MSE verlies wordt gebruikt voor regressietaken. Zoals de naam al doet vermoeden, wordt dit verlies berekend door het gemiddelde van kwadraatverschillen tussen werkelijke(doel) en voorspelde waarden te nemen.
voorbeeld
bijvoorbeeld, we hebben een neuraal netwerk dat huisgegevens neemt en huizenprijzen voorspelt. In dit geval kunt u het verlies MSE gebruiken. In principe, in het geval dat de output is een reëel getal, moet u deze verlies functie te gebruiken.
binaire Crossentropie
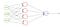
BCE-verlies wordt gebruikt voor de binaire classificatietaken. Als u de loss-functie BCE gebruikt, hebt u slechts één uitvoerknooppunt nodig om de gegevens in twee klassen te classificeren. De uitgangswaarde moet worden doorgegeven via een sigmoid-activeringsfunctie en het bereik van de uitgang is (0-1).
voorbeeld
bijvoorbeeld, we hebben een neuraal netwerk dat atmosfeergegevens neemt en voorspelt of het zal regenen of niet. Als de output groter is dan 0,5, classificeert het netwerk het als rain en als de output kleiner is dan 0,5, classificeert het netwerk het als not rain. (het kan het tegenovergestelde zijn, afhankelijk van hoe je het netwerk traint). Hoe meer de kansscore waarde, hoe meer de kans op regen.
tijdens het trainen van het netwerk moet de aan het netwerk toegevoerde doelwaarde 1 zijn als het anders regent 0.
Note 1
een belangrijk ding, als u BCE loss functie gebruikt, moet de uitvoer van het knooppunt tussen (0-1) liggen. Het betekent dat je een sigmoid activeringsfunctie moet gebruiken op je uiteindelijke output. Sinds sigmoid converteert elke reële waarde in het bereik tussen (0-1).
Note 2
wat als u geen sigmoid-activering gebruikt op de laatste laag? Dan kunt u een argument genaamd from logits als true doorgeven aan de loss-functie en het zal intern de sigmoid toepassen op de uitvoerwaarde.
Categorical Crossentropy
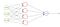
wanneer we een classificatie taak voor meerdere klassen hebben, is een van de verliesfuncties die u kunt uitvoeren deze. Als u de loss-functie CCE gebruikt, moet er hetzelfde aantal uitvoerknooppunten zijn als de klassen. En de uiteindelijke laag output moet worden doorgegeven door middel van een softmax activering, zodat elk knooppunt output een waarschijnlijkheid waarde tussen (0-1).
voorbeeld
bijvoorbeeld, we hebben een neuraal netwerk dat een afbeelding neemt en classificeert in een kat of hond. Als de kat knooppunt heeft een hoge waarschijnlijkheid score dan is het beeld is geclassificeerd in een kat Anders Hond. Kortom, welke klasse node heeft de hoogste waarschijnlijkheid score, de afbeelding is geclassificeerd in die klasse.

om de doelwaarde op het moment van de training te voeden, moeten we ze één-hot coderen. Als het beeld van kat is dan is de doelvector (1, 0) en als het beeld van hond is, is de doelvector (0, 1). In principe zou de doelvector van dezelfde grootte zijn als het aantal klassen en de indexpositie die overeenkomt met de werkelijke klasse zou 1 zijn en alle andere zouden nul zijn.
Note
wat als we geen softmax-activering gebruiken op de laatste laag? Dan kunt u een argument genaamd from logits als true doorgeven aan de loss-functie en het zal intern de softmax toepassen op de uitvoerwaarde. Hetzelfde als in het bovenstaande geval.
schaarse categorische Crossentropie
deze verliesfunctie is vrijwel gelijk aan CCE, op één verandering na.
wanneer we SCCE loss functie gebruiken, hoeft u niet één hot coderen van de doelvector. Als het doelbeeld van een kat is, passeer je gewoon 0, anders 1. Kortom, welke klasse het ook is, je passeert gewoon de index van die klasse.