maximal sannolikhetsbedömning > em-algoritm (förväntan-maximering)
du kanske vill läsa den här artikeln först: Vad är maximal sannolikhetsbedömning?
Vad är Em-algoritmen?
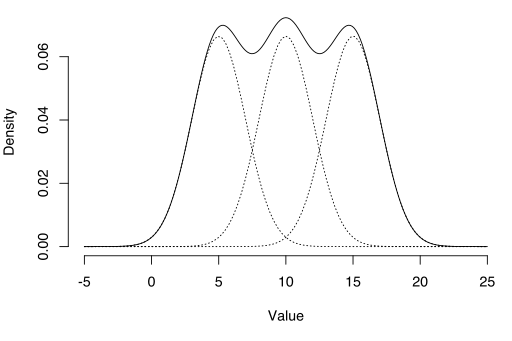
EM-algoritmen kan användas för att uppskatta latenta variabler, som de som kommer från blandningsfördelningar (du vet att de kom från en blandning, men inte vilken specifik distribution).
Förväntningsmaximeringsalgoritmen (em) är ett sätt att hitta uppskattningar av maximal sannolikhet för modellparametrar när dina data är ofullständiga, saknar datapunkter eller har obemärkta (dolda) latenta variabler. Det är ett iterativt sätt att approximera maximal sannolikhetsfunktion. Medan maximal sannolikhetsbedömning kan hitta” best fit ” – modellen för en uppsättning data, fungerar det inte särskilt bra för ofullständiga datamängder. Den mer komplexa em-algoritmen kan hitta modellparametrar även om du saknar data. Det fungerar genom att välja slumpmässiga värden för de saknade datapunkterna och använda dessa gissningar för att uppskatta en andra uppsättning data. De nya värdena används för att skapa en bättre gissning för den första uppsättningen, och processen fortsätter tills algoritmen konvergerar på en fast punkt.
Se även: em-algoritmen förklaras i en bild.
MLE vs. EM
även om Maximum Likelihood Estimation (MLE) och EM båda kan hitta ”best-fit” Parametrar, hur de hittar modellerna är väldigt olika. MLE ackumulerar all data först och använder sedan den data för att konstruera den mest troliga modellen. EM tar en gissning på parametrarna först-redogör för de saknade data—sedan tweaks modellen för att passa gissningarna och de observerade data. De grundläggande stegen för algoritmen är:
- en första gissning görs för modellens parametrar och en sannolikhetsfördelning skapas. Detta kallas ibland ” E-Step ”för den” förväntade ” distributionen.
- nyligen observerade data matas in i modellen.
- sannolikhetsfördelningen Från e-steget justeras för att inkludera de nya data. Detta kallas ibland ” m-steget.”
- steg 2 till 4 upprepas tills stabilitet (dvs. en fördelning som inte ändras från E-steg till M-steg) uppnås.
em-algoritmen förbättrar alltid en parameters uppskattning genom denna flerstegsprocess. Men det behöver ibland några slumpmässiga börjar hitta den bästa modellen eftersom algoritmen kan finslipa på en lokal maxima som inte är så nära den (optimala) globala maxima. Med andra ord kan det fungera bättre om du tvingar det att starta om och ta den ”initiala gissningen” från Steg 1 igen. Från alla möjliga parametrar kan du sedan välja den med störst maximal sannolikhet.
i verkligheten innebär stegen några ganska tunga beräkningar (integration) och villkorliga sannolikheter, vilket ligger utanför ramen för denna artikel. Om du behöver en mer teknisk (dvs. kalkylbaserad) uppdelning av processen rekommenderar jag starkt att du läser Gupta och Chens 2010-papper.
applikationer
em-algoritmen har många applikationer, inklusive:
- dis-entangling överlagrade signaler,
- uppskatta gaussiska blandningsmodeller (GMM),
- uppskatta dolda Markov-modeller (hmm),
- uppskatta parametrar för sammansatta Dirichlet-fördelningar,
- hitta optimala blandningar av fasta modeller.
begränsningar
em-algoritmen kan vara mycket långsam, även på den snabbaste datorn. Det fungerar bäst när du bara har en liten andel saknade data och datans dimensionalitet inte är för stor. Ju högre dimensionalitet, desto långsammare e-steg; för data med större dimension kan det hända att E-step går extremt långsamt när proceduren närmar sig ett lokalt maximum.
Dempster, A., Laird, N. och Rubin, D. (1977) maximal sannolikhet från ofullständiga data via EM-algoritmen, Journal of the Royal Statistical Society. Serie B (metodologisk), vol. 39, nr 1, s.1 cu. 38.
Gupta, M. & Chen, Y. (2010) teori och användning av EM-algoritmen. Stiftelser och trender inom signalbehandling, Vol. 4, nr 3 223-296.
Stephanie Glen. ”Em-algoritm (förväntan-maximering): Enkel Definition ” från StatisticsHowTo.com: grundläggande statistik för resten av oss! https://www.statisticshowto.com/em-algorithm-expectation-maximization/
——————————————————————————
behöver du hjälp med en läxa eller testfråga? Med Chegg Study kan du få steg-för-steg-lösningar på dina frågor från en expert på området. Dina första 30 minuter med en Chegg-handledare är gratis!