i en ålder av big data, utmaningen är inte längre tillgång till tillräckligt med data; utmaningen är att räkna ut rätt data att använda. I en tidigare artikel fokuserade jag på värdet av alternativa data, vilket är en viktig affärstillgång. Även med fördelarna med alternativa data kan dock fel datagranularitet undergräva avkastningen på datadriven hantering.
”vi är så besatta av data, vi glömmer hur vi tolkar det”. – Danah Boyd, huvudforskare vid Microsoft Research
så hur nära ska du titta på dina data? Eftersom fel datagranularitet kan kosta dig mer än du inser.
enkelt uttryckt hänvisar datagranularitet till detaljnivån i våra data. Ju mer detaljerade dina data, desto mer information finns i en viss datapunkt. Att mäta årliga transaktioner i alla butiker i ett land skulle ha låg granularitet, eftersom du skulle veta väldigt lite om när och var kunderna gör dessa inköp. Att mäta enskilda butikers transaktioner med den andra, å andra sidan, skulle ha otroligt hög granularitet.
den ideala datagranulariteten beror på vilken typ av analys du gör. Om du letar efter mönster i konsumentbeteende under årtionden är låg granularitet förmodligen bra. För att automatisera butiksuppfyllning behöver du dock mycket mer granulär data.
när du väljer fel granularitet för din analys får du mindre exakt och mindre användbar intelligens. Tänk på hur rörigt veckovis butiksuppfyllning baserat endast på årliga systemövergripande data skulle vara! Du skulle kontinuerligt uppleva både överskottslager och lager, samla enorma kostnader och höga avfallsnivåer i processen. I varje analys, fel data granularitet kan ha liknande allvarliga konsekvenser för din effektivitet och bottom line.
så använder du rätt datagranularitet för din business intelligence? Här är fem vanliga-och kostsamma – datagranularitetsfel.
Gruppera flera affärstrender i ett enda mönster (när data inte är tillräckligt granulära).
Business intelligence måste vara tydlig och okomplicerad för att vara handlingsbar, men ibland i ett försök att uppnå enkelhet dyker människor inte tillräckligt djupt in i data. Det är synd eftersom du kommer att sakna värdefulla insikter. När datagranulariteten är för låg ser du bara stora mönster som uppstår på ytan. Du kan sakna kritiska data.
i alltför många fall leder inte tillräckligt nära dina data till att komprimera olika trender till ett enda resultat. Företag som gör detta misstag hamnar med ojämna resultat. De är mer benägna att ha oförutsägbara och extrema avvikare som inte passar det övergripande mönstret — eftersom det mönstret inte återspeglar verkligheten.
detta är ett vanligt problem i många traditionella prognossystem för försörjningskedjor. De kan inte hantera den granularitet som krävs för att förutsäga efterfrågan på SKU-nivå i enskilda butiker, vilket innebär att en enda butik kan hantera både överstockar och lager samtidigt. Automatiserade system som drivs av AI kan hantera den komplexitet som krävs för att korrekt segmentera data, vilket är en anledning till att dessa förbättrar effektiviteten i försörjningskedjan. Tillräcklig data granularitet är avgörande för mer exakt business intelligence.

att gå vilse i data utan fokus (när data är för granulär).
har du någonsin oavsiktligt zoomat alldeles för långt in i en karta online? Det är så frustrerande! Du kan inte ta fram någon användbar information eftersom det inte finns något sammanhang. Det händer också i data.
om dina data är för granulära går du vilse; du kan inte fokusera tillräckligt för att hitta ett användbart mönster inom alla externa data. Det är frestande att känna att mer detaljer alltid är bättre när det gäller data, men för mycket detaljer kan göra dina data praktiskt taget värdelösa. Många chefer som står inför så mycket data befinner sig frusna med analysförlamning. Du slutar med opålitliga rekommendationer, brist på affärssammanhang och onödig förvirring.
för granulära data är ett särskilt kostsamt misstag när det gäller AI-prognoser. Uppgifterna kan lura algoritmen för att indikera att den har tillräckligt med data för att göra antaganden om framtiden som inte är möjliga med dagens teknik. I mitt supply chain-arbete på Evo är det till exempel fortfarande omöjligt att förutse daglig försäljning per SKU. Din felmarginal kommer att vara för stor för att vara användbar. Denna nivå av granularitet undergräver mål och minskar avkastningen.
väljer inte granulariteten för tidsvariabler målmedvetet.
de vanligaste datagranularitetsfelen är relaterade till tidsintervall, dvs mätvariabler på en timme, dagligen, veckovis, årligen etc. grundval. Temporala granularitetsfel uppstår ofta för bekvämlighetens skull. De flesta företag har vanliga sätt att rapportera tidsvariabler. Det känns som om det skulle kräva för mycket ansträngning för att ändra dem, så de gör det inte. men det här är sällan den perfekta granulariteten för att ta itu med det analyserade problemet.
när du väger kostnaden för att ändra hur ditt system rapporterar KPI: er jämfört med kostnaden för att konsekvent få otillräcklig affärsinformation, fördelarna med att målmedvetet välja rätt granularitetsregister. Beroende på tidens granularitet kommer du att känna igen mycket olika insikter från samma data. Ta säsongstrender i detaljhandeln, till exempel. Att titta på transaktioner över en enda dag kan göra säsongsbetonade trender osynliga eller åtminstone innehålla så mycket data att mönster bara är vitt brus, medan månadsdata delar en distinkt sekvens som du faktiskt kan använda. Om standard KPI: er hoppar över månadsrapportering för att gå direkt till kvartalsmönster förlorar du värdefulla insikter som skulle göra prognoserna mer exakta. Du kan inte ta tid granularitet till nominellt värde om du vill få den bästa intelligensen.


Overfitting eller underfitting din modell till den grad att de mönster du ser är meningslösa.
AI-modeller måste generalisera väl från befintliga och framtida data för att leverera användbara rekommendationer. I huvudsak kan en bra modell titta på dessa data:

och anta detta som en arbetsmodell baserad på informationen:

mönstret kanske inte perfekt representerar data, men det gör ett bra jobb att förutsäga typiskt beteende utan att offra för mycket intelligens.
om du inte har rätt datagranularitet kan du dock sluta med fel modell. Som vi pratade om tidigare kan alltför granulära data orsaka brus som gör det svårt att hitta ett mönster. Om din algoritm konsekvent tränar med denna bullriga detaljnivå kommer den att leverera ljud i sin tur. Du slutar med en modell som ser ut så här:

vi kallar detta overfitting din modell. Varje datapunkt har en stor inverkan, i den utsträckning att modellen inte kan generalisera användbart längre. Problemen som ursprungligen orsakades av hög granularitet förstoras och gjorde ett permanent problem i modellen.
för låg datagranularitet kan också göra långsiktiga skador på din modell. En algoritm måste ha tillräckliga data för att hitta mönster. Algoritmer utbildade med hjälp av data utan tillräcklig granularitet kommer att sakna kritiska mönster. När algoritmen har gått bortom träningsfasen fortsätter den att misslyckas med att identifiera liknande mönster. Du slutar med en modell som ser ut så här:
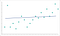
detta är undermontering av modellen. Algoritmen kommer nära att göra rätt förutsägelser, men de kommer aldrig att vara så exakta som de kunde ha varit. Liksom överfitting är det en förstoring av det ursprungliga granularitetsproblemet.
när du skapar en modell för din analys blir korrekt granularitet exponentiellt viktigare än när du har en stabil algoritm. Av denna anledning väljer många företag att lägga ut denna del av processen till experter. Det är för känsligt och dyrt ett steg för misstag.
justera granulariteten för felaktiga data helt.
kanske är det mest kostsamma datagranularitetsfelet bara att fokusera så mycket på att optimera granulariteten hos KPI: er som du för närvarande mäter att du inte inser att de är fel KPI: er helt. Vi strävar efter att uppnå rätt datakornighet för att inte optimera någon specifik KPI-prestanda utan snarare att känna igen mönster i data som ger handlingsbara och värdefulla insikter. Om du till exempel vill förbättra intäkterna kan du undergräva din framgång genom att bara titta på mönster i prissättningen. Andra faktorer är inblandade.
ta ett exempel från min kollega. En ny Evo-kund ville öka försäljningen, och ett första test med våra Supply Chain-verktyg visade en förbättring på 10% på mindre än två veckor. Vår VD var bortom upphetsad av dessa oöverträffade resultat, men till hans förvåning var supply chain manager inte imponerad. Hans primära KPI var produkttillgänglighet, och enligt interna siffror, som aldrig hade förändrats. Hans fokus på att förbättra en viss KPI kom på bekostnad av att känna igen värdefulla insikter från andra data.


huruvida KPI mättes korrekt eller inte, med fokus helt på att ändra prestanda, höll den här chefen tillbaka från att se värdet i ett nytt tillvägagångssätt. Han var en smart man som agerade i god tro, men uppgifterna vilseledda honom — ett otroligt vanligt men dyrt misstag. Korrekt datagranularitet är avgörande, men det kan inte vara ett mål i sig själv. Du måste titta på den större bilden för att maximera din avkastning från AI. Hur nära du tittar på dina data spelar ingen roll om du inte har rätt data i första hand.
”en vanlig felaktighet i datadriven hantering är att använda fel data för att svara på rätt fråga”. – Fabrizio Fantini, grundare och VD för Evo
fördelarna med rätt data granularitet
det finns ingen magisk kula när det gäller data granularitet. Du måste välja det noggrant och avsiktligt för att undvika dessa och andra mindre vanliga misstag. Det enda sättet att maximera avkastningen från dina data är att titta på det kritiskt-vanligtvis med en expertdatavetenskapares hjälp. Du kommer sannolikt inte att få granularitet direkt vid ditt första försök, så du måste testa och justera tills det är perfekt.
det är dock värt ansträngningen. När du tittar noga, men inte för nära, säkerställer dina data optimal affärsinformation. Segmenterad och analyserad korrekt förvandlas data till en konkurrensfördel du kan lita på.