być może używasz modeli drzewa od dłuższego czasu lub jako początkujący, ale czy zastanawiałeś się kiedyś, jak to działa i czym różni się od innych algorytmów? Tutaj podzielam Krótki opis mojego zrozumienia.
CART jest również modelem predykcyjnym, który pomaga znaleźć zmienną w oparciu o inne oznaczone zmienne. Aby było bardziej jasne, modele drzewa przewidują wynik, zadając zestaw pytań if-else. Istnieją dwie główne zalety korzystania z modeli drzew,
- są w stanie uchwycić Nieliniowość w zbiorze danych.
- nie ma potrzeby standaryzacji danych podczas korzystania z modeli drzew. Ponieważ nie obliczają odległości euklidesowej ani innych czynników pomiarowych między danymi. Tylko jeśli-inaczej.

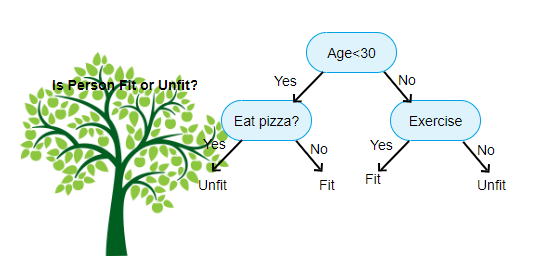
powyżej pokazany jest obraz klasyfikatora drzewa decyzyjnego, każda runda jest znana jako węzły. Każdy węzeł będzie miał klauzulę if-else opartą na zmiennej oznaczonej etykietą. Na podstawie tego pytania każda instancja danych wejściowych będzie kierowana / kierowana do określonego węzła liścia, który powie ostateczne przewidywanie. Istnieją trzy rodzaje węzłów,
- węzeł główny: nie ma żadnego węzła nadrzędnego i daje dwa węzły potomne na podstawie pytania
- węzeł wewnętrzny: będzie miał węzeł nadrzędny i da dwa węzły potomne
- węzeł liściowy: będzie również miał węzeł nadrzędny, ale nie będzie miał żadnych węzłów potomnych
liczba poziomów, które mamy, jest znana jako max_depth. Na powyższym wykresie max_depth = 3. Wraz ze wzrostem max_depth, złożoność modelu również wzrośnie. Podczas treningu, jeśli go zwiększymy, błąd treningowy zawsze spadnie lub pozostanie taki sam. Ale czasami może to zwiększyć błąd testowania. Więc musimy być wybredni wybierając max_depth dla modelu.
innym interesującym czynnikiem związanym z węzłem jest wzmocnienie informacji(ir). Jest to kryterium stosowane do pomiaru czystości węzła. Czystość jest mierzona w oparciu o to, jak sprytny węzeł może dzielić elementy. Załóżmy, że jesteś na węźle i chcesz iść w lewo lub w prawo. Ale masz elementy należące do obu klas w tej samej ilości (50-50) w każdym węźle. Wtedy czystość obu klas jest niska, ponieważ nie wiesz, w którym kierunku wybrać. Jeden musi być wyższy od drugiego, aby podjąć decyzję. jest to mierzone za pomocą podczerwieni,
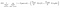

jak sama nazwa mówi, celem CART jest przewidzenie, do której klasy należy instancja wejściowa na podstawie jej oznaczonych wartości. Aby to osiągnąć, regiony decyzyjne będą korzystać z granic decyzji. Wyobraź sobie, że mamy zestaw danych 2D,

w ten sposób podzieli nasz wielowymiarowy zbiór danych na regiony decyzyjne oparte na pytaniach if-else w każdym węźle. Modele wózków mogą znaleźć dokładniejsze regiony decyzyjne niż modele liniowe. A regiony decyzyjne według koszyka są zazwyczaj prostokątne, ponieważ tylko jedna cecha zaangażowana w każdym węźle w podejmowaniu decyzji. Możesz to zwizualizować poniżej,

myślę, że wystarczy wprowadzenia, zobaczmy kilka przykładów na temat budowania modeli wózków na Scikit learn.
drzewo klasyfikacji
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
drzewo regresji
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
mam nadzieję, że ten artykuł jest przydatny, jeśli masz jakieś dyskusje lub sugestie, Zostaw prywatną wiadomość.