în epoca datelor mari, provocarea nu mai este accesarea unor date suficiente; provocarea este găsirea datelor potrivite pentru utilizare. Într-un articol trecut, m-am concentrat pe valoarea datelor alternative, care este un atu vital pentru afaceri. Cu toate acestea, chiar și cu beneficiile datelor alternative, granularitatea greșită a datelor poate submina rentabilitatea investiției în gestionarea bazată pe date.
„suntem atât de obsedați de date, încât uităm cum să le interpretăm”. – Danah Boyd, cercetător principal la Microsoft Research
deci, cât de atent ar trebui să vă uitați la datele dvs.? Deoarece granularitatea greșită a datelor vă poate costa mai mult decât vă dați seama.
mai simplu spus, granularitatea datelor se referă la nivelul de detaliu al datelor noastre. Cu cât datele dvs. sunt mai granulare, cu atât mai multe informații conținute într-un anumit punct de date. Măsurarea tranzacțiilor anuale în toate magazinele dintr-o țară ar avea o granularitate scăzută, deoarece știți foarte puțin despre momentul și locul în care clienții fac aceste achiziții. Măsurarea tranzacțiilor magazinelor individuale cu cea de-a doua, pe de altă parte, ar avea o granularitate incredibil de mare.
granularitatea ideală a datelor depinde de tipul de analiză pe care o faceți. Dacă sunteți în căutarea unor modele în comportamentul consumatorilor de-a lungul deceniilor, granularitatea scăzută este probabil bună. Cu toate acestea, pentru a automatiza reaprovizionarea magazinului, veți avea nevoie de date mult mai granulare.
când alegeți granularitatea greșită pentru analiza dvs., veți ajunge la o inteligență mai puțin precisă și mai puțin utilă. Gândiți-vă cât de dezordonată ar fi reaprovizionarea săptămânală a magazinului bazată doar pe date anuale la nivel de sistem! Veți experimenta continuu atât stocul în exces, cât și stocurile, acumulând costuri uriașe și niveluri ridicate de deșeuri în acest proces. În orice analiză, granularitatea greșită a datelor poate avea consecințe la fel de grave pentru eficiența și linia de jos.
deci, utilizați granularitatea corectă a datelor pentru informațiile dvs. de afaceri? Iată cinci greșeli comune și costisitoare de granularitate a datelor.
gruparea mai multor tendințe de afaceri într-un singur model (atunci când datele nu sunt suficient de granulare).
business intelligence trebuie să fie clar și direct pentru a putea fi acționat, dar uneori, în încercarea de a obține simplitate, oamenii nu se scufundă suficient de adânc în date. Este o rușine pentru că veți pierde informații valoroase. Când granularitatea datelor este prea mică, vedeți doar modele mari care apar la suprafață. Este posibil să pierdeți date critice.
în prea multe cazuri, a nu privi suficient de atent datele dvs. duce la comprimarea tendințelor disparate într-un singur rezultat. Întreprinderile care fac această greșeală ajung să aibă rezultate inegale. Este mai probabil să aibă valori imprevizibile și extreme care nu se potrivesc modelului general — deoarece acest model nu reflectă realitatea.
aceasta este o problemă comună în multe sisteme tradiționale de prognoză a lanțului de aprovizionare. Ei nu pot face față nivelului de granularitate necesar pentru a prezice cererea la nivel de SKU în magazinele individuale, ceea ce înseamnă că un singur magazin poate avea de-a face atât cu suprapuneri, cât și cu stocuri în același timp. Sistemele automate alimentate de AI pot gestiona complexitatea necesară pentru segmentarea corectă a datelor, motiv pentru care acestea îmbunătățesc eficiența lanțului de aprovizionare. Granularitatea suficientă a datelor este esențială pentru o inteligență de afaceri mai precisă.

