Você pode estar usando os modelos de Árvore por um longo tempo ou um novato, mas, você já se perguntou como realmente ele funciona e como ele é diferente de outros algoritmos? Aqui, eu compartilho um breve de meus entendimentos.
CART é também um modelo preditivo que ajuda a encontrar uma variável baseada em outras variáveis rotuladas. Para ser mais claro, os modelos de árvores prevêem o resultado, fazendo um conjunto de perguntas if-else. Existem duas grandes vantagens na utilização de modelos de árvores,
- eles são capazes de capturar a não linearidade no conjunto de dados.
- não há necessidade de padronização de dados quando se utilizam modelos de árvores. Porque eles não calculam qualquer distância euclidiana ou outros fatores de medição entre os dados. Se … se não.
Porcas e Parafusos de Árvores

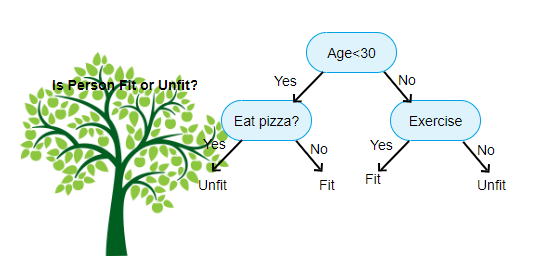
Acima é mostrada uma imagem da Árvore de Decisão do Classificador, cada rodada é conhecida como Nós. Cada nó terá uma cláusula if-else baseada em uma variável rotulada. Com base nessa pergunta cada instância de entrada será direcionada/direcionada para um nó folha específico que dirá a predição final. Existem três tipos de nós,
- Nó Raiz: não tem qualquer nó pai, e lhe dá dois filhos, de nós com base na pergunta
- Nó Interno: ele vai ter um nó pai, e dá dois nós filhos
- Nó Folha: ele também vai ter um nó pai, mas não tenho filhos, nós
O número de níveis de nós tem é conhecido como o max_depth. No diagrama acima, max_depth = 3. À medida que o max_depth aumenta, a complexidade do modelo também irá aumentar. Enquanto treinamos se o aumentarmos, o erro de treinamento sempre irá cair ou permanecerá o mesmo. Mas às vezes pode aumentar o erro de teste. Então temos que ser exigentes ao selecionar o max_depth para um modelo.
outro fator interessante sobre o nó é o ganho de informação (IR). Este é um critério usado para medir a pureza de um nó. A pureza é medida com base no quão inteligente um nó pode dividir itens. Digamos que estás num nó e queres ir para a esquerda ou para a direita. Mas você tem itens pertence a ambas as classes na mesma quantidade (50-50) em cada nó. Então a pureza de ambas as classes é baixa porque você não sabe qual direção escolher. Um tem de ser mais alto do que o outro para tomar uma decisão. este é medido usando-se IR,
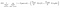

como o próprio nome diz, O objetivo do CART é prever a que classe uma instância de entrada pertence com base em seus valores rotulados. Para conseguir isso, fará regiões de decisão usando limites de decisão. Imagine que temos um conjunto de dados 2D,

assim, ele vai separar a nossa multidimensional conjunto de dados para a Tomada de Regiões com base no if-else perguntas em cada nó. Os modelos CART podem encontrar regiões de decisão mais precisas do que modelos lineares. E as regiões de decisão por CART são tipicamente retangulares porque, apenas uma característica envolvida em cada nó na tomada de decisão. Você pode visualizar abaixo,

eu acho que é o suficiente das introduções, vamos ver alguns exemplos de como construir CARRINHO de modelos em Scikit aprender.
Árvore de Classificação
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Árvore de Regressão
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Espero que este artigo seja útil, se você tiver quaisquer discussões ou sugestões, por favor deixe uma nota privada.