dat de nieuwe code niet zal worden onderworpen aan voldoende testen.
streven naar vooruitgang, niet controleren
net als alle andere prestatie-indicatoren hebben agile metrics niet altijd duidelijke antwoorden of bruikbare tips die uw succes zullen bezegelen. Echter, je moet de kennis die zij bieden gebruiken om een discussie te starten, voeren een evaluatie, en bieden uw eigen plan in het omgaan met problematische kwesties.
hoewel metrics het numerieke inzicht geven in de prestaties van een team en de algehele tevredenheid over het werk, fixeer je er niet op. Gezien het feit dat agile metrics niet gestandaardiseerd zijn, heeft het geen zin om successen van verschillende teams te vergelijken. Zorg er eerder voor dat u de feedback van uw team omarmt, regelmatige discussies initieert en een sfeer van gemeenschappelijke doelen en ondersteuning voedt.