u gebruikt misschien al lange tijd Boommodellen of een newbie, maar heeft u zich ooit afgevraagd hoe het eigenlijk werkt en hoe het verschilt van andere algoritmen? Hier, ik deel een korte van mijn afspraken.
CART is ook een voorspellend model dat helpt bij het vinden van een variabele gebaseerd op andere gelabelde variabelen. Om duidelijker te zijn voorspellen de boommodellen de uitkomst door een reeks if-else vragen te stellen. Er zijn twee grote voordelen bij het gebruik van boommodellen,
- ze zijn in staat om de niet-lineariteit in de dataset vast te leggen.
- standaardisatie van gegevens bij gebruik van boommodellen is niet nodig. Omdat ze geen Euclidische afstand of andere meetfactoren tussen data berekenen. Alleen als … anders.
bouten en moeren van bomen

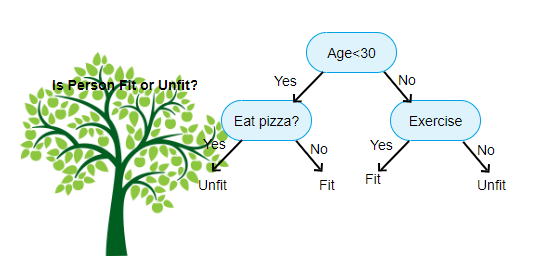
boven weergegeven is een afbeelding van de beslissing boom Classifier, elke ronde staat bekend als knooppunten. Elk knooppunt zal een IF-else clausule hebben gebaseerd op een gelabelde variabele. Op basis van die vraag zal elke instantie van invoer worden gericht/gerouteerd naar een specifieke blad-knoop die de uiteindelijke voorspelling zal vertellen. Er zijn drie soorten knooppunten,
- Root Node: heeft geen ouder node, en geeft twee kinderen node op basis van de vraag
- interne Node: het zal een ouder node hebben, en geeft twee kinderen node
- blad Node: het zal ook een ouder node hebben, maar zal geen kinderen node
het aantal niveaus van we hebben staat bekend als de max_depth. In het bovenstaande diagram max_depth = 3. Naarmate de max_depth toeneemt, zal ook de complexiteit van het model toenemen. Terwijl we trainen als we het verhogen, de training fout zal altijd naar beneden gaan of zal hetzelfde blijven. Maar het kan soms verhogen de testfout. We moeten dus kieskeurig zijn bij het selecteren van de max_depth voor een model.
een andere interessante factor over Node is Informatieversterking(ir). Dit is een criterium dat wordt gebruikt om de zuiverheid van een knoop te meten. De zuiverheid wordt gemeten op basis van hoe slim een knooppunt items kan splitsen. Laten we zeggen dat je op een knooppunt en je wilt gaan of links of rechts. Maar je hebt items behoort tot beide klassen op hetzelfde bedrag (50-50) op elk knooppunt. Dan is de zuiverheid van beide klassen laag omdat je niet weet welke richting je moet kiezen. De een moet hoger zijn dan de ander om een beslissing te nemen. dit is gemeten met behulp van een IR,
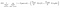

zoals de naam zelf al zegt, is het doel van CART om te voorspellen tot welke klasse een invoer instantie behoort op basis van de gelabelde waarden. Om dit te bereiken zal het besluit regio ‘ s maken met behulp van Beslissingsgrenzen. Stel je voor dat we een 2D dataset hebben,

op deze manier zal het onze multidimensionale dataset scheiden in Beslissingsgebieden op basis van de if-else vragen op elk knooppunt. WINKELWAGENMODELLEN kunnen nauwkeurigere beslissingsgebieden vinden dan lineaire modellen. En de beslissingsgebieden per kar zijn meestal rechthoekig gevormd omdat er slechts één functie betrokken is bij elk knooppunt in de besluitvorming. U kunt het hieronder visualiseren,

ik denk dat het genoeg is van introducties, laten we eens een paar voorbeelden bekijken over hoe je KARMODELLEN kunt bouwen op sikit learn.
Classificatiestructuur
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regressiestructuur
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
hoop dat dit artikel nuttig is, als u discussies of suggesties heeft, laat dan een privébericht achter.