se pierde în date fără un punct de focalizare (când datele sunt prea granulare).
ați mărit vreodată accidental prea mult într-o hartă online? Este atât de frustrant! Nu poți face orice informații utile pentru că nu există nici un context. Acest lucru se întâmplă și în date.
dacă datele dvs. sunt prea granulare, vă pierdeți; nu vă puteți concentra suficient pentru a găsi un model util în toate datele străine. Este tentant să simți că mai multe detalii sunt întotdeauna mai bune atunci când vine vorba de date, dar prea multe detalii pot face datele tale practic inutile. Mulți directori care se confruntă cu atât de multe date se găsesc înghețați de paralizia analizei. Veți termina cu recomandări nesigure, o lipsă de context de afaceri și confuzie inutilă.
datele prea granulare sunt o greșeală deosebit de costisitoare atunci când vine vorba de prognozarea AI. Datele pot păcăli algoritmul pentru a indica faptul că are suficiente date pentru a face presupuneri despre viitor, ceea ce nu este posibil cu tehnologia de astăzi. În activitatea mea în lanțul de aprovizionare la Evo, de exemplu, este încă imposibil să prognozez vânzările zilnice pe SKU. Marja dvs. de eroare va fi prea mare pentru a fi utilă. Acest nivel de granularitate subminează obiectivele și diminuează rentabilitatea investiției.
nu alege granularitatea variabilelor de timp în mod intenționat.
cele mai frecvente greșeli de granularitate a datelor sunt legate de intervale de timp, adică măsurarea variabilelor pe oră, zilnic, săptămânal, anual etc. bază. Greșelile de granularitate temporală apar adesea din motive de comoditate. Majoritatea companiilor au modalități standard de a raporta variabilele temporizate. Se pare că ar necesita prea mult efort pentru a le schimba, așa că nu. dar aceasta este rareori granularitatea ideală pentru a aborda problema analizată.
când cântăriți costul schimbării modului în care sistemul dvs. raportează KPI față de costul obținerii în mod constant a informațiilor de afaceri inadecvate, beneficiile alegerii intenționate a registrului de granularitate potrivit. În funcție de granularitatea timpului, veți recunoaște informații foarte diferite din aceleași date. Luați tendințele de sezonalitate în comerțul cu amănuntul, de exemplu. Analiza tranzacțiilor pe parcursul unei singure zile ar putea face tendințele sezoniere invizibile sau, cel puțin, să conțină atât de multe date încât modelele sunt doar zgomot alb, în timp ce datele lunare împărtășesc o secvență distinctă pe care o puteți utiliza efectiv. Dacă indicatorii KPI standard omit raportarea lunară pentru a trece direct la tiparele trimestriale, pierdeți informații valoroase care ar face previziunile mai precise. Nu puteți lua granularitatea timpului la valoarea nominală dacă doriți să obțineți cea mai bună inteligență.


Overfitting sau underfitting modelul dvs. până la punctul în care modelele pe care le vedeți sunt lipsite de sens.
modelele AI trebuie să generalizeze bine din datele existente și viitoare pentru a oferi recomandări utile. În esență, un model bun ar putea privi aceste date:

și să presupunem acest lucru ca un model de lucru bazat pe informații:

este posibil ca modelul să nu reprezinte perfect datele, dar face o treabă bună prezicând comportamentul tipic fără a sacrifica prea multă inteligență.
dacă nu aveți granularitatea corectă a datelor, totuși, puteți ajunge la un model greșit. Așa cum am vorbit înainte, datele prea granulare pot provoca zgomot care face dificilă găsirea unui model. Dacă algoritmul dvs. se antrenează în mod constant cu acest nivel de detaliu zgomotos, acesta va produce zgomot la rândul său. Ajungi cu un model care arată astfel:

noi numim acest overfitting modelul dumneavoastră. Fiecare punct de date are un impact supradimensionat, în măsura în care modelul nu mai poate generaliza util. Problemele cauzate inițial de granularitatea ridicată sunt mărite și au devenit o problemă permanentă în model.
granularitatea prea mică a datelor poate provoca, de asemenea, daune pe termen lung modelului dvs. Un algoritm trebuie să aibă suficiente date pentru a găsi modele. Algoritmii instruiți folosind date fără suficientă granularitate vor lipsi tiparele critice. Odată ce algoritmul a trecut dincolo de faza de antrenament, acesta va continua să nu identifice modele similare. Ajungi cu un model care arată astfel:
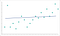
acest lucru este subfitting modelul. Algoritmul se apropie de a face predicțiile corecte, dar nu vor fi niciodată la fel de exacte pe cât ar fi putut fi. Ca și suprasolicitarea, este o mărire a problemei inițiale a granularității.
când creați un model pentru analiza dvs., granularitatea adecvată devine exponențial mai importantă decât odată ce aveți un algoritm stabil. Din acest motiv, multe companii aleg să externalizeze această parte a procesului către experți. Este o etapă prea delicată și costisitoare pentru greșeli.
ajustarea granularitatea datelor incorecte în întregime.
poate că cea mai costisitoare greșeală de granularitate a datelor se concentrează atât de mult pe optimizarea granularității KPI-urilor pe care le măsurați în prezent, încât nu reușiți să vă dați seama că sunt KPI-uri greșite în întregime. Ne propunem să obținem granularitatea corectă a datelor nu pentru a optimiza performanța KPI specifică, ci mai degrabă pentru a recunoaște tiparele din date care oferă informații acționabile și valoroase. Dacă doriți să îmbunătățiți veniturile, de exemplu, este posibil să vă subminați succesul doar analizând modelele de stabilire a prețurilor. Sunt implicați și alți factori.
luați un exemplu de la colegul meu. Un nou client Evo a dorit să crească vânzările, iar un test inițial care a aplicat instrumentele lanțului nostru de aprovizionare a arătat o îmbunătățire de 10% în mai puțin de două săptămâni. CEO-ul nostru a fost dincolo de entuziasmat de aceste rezultate fără precedent, dar spre surprinderea sa, managerul lanțului de aprovizionare nu a fost impresionat. KPI-ul său principal a fost disponibilitatea produselor și, conform numerelor interne, acest lucru nu s-a schimbat niciodată. Concentrarea sa pe îmbunătățirea unui anumit KPI a venit cu prețul recunoașterii unor informații valoroase din alte date.


indiferent dacă KPI a fost sau nu măsurat cu exactitate, concentrându-se în întregime pe schimbarea performanței sale, acest manager a împiedicat să vadă valoarea într-o nouă abordare. Era un om inteligent care acționa cu bună credință, dar datele l — au indus în eroare-o greșeală incredibil de comună, dar costisitoare. Granularitatea corectă a datelor este vitală, dar nu poate fi un obiectiv în sine. Trebuie să te uiți la imaginea de ansamblu pentru a maximiza randamentele de la AI. Cât de atent vă uitați la datele dvs. nu va conta dacă nu aveți datele corecte în primul rând.
„o eroare comună a gestionării bazate pe date este utilizarea datelor greșite pentru a răspunde la întrebarea corectă”. – Fabrizio Fantini, fondator și CEO al Evo
beneficiile granularității corecte a datelor
nu există niciun glonț magic atunci când vine vorba de granularitatea datelor. Trebuie să o alegeți cu atenție și intenționat pentru a evita aceste și alte greșeli mai puțin frecvente. Singura modalitate de a maximiza randamentele din datele dvs. este să le priviți critic — de obicei cu ajutorul unui expert în date. Probabil că nu veți obține granularitate chiar la prima încercare, așa că trebuie să testați și să ajustați până când este perfect.
merită efortul, totuși. Privind atent, dar nu prea atent, datele dvs. asigură informații de afaceri optime. Segmentate și analizate corect, datele se transformă într-un avantaj competitiv pe care te poți baza.