este posibil să fi folosit modele de arbori de mult timp sau un începător, dar v-ați întrebat vreodată cum funcționează de fapt și cum este diferit de alți algoritmi? Aici, împărtășesc o scurtă de înțelegerile mele.
CART este, de asemenea, un model predictiv care ajută la găsirea unei variabile bazate pe alte variabile etichetate. Pentru a fi mai clar, modelele de arbori prezic rezultatul punând un set de întrebări if-else. Există două avantaje majore în utilizarea modelelor de arbori,
- ei sunt capabili să surprindă neliniaritatea în setul de date.
- nu este nevoie de standardizare a datelor atunci când se utilizează modele de arbori. Deoarece nu calculează nicio distanță euclidiană sau alți factori de măsurare între date. Doar dacă-altceva.
piulițe și șuruburi de arbori

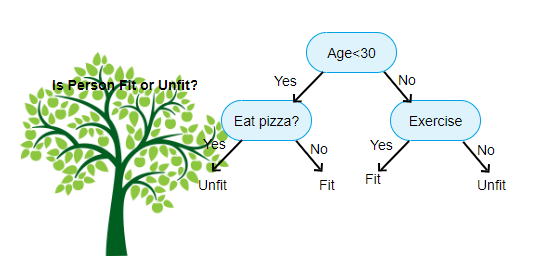
mai sus este prezentată o imagine a Clasificatorului arborelui de decizie, fiecare rundă fiind cunoscută sub numele de noduri. Fiecare nod va avea o clauză if-else bazată pe o variabilă etichetată. Pe baza acestei întrebări, fiecare instanță de intrare va fi direcționată/direcționată către un anumit nod de frunze care va spune predicția finală. Există trei tipuri de noduri,
- nod rădăcină: nu are nici un nod părinte, și dă doi copii noduri bazate pe întrebarea
- nod intern: acesta va avea un nod părinte, și dă doi copii noduri
- nod frunze: acesta va avea, de asemenea, un nod părinte, dar nu va avea nici copii noduri
numărul de niveluri de noi are este cunoscut sub numele de max_depth. În diagrama de mai sus max_depth = 3. Pe măsură ce max_depth crește, complexitatea modelului va crește, de asemenea. În timp ce ne antrenăm dacă o mărim, eroarea de antrenament va scădea întotdeauna sau va rămâne aceeași. Dar uneori poate crește eroarea de testare. Deci, trebuie să fie choosy atunci când selectarea max_depth pentru un model.
un alt factor interesant despre nod este câștigul de informații (IR). Acesta este un criteriu folosit pentru a măsura puritatea unui nod. Puritatea se măsoară în funcție de cât de inteligent un nod poate împărți elemente. Să presupunem că sunteți la un nod și doriți să mergeți fie la stânga, fie la dreapta. Dar aveți elemente aparține ambelor clase la aceeași sumă (50-50) la fiecare nod. Atunci puritatea ambelor clase este scăzută, deoarece nu știți ce direcție să alegeți. Unul trebuie să fie mai înalt decât celălalt pentru a lua o decizie. acest lucru este măsurat folosind IR,
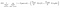

după cum spune și numele, scopul CART este de a prezice la ce clasă aparține o instanță de intrare pe baza valorilor sale etichetate. Pentru a realiza acest lucru se va face regiuni de decizie folosind limitele de decizie. Imaginați-vă că avem un set de date 2D,

astfel, va separa setul nostru de date multidimensionale în regiuni de decizie bazate pe întrebările if-else de la fiecare nod. Modelele de cărucioare pot găsi regiuni de decizie mai precise decât modelele liniare. Și regiunile de decizie de CART sunt de obicei în formă dreptunghiulară, deoarece, doar o caracteristică implicate la fiecare nod în luarea deciziilor. O puteți vizualiza mai jos,

cred că este suficient de introduceri, să vedem câteva exemple despre cum să construim modele de coș pe scikit learn.
arborele de clasificare
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
arborele de regresie
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Sper că acest articol este util, dacă aveți discuții sau sugestii, vă rugăm să lăsați o notă privată.