i en alder af big data, udfordringen er ikke længere adgang nok data; udfordringen er at finde ud af de rigtige data til at bruge. I en tidligere artikel fokuserede jeg på værdien af alternative data, som er et vigtigt forretningsaktiv. Selv med fordelene ved alternative data kan den forkerte datagranularitet imidlertid underminere ROI for datadrevet styring.
“vi er så besat af data, vi glemmer, hvordan vi skal fortolke det”. – Danah Boyd, hovedforsker ved Microsoft Research
så hvor tæt skal du se på dine data? Fordi den forkerte datagranularitet kan koste dig mere, end du er klar over.
kort sagt henviser datagranularitet til detaljeringsniveauet i vores data. Jo mere granulære dine data er, jo flere oplysninger findes i et bestemt datapunkt. Måling af årlige transaktioner på tværs af alle butikker i et land ville have lav granularitet, som du ville vide meget lidt om, hvornår og hvor kunderne foretager disse køb. Måling af individuelle butikkers transaktioner med den anden ville på den anden side have utrolig høj granularitet.
den ideelle datagranularitet afhænger af den slags analyse, du laver. Hvis du leder efter mønstre i forbrugeradfærd i årtier, er lav granularitet sandsynligvis fint. For at automatisere butikspåfyldning har du dog brug for meget mere granulære data.
når du vælger den forkerte granularitet til din analyse, ender du med mindre nøjagtig og mindre nyttig intelligens. Tænk på, hvor rodet ugentlig butikspåfyldning kun baseret på årlige systemdækkende data ville være! Du vil løbende opleve både overskydende lager og lager, samle enorme omkostninger og høje niveauer af affald i processen. I enhver analyse kan den forkerte datagranularitet have tilsvarende alvorlige konsekvenser for din effektivitet og bundlinje.
så bruger du den korrekte datagranularitet til din business intelligence? Her er fem almindelige — og dyre-data granularitetsfejl.
gruppering af flere forretningstendenser i et enkelt mønster (når data ikke er granulære nok).
Business intelligence skal være klar og ligetil at være Handlingsrettede, men nogle gange i et forsøg på at opnå enkelhed, folk ikke dykke dybt nok ind i data. Det er en skam, fordi du vil gå glip af værdifuld indsigt. Når datagranulariteten er for lav, ser du kun store mønstre, der opstår til overfladen. Du kan gå glip af kritiske data.
i alt for mange tilfælde fører ikke at se tæt nok på dine data til at komprimere forskellige tendenser til et enkelt resultat. Virksomheder, der begår denne fejl, ender med ujævne resultater. De er mere tilbøjelige til at have uforudsigelige og ekstreme outliers, der ikke passer til det overordnede mønster — fordi det mønster ikke afspejler virkeligheden.
dette er et almindeligt problem i mange traditionelle forsyningskædeprognosesystemer. De kan ikke håndtere det granularitetsniveau, der er nødvendigt for at forudsige efterspørgsel på SKU-niveau i individuelle butikker, hvilket betyder, at en enkelt butik muligvis har at gøre med både overstocks og stockouts på samme tid. Automatiserede systemer drevet af AI kan håndtere den kompleksitet, der kræves for at segmentere data korrekt, hvilket er en af grundene til, at disse forbedrer effektiviteten i forsyningskæden. Tilstrækkelig datagranularitet er afgørende for mere præcis business intelligence.

at gå tabt i dataene uden et fokuspunkt (når data er for granulære).
har du nogensinde ved et uheld gået alt for langt ind i et kort online? Det er så frustrerende! Du kan ikke finde ud af nogen nyttige oplysninger, fordi der ikke er nogen sammenhæng. Det sker også i data.
hvis dine data er for granulære, går du tabt; du kan ikke fokusere nok til at finde et nyttigt mønster inden for alle de fremmede data. Det er fristende at føle, at flere detaljer altid er bedre, når det kommer til data, men for meget detaljer kan gøre dine data næsten ubrugelige. Mange ledere står over for så meget data befinder sig frosset med analyse lammelse. Du ender med upålidelige anbefalinger, mangel på forretningskontekst og unødvendig forvirring.
for granulære data er en særlig dyr fejl, når det kommer til AI-prognoser. Dataene kan narre algoritmen til at indikere, at den har nok data til at antage antagelser om fremtiden, som ikke er mulig med nutidens teknologi. I mit forsyningskædearbejde hos Evo er det for eksempel stadig umuligt at forudsige det daglige salg pr. Din fejlmargin vil være for stor til at være nyttig. Dette niveau af granularitet underminerer mål og mindsker ROI.
vælger ikke granulariteten af tidsvariabler målrettet.
de mest almindelige datagranularitetsfejl er relateret til tidsintervaller, dvs.måling af variabler på en time, dagligt, ugentligt, årligt osv. grundlag. Tidsmæssige granularitetsfejl opstår ofte for nemheds skyld. De fleste virksomheder har standardmåder til at rapportere tidsbestemte variabler. Det føles som om det ville kræve for meget indsats for at ændre dem, så de ikke gør det. men dette er sjældent den ideelle granularitet til at løse det analyserede problem.
når du vejer omkostningerne ved at ændre den måde, dit system rapporterer KPI ‘ er i forhold til omkostningerne ved konsekvent at få utilstrækkelig business intelligence, fordelene ved målrettet at vælge det rigtige granularitetsregister. Afhængig af tidens granularitet vil du genkende meget forskellige indsigter fra de samme data. Tag sæsonudsving tendenser i detail, for eksempel. At se på transaktioner over en enkelt dag kