na era dos grandes dados, o desafio não é mais acessar dados suficientes; o desafio é descobrir os dados certos a usar. Num artigo anterior, concentrei-me no valor de dados alternativos, que é um activo de Negócio vital. Mesmo com os benefícios de dados alternativos, no entanto, a granularidade errada dos dados pode minar o ROI da gestão orientada por dados.
“somos tão obcecados com dados, que esquecemos como interpretá-los”. – Danah Boyd, Investigador Principal da Microsoft Research
então, quão perto você deve estar olhando seus dados? Porque a granularidade de dados errada pode custar-lhe mais do que imagina.
simplificando, granularidade dos dados refere-se ao nível de detalhe dos nossos dados. Quanto mais granular seus dados, mais informações contidas em um determinado ponto de dados. Medir transações anuais em todas as lojas de um país teria baixa granularidade, como você saberia muito pouco sobre quando e onde os clientes fazem essas compras. Por outro lado, medir as transacções individuais das lojas pela segunda vez teria uma granularidade incrivelmente elevada.
a granularidade ideal dos dados depende do tipo de análise que você está fazendo. Se você está procurando por padrões no comportamento do consumidor ao longo de décadas, a baixa granularidade é provavelmente boa. Para automatizar a reposição de armazenamento, no entanto, você precisa de muito mais dados granulares.
Quando você escolher o errado granularidade para sua análise, pode acabar com menos precisos e menos útil inteligência. Pense em como a reposição semanal bagunçada da loja baseada apenas em dados anuais de todo o sistema seria! Você experimentaria continuamente tanto o excesso de estoque e estoque, acumulando enormes custos e altos níveis de desperdício no processo. Em qualquer análise, a granularidade errada dos dados pode ter consequências igualmente graves para a sua eficiência e conclusão.Então você está usando a granularidade de dados correta para sua inteligência de negócios? Aqui estão cinco erros de granularidade de dados comuns — e caros—.
agrupar as várias tendências empresariais num único padrão (quando os dados não são suficientemente granulares).
a inteligência de negócios precisa ser clara e direta para ser praticável, mas às vezes, numa tentativa de alcançar a simplicidade, as pessoas não mergulham suficientemente fundo nos dados. É uma pena, porque vais perder ideias valiosas. Quando a granularidade dos dados é muito baixa, você só vê grandes padrões que surgem à superfície. Você pode perder dados críticos.
em demasiados casos, não olhar de perto o suficiente para os seus dados leva a comprimir tendências díspares num único resultado. As empresas que cometem este erro acabam por obter resultados desiguais. Eles são mais propensos a ter imprevisíveis e extremos que não se encaixam no padrão geral — porque esse padrão não reflete a realidade.Este é um problema comum em muitos sistemas tradicionais de previsão da cadeia de suprimentos. Eles não podem lidar com o nível de granularidade necessário para prever a demanda de nível SKU em lojas individuais, o que significa que uma única loja pode estar lidando com tanto overstocks e stockouts ao mesmo tempo. Sistemas automatizados alimentados por AI podem lidar com a complexidade necessária para segmentar adequadamente os dados, o que é uma razão para que estes melhoram a eficiência da cadeia de suprimentos. Granularidade de dados suficiente é fundamental para uma inteligência de negócios mais precisa.

se perder os dados, sem um ponto de foco (quando os dados são muito granular).Alguma vez, acidentalmente, fez um zoom muito longe num mapa online? É tão frustrante! Você não pode fazer nenhuma informação útil porque não há contexto. Isso também acontece nos dados.
se os seus dados são demasiado granulares, perde-se; não consegue concentrar-se o suficiente para encontrar um padrão útil dentro de todos os dados estranhos. É tentador sentir que mais detalhes é sempre melhor quando se trata de dados, mas muito detalhe pode tornar seus dados virtualmente inúteis. Muitos executivos confrontados com tantos dados encontram-se congelados com paralisia de análise. Você acaba com recomendações não confiáveis, uma falta de contexto empresarial e confusão desnecessária.
Muito granular de dados é particularmente caro erro quando se trata AI de previsão. Os dados podem enganar o algoritmo para indicar que ele tem dados suficientes para fazer suposições sobre o futuro que não é possível com a tecnologia de hoje. No meu trabalho de cadeia de suprimentos na Evo, por exemplo, ainda é impossível prever vendas diárias por SKU. A sua margem de erro será demasiado grande para ser útil. Este nível de granularidade mina os objetivos e diminui o ROI.
não escolhendo propositadamente a granularidade das variáveis de tempo.
os erros de granularidade dos dados mais comuns estão relacionados com intervalos de tempo, ou seja, medindo variáveis em uma hora, dia, semana, ano, etc. base. Erros de granularidade Temporal ocorrem muitas vezes por conveniência. A maioria das empresas tem formas padrão de relatar variáveis cronometradas. Parece que seria necessário muito esforço para mudá-los, então eles não mudam. mas esta raramente é a granularidade ideal para resolver o problema analisado.Quando se pondera o custo de mudar a forma como o seu sistema reporta KPIs versus o custo de obter sistematicamente inteligência de negócios inadequada, os benefícios de escolher propositadamente o registo de granularidade certo. Dependendo da granularidade do tempo, você vai reconhecer insights muito diferentes dos mesmos dados. Veja-se, por exemplo, a evolução da sazonalidade no comércio retalhista. Olhar para as transações ao longo de um único dia pode tornar as tendências sazonais invisíveis ou, no mínimo, conter tantos dados que os padrões são apenas ruído branco, enquanto os dados mensais compartilham uma sequência distinta que você pode realmente usar. Se o KPIs padrão ignorar o relatório mensal para ir diretamente para os padrões trimestrais, você perde informações valiosas que tornariam as previsões mais precisas. Não se pode levar o tempo a granularidade ao valor facial se se quiser obter a melhor inteligência.


Overfitting ou underfitting seu modelo para o ponto de que os padrões que você vê são sem sentido.
modelos de IA precisam generalizar bem a partir de dados existentes e futuros para fornecer quaisquer recomendações úteis. Essencialmente, um bom modelo pode olhar este dados:

E assumir isso como um modelo de trabalho com base nas informações:

O padrão não podem perfeitamente representar os dados, mas ele faz um bom trabalho de prever o comportamento típico sem sacrificar a inteligência.
se você não tem a granularidade de dados certa, no entanto, você pode acabar com o modelo errado. Como falamos antes, dados excessivamente granulares podem causar ruído que torna difícil encontrar um padrão. Se seu algoritmo consistentemente treina com este nível de detalhe barulhento, ele vai entregar o ruído por sua vez. Você acaba com um modelo que se parece com isso:

Nós chamamos isso de overfitting seu modelo. Cada ponto de dados tem um impacto enorme, na medida em que o modelo já não pode generalizar-se de forma útil. Os problemas inicialmente causados pela alta granularidade são ampliados e tornam-se um problema permanente no modelo.A granularidade de dados demasiado baixos também pode causar danos a longo prazo ao seu modelo. Um algoritmo deve ter dados suficientes para encontrar padrões. Algoritmos treinados usando dados sem granularidade suficiente perderão padrões críticos. Uma vez que o algoritmo tenha ido além da fase de treinamento, ele continuará a não identificar padrões semelhantes. Você acaba com um modelo que se parece com este:
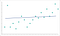
Este é underfitting o modelo. O algoritmo aproxima-se de fazer as previsões certas, mas nunca serão tão precisas como poderiam ter sido. Tal como o sobrefitting, é uma ampliação do problema de granularidade inicial.
quando você está criando um modelo para sua análise, granularidade adequada torna-se exponencialmente mais importante do que uma vez que você tem um algoritmo estável. Por esta razão, muitas empresas optam por terceirizar esta parte do processo para especialistas. É um palco muito delicado e caro para erros.
ajustando completamente a granularidade dos dados incorrectos.
talvez o erro de granularidade dos dados mais dispendioso esteja apenas a concentrar-se tanto na optimização da granularidade do KPIs que actualmente mede que não consegue perceber que são os KPIs errados por completo. Pretendemos alcançar a granularidade correta dos dados não para otimizar qualquer desempenho específico do KPI, mas sim para reconhecer padrões nos dados que fornecem insights realizáveis e valiosos. Se você quiser melhorar a receita, por exemplo, você pode estar prejudicando o seu sucesso apenas olhando para padrões de preços. Estão envolvidos outros factores.Tome um exemplo do meu colega. Um novo cliente Da Evo queria aumentar as vendas, e um teste inicial aplicando nossas ferramentas de cadeia de suprimentos mostrou uma melhoria de 10% em menos de duas semanas. Nosso CEO estava mais do que animado com esses resultados sem precedentes, mas para sua surpresa, o Gerente da cadeia de suprimentos não ficou impressionado. Seu KPI primário era a disponibilidade de produtos, e de acordo com números internos, que nunca tinha mudado. Seu foco em melhorar um KPI em particular veio ao custo de reconhecer insights valiosos de outros dados.


Se o KPI foi medido com precisão, com foco exclusivo em alterar o seu desempenho realizada este gestor de ver o valor em uma nova abordagem. Ele era um homem inteligente agindo de boa fé, mas os dados o enganaram — um erro incrivelmente comum e caro. A granularidade correta dos dados é vital, mas não pode ser um objetivo em si mesmo. Você tem que olhar para o quadro maior para maximizar seus retornos de IA. Como você olha de perto seus dados não importará se você não tiver os dados certos em primeiro lugar.
“uma falácia comum da Gestão Baseada em dados é usar os dados errados para responder à pergunta certa”. – Fabrizio Fantini, fundador e CEO da Evo
the benefits of the right data granularity
There’s no magic bullet when it comes to data granularity. Você deve escolher cuidadosamente e intencionalmente para evitar estes e outros erros menos comuns. A única maneira de maximizar os retornos de seus dados é olhar para ele criticamente-geralmente com a ajuda de um cientista de dados especialista. É provável que não tenha granularidade na sua primeira tentativa, por isso, precisa de testar e ajustar-se até estar perfeito.Mas vale a pena o esforço. Olhando de perto, mas não muito de perto, seus dados garantem a inteligência de negócios ideal. Segmentado e analisado corretamente, os dados se transformam em uma vantagem competitiva com a qual você pode contar.