pierderea MSE este utilizată pentru sarcini de regresie. După cum sugerează și numele, această pierdere este calculată luând media diferențelor pătrate între valorile reale(țintă) și cele prezise.
exemplu
de exemplu, avem o rețea neuronală care preia datele casei și prezice prețul casei. În acest caz, puteți utiliza pierderea MSE. Practic, în cazul în care ieșirea este un număr real, ar trebui să utilizați această funcție de pierdere.
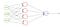
Crossentropie binară
pierderea BCE este utilizată pentru sarcinile de clasificare binară. Dacă utilizați funcția de pierdere BCE, aveți nevoie doar de un nod de ieșire pentru a clasifica datele în două clase. Valoarea de ieșire trebuie trecută printr – o funcție de activare sigmoidă, iar intervalul de ieșire este (0-1).
exemplu
de exemplu, avem o rețea neuronală care preia date despre atmosferă și prezice dacă va ploua sau nu. Dacă ieșirea este mai mare de 0,5, Rețeaua o clasifică ca rain și dacă ieșirea este mai mică de 0,5, Rețeaua o clasifică ca not rain. (ar putea fi opus în funcție de modul în care antrenezi rețeaua). Mai mult valoarea scorului de probabilitate, cu atât mai mult șansa de a ploua.
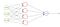
în timp ce rețeaua de formare, valoarea țintă alimentat la rețea ar trebui să fie 1 dacă plouă altfel 0.
Nota 1
un lucru important, dacă utilizați BCE funcția de pierdere ieșirea nodului ar trebui să fie între (0-1). Aceasta înseamnă că trebuie să utilizați o funcție de activare sigmoid pe ieșire finală. Deoarece sigmoid convertește orice valoare reală în intervalul dintre (0-1).
Nota 2
ce se întâmplă dacă nu utilizați activarea sigmoid pe stratul final? Apoi puteți trece un argument numit from logits ca true la funcția de pierdere și va aplica intern sigmoidul la valoarea de ieșire.
Crossentropy categorică
când avem o sarcină de clasificare multi-clasă, una dintre funcția de pierdere puteți merge mai departe este aceasta. Dacă utilizați CCE funcția de pierdere, trebuie să existe același număr de noduri de ieșire ca clasele. Și ieșirea stratului final ar trebui să fie trecut printr-o activare softmax, astfel încât fiecare nod de ieșire o valoare de probabilitate între (0-1).
exemplu
de exemplu, avem o rețea neuronală care ia o imagine și o clasifică într-o pisică sau un câine. Dacă nodul pisică are un scor de probabilitate mare, atunci imaginea este clasificată într-o pisică altfel câine. Practic, oricare nod de clasă are cel mai mare scor de probabilitate, imaginea este clasificată în acea clasă.

pentru alimentarea valorii țintă în momentul antrenamentului, trebuie să le codificăm la cald. Dacă imaginea este de pisică, atunci vectorul țintă ar fi (1, 0) și dacă imaginea este de câine, vectorul țintă ar fi (0, 1). Practic, vectorul țintă ar avea aceeași dimensiune ca numărul de clase, iar poziția indexului corespunzătoare clasei reale ar fi 1 și toate celelalte ar fi zero.
notă
ce se întâmplă dacă nu folosim activarea softmax pe stratul final? Apoi puteți trece un argument numit from logits ca true la funcția de pierdere și va aplica intern softmax la valoarea de ieșire. La fel ca în cazul de mai sus.
Crossentropy categorică rară
această funcție de pierdere este aproape similară cu CCE cu excepția unei modificări.
când folosim SCCE funcția de pierdere, nu aveți nevoie să o codifica la cald vectorul țintă. Dacă imaginea țintă este a unei pisici, pur și simplu treceți 0, altfel 1. Practic, oricare ar fi clasa, treci doar indicele acelei clase.