Maximum Likelihood Estimation > EM Algorithm (Expectation-maximization)
u wilt misschien eerst dit artikel lezen: Wat is Maximum Likelihood Estimation?
Wat is het em-algoritme?
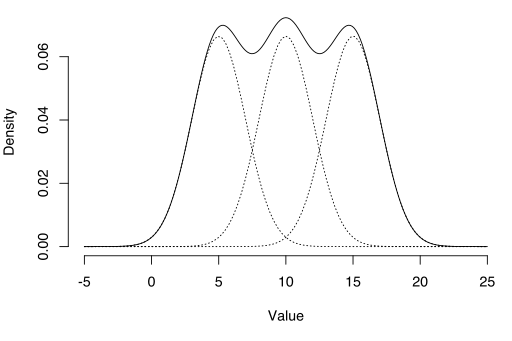
het em algoritme kan worden gebruikt om latente variabelen te schatten, zoals die afkomstig zijn van mengseldistributies (u weet dat ze afkomstig zijn van een mengsel, maar niet welke specifieke distributie).
het Expectation-Maximization (EM) algoritme is een manier om maximale waarschijnlijkheid schattingen voor modelparameters te vinden wanneer uw gegevens onvolledig zijn, ontbrekende gegevenspunten hebben of niet-geobserveerde (verborgen) latente variabelen hebben. Het is een iteratieve manier om de maximale waarschijnlijkheidsfunctie te benaderen. Hoewel maximale waarschijnlijkheid schatting kan vinden van de” best fit ” model voor een set van gegevens, het werkt niet bijzonder goed voor onvolledige datasets. Het complexere EM-algoritme kan modelparameters vinden, zelfs als er gegevens ontbreken. Het werkt door willekeurige waarden te kiezen voor de ontbrekende gegevenspunten, en met behulp van die gissingen om een tweede reeks gegevens te schatten. De nieuwe waarden worden gebruikt om een betere schatting te maken voor de eerste set, en het proces gaat door totdat het algoritme convergeert op een vast punt.
zie ook: em algoritme uitgelegd in één afbeelding.
MLE vs. EM
hoewel Maximum Likelihood Estimation (MLE) en EM beide “best-fit” parameters kunnen vinden, zijn de modellen zeer verschillend. MLE verzamelt alle gegevens eerst en vervolgens gebruikt die gegevens om het meest waarschijnlijke model te construeren. EM neemt een gok op de parameters eerst-rekening houdend met de ontbrekende gegevens—dan tweaks het model om de gissingen en de waargenomen gegevens passen. De basisstappen voor het algoritme zijn:
- een eerste gok wordt gemaakt voor de parameters van het model en een kansverdeling wordt gemaakt. Dit wordt soms de “E-Step” voor de “verwachte” Distributie genoemd.
- Nieuw waargenomen gegevens worden in het model ingevoerd.
- de kansverdeling uit de E-step wordt aangepast om de nieuwe gegevens op te nemen. Dit wordt soms de “M-stap genoemd.”
- stappen 2 tot en met 4 worden herhaald totdat stabiliteit is bereikt (d.w.z. een verdeling die niet verandert van de E-stap naar de M-stap).
het em-algoritme verbetert altijd de schatting van een parameter door dit proces met meerdere stappen. Echter, het moet soms een paar willekeurige start om het beste model te vinden, omdat het algoritme kan slijpen op een lokale maxima die niet zo dicht bij de (optimale) globale maxima. Met andere woorden, het kan beter presteren als je het forceren om opnieuw te starten en neem die “eerste gok” van Stap 1 opnieuw. Uit alle mogelijke parameters, kunt u dan kiezen voor de ene met de grootste maximale waarschijnlijkheid.
in werkelijkheid, de stappen omvatten een aantal vrij zware calculus (integratie) en voorwaardelijke waarschijnlijkheden, die buiten het toepassingsgebied van dit artikel. Als u een meer technische (dat wil zeggen calculus-based) analyse van het proces, Ik beveel u lezen Gupta en Chen ‘ s 2010 paper.
toepassingen
het EM-algoritme heeft vele toepassingen, waaronder:
- verstrengeling van gesuperponeerde signalen,
- het schatten van Gaussiaanse mengmodellen (GGM ‘s),
- het schatten van verborgen Markovmodellen (Hmm’ s),
- het schatten van parameters voor samengestelde dirichletdistributies,
- het vinden van optimale mengsels van vaste modellen.
beperkingen
het em-algoritme kan erg traag zijn, zelfs op de snelste computer. Het werkt het beste als je slechts een klein percentage ontbrekende gegevens hebt en de dimensionaliteit van de gegevens niet te groot is. Hoe hoger de dimensionaliteit, hoe trager de e-step; Voor gegevens met een grotere dimensionaliteit, kunt u vinden dat de E-step extreem langzaam loopt als de procedure een lokaal maximum nadert.
Dempster, A., Laird, N., and Rubin, D. (1977) Maximum likelihood from incomplete data via the EM algorithm, Journal of the Royal Statistical Society. Serie B (Methodological), vol. 39, nr. 1, blz. 1ñ38.
Gupta, M. & Chen, Y. (2010) Theory and Use of the EM Algorithm. Foundations and Trends in Signal Processing, Vol. 4, Nr. 3 223-296.
Stephanie Glen. “EM algoritme (verwachting-maximalisatie): Eenvoudige definitie ” van StatisticsHowTo.com: elementaire statistieken voor de rest van ons! https://www.statisticshowto.com/em-algorithm-expectation-maximization/
——————————————————————————
hulp nodig bij een huiswerk of testvraag? Met Chegg Study krijgt u stap-voor-stap oplossingen voor uw vragen van een expert in het veld. Je eerste 30 minuten met een Chegg tutor is gratis!