MSE loss jest używane do zadań regresji. Jak sama nazwa wskazuje, strata ta jest obliczana na podstawie średniej kwadratowej różnic między wartościami rzeczywistymi(docelowymi) i przewidywanymi.
przykład
na przykład mamy sieć neuronową, która pobiera dane domu i prognozuje cenę domu. W takim przypadku można użyć straty MSE. Zasadniczo, w przypadku, gdy wyjście jest liczbą rzeczywistą, powinieneś użyć tej funkcji straty.
Crossentropia binarna
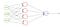
strata BCE jest używana do zadań klasyfikacji binarnej. Jeśli używasz funkcji utraty BCE, wystarczy jeden węzeł wyjściowy, aby sklasyfikować dane na dwie klasy. Wartość wyjściowa powinna być przekazywana przez funkcję aktywacji esicy, a zakres wyjściowy wynosi (0-1).
przykład
na przykład mamy sieć neuronową, która pobiera dane atmosfery i przewiduje, czy będzie padać, czy nie. Jeśli wyjście jest większe niż 0,5, sieć klasyfikuje je jako rain, a jeśli wyjście jest mniejsze niż 0,5, sieć klasyfikuje je jako not rain. (może być odwrotnie w zależności od tego, jak trenujesz sieć). Im większa wartość wyniku prawdopodobieństwa, tym większa szansa na deszcz.
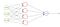
podczas treningu sieci, wartość docelowa podawana do sieci powinna wynosić 1, jeśli pada, w przeciwnym razie 0.
Uwaga 1
jedna ważna rzecz, jeśli używasz funkcji utraty BCE wyjście węzła powinno być pomiędzy (0-1). Oznacza to, że musisz użyć funkcji aktywacji esicy na końcowym wyjściu. Ponieważ sigmoid konwertuje dowolną wartość rzeczywistą z zakresu od (0-1).
Uwaga 2
co jeśli nie używasz aktywacji esicy na ostatniej warstwie? Następnie możesz przekazać argument o nazwie from logits jako true do funkcji loss i wewnętrznie zastosuje esicę do wartości wyjściowej.
Crossentropia kategoryczna
gdy mamy zadanie klasyfikacji wielu klas, jedną z funkcji utraty, którą możesz wykonać, jest ta. Jeśli używasz funkcji utraty CCE, musi być taka sama liczba węzłów wyjściowych jak Klasy. A końcowe wyjście warstwy powinno być przekazywane przez aktywację softmax, tak aby każdy węzeł generował wartość prawdopodobieństwa między (0-1).
przykład
na przykład mamy sieć neuronową, która pobiera obraz i klasyfikuje go do kota lub psa. Jeśli węzeł kota ma wysoki wynik prawdopodobieństwa, obraz jest klasyfikowany do kota inaczej psa. Zasadniczo, niezależnie od tego, który węzeł klasy ma najwyższy wynik prawdopodobieństwa, obraz jest klasyfikowany do tej klasy.

do podawania wartości docelowej w czasie treningu, musimy je zakodować na gorąco. Jeśli obraz jest kota, to docelowy wektor będzie (1, 0), a jeśli obraz jest psa, docelowy wektor będzie (0, 1). Zasadniczo wektor docelowy byłby tej samej wielkości co liczba klas, a pozycja Indeksu odpowiadająca rzeczywistej klasie wynosiłaby 1, a wszystkie inne byłyby równe zero.
Uwaga
co jeśli nie korzystamy z aktywacji softmax na ostatniej warstwie? Następnie możesz przekazać argument o nazwie from logits jako true do funkcji loss i wewnętrznie zastosuje softmax do wartości wyjściowej. Tak samo jak w powyższym przypadku.
oszczędna kategoryczna Crossentropia
ta funkcja utraty jest prawie podobna do CCE z wyjątkiem jednej zmiany.
gdy używamy funkcji utraty SCCE, nie musisz jeden gorący kodować docelowego wektora. Jeśli obraz docelowy jest kota, po prostu przekazać 0, w przeciwnym razie 1. Zasadniczo, niezależnie od klasy, po prostu przekaż indeks tej klasy.