a perda de MSE é usada para tarefas de regressão. Como o nome sugere, esta perda é calculada tomando a média das diferenças quadradas entre os valores reais(alvo) e previstos.
exemplo
por exemplo, temos uma rede neural que pega dados da casa e prevê o preço da casa. Neste caso, você pode usar a perda MSE. Basicamente, no caso em que a saída é um número real, você deve usar esta função de perda.
Binário Crossentropy
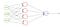
A.C. perda é utilizado para a classificação binária tarefas. Se você está usando BCE função de perda, você só precisa de um nó de saída para classificar os dados em duas classes. O valor de saída deve ser passado através de uma função de ativação sigmoid e o intervalo de saída é (0 – 1).
exemplo
por exemplo, temos uma rede neural que pega dados da atmosfera e prevê se vai chover ou não. Se a saída for maior que 0.5, a rede classifica-a como rain e se a saída for menor que 0.5, a rede classifica-a como not rain. (pode ser oposto dependendo de como você treinar a rede). Mais o valor da pontuação de probabilidade, mais a chance de chover.
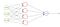
Durante o treinamento da rede, o valor de destino alimentados para que a rede deve ser 1, se estiver chovendo, caso contrário, 0.
Nota 1
uma coisa importante, se você está usando BCE função de perda a saída do nó deve ser entre (0-1). Significa que você tem que usar uma função de ativação sigmoid em sua saída final. Uma vez que sigmoid converte qualquer valor real no intervalo entre (0-1).
Nota 2
e se não estiver a utilizar a activação sigmóide na camada final? Então você pode passar um argumento chamado from logits como true para a função de perda e ele irá aplicar internamente o sigmoid para o valor de saída.
Crossentropia categórica
quando temos uma tarefa de classificação multi-classe, uma das funções de perda que você pode seguir em frente é esta. Se você está usando CCE função de perda, deve haver o mesmo número de nós de saída que as classes. E a saída final da camada deve ser passada através de uma ativação softmax de modo que cada nó saída um valor de probabilidade entre (0-1).
exemplo
por exemplo, nós temos uma rede neural que pega uma imagem e classifica-a em um gato ou cão. Se o nó do gato tem uma pontuação de alta probabilidade, em seguida, a imagem é classificada em um gato caso contrário cão. Basicamente, qualquer nó de classe que tenha a maior pontuação de probabilidade, a imagem é classificada nessa classe.

Para alimentar o valor alvo no momento de formação, para um quente codificá-los. Se a imagem é de gato, então o vetor alvo seria (1, 0) e se a imagem é de cão, o vetor alvo seria (0, 1). Basicamente, o vetor alvo seria do mesmo tamanho que o número de classes e a posição de índice correspondente à classe real seria 1 e todos os outros seriam zero.
Nota
e se não estivermos a usar a activação de softmax na camada final? Então você pode passar um argumento chamado from logits como true para a função de perda e ele irá aplicar internamente o softmax ao valor de saída. O mesmo que no caso acima.
Crossentropia esparsa categórica
esta função de perda é quase semelhante a CCE excepto por uma alteração.
quando estamos usando SCCE função de perda, você não precisa de um codificar quente o vetor alvo. Se a imagem de destino é de um gato, você simplesmente passar 0, caso contrário 1. Basicamente, seja qual for a classe, basta passar o índice dessa classe.