du kanske har använt Trädmodeller länge eller en nybörjare men har du någonsin undrat hur det faktiskt fungerar och hur det skiljer sig från andra algoritmer? Här, jag delar en kort av mina förståelser.
CART är också en prediktiv modell som hjälper till att hitta en variabel baserad på andra märkta variabler. För att vara tydligare förutsäger trädmodellerna resultatet genom att ställa en uppsättning if-else-frågor. Det finns två stora fördelar med att använda trädmodeller,
- de kan fånga icke-linjäriteten i datasetet.
- inget behov av standardisering av data vid användning av trädmodeller. Eftersom de inte beräknar något euklidiskt avstånd eller andra mätfaktorer mellan data. Bara om-annars.
muttrar och bultar av träd

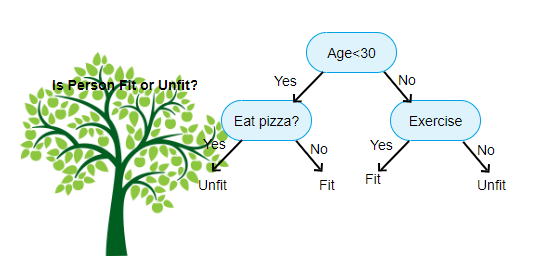
ovan visas en bild av beslutsträd klassificerare, varje runda är känd som noder. Varje nod kommer att ha en If-else-klausul baserad på en märkt variabel. Baserat på den frågan kommer varje instans av inmatning att riktas/dirigeras till en specifik bladnod som kommer att berätta den slutliga förutsägelsen. Det finns tre typer av noder,
- rotnod: har ingen överordnad nod och ger två barnnoder baserat på frågan
- intern nod: den kommer att ha en överordnad nod och ger två barnnoder
- Bladnod: den kommer också att ha en överordnad nod, men kommer inte att ha några barnnoder
antalet nivåer av Vi har är känt som max_depth. I ovanstående diagram max_depth = 3. När max_depth ökar kommer modellens komplexitet också att öka. Medan vi tränar om vi ökar det, kommer träningsfelet alltid att gå ner eller förbli detsamma. Men det kan ibland öka testfelet. Så vi måste vara kräsna när vi väljer max_depth för en modell.
en annan intressant faktor om nod Är Information gain(IR). Detta är ett kriterium som används för att mäta renheten hos en nod. Renhet mäts baserat på hur smart en nod kan dela objekt. Låt oss säga att du är på en nod och du vill gå antingen vänster eller höger. Men du har objekt tillhör båda klasserna på samma belopp (50-50) vid varje nod. Då är renheten i båda klasserna låg eftersom du inte vet vilken riktning du ska välja. Man måste vara högre än den andra för att fatta ett beslut. detta mäts med hjälp av IR,
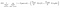

som namnet själv säger är målet med CART att förutsäga vilken klass en inmatningsinstans tillhör baserat på dess märkta värden. För att uppnå detta kommer det att göra Beslutsregioner med Beslutsgränser. Tänk dig att vi har en 2D-dataset,

så här kommer det att separera vår flerdimensionella dataset i Beslutsregioner baserat på if-else-frågorna vid varje nod. CART-modeller kan hitta mer exakta beslutsregioner än linjära modeller. Och beslutsregionerna med vagn är vanligtvis rektangulära eftersom endast en funktion är involverad vid varje nod i beslutsfattandet. Du kan visualisera det nedan,

jag tycker att det räcker med introduktioner, låt oss se några exempel på hur man bygger VAGNMODELLER på Scikit learn.
Klassificeringsträd
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regressionsträd
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
hoppas att den här artikeln är användbar, om du har några diskussioner eller förslag, Lämna en privat anteckning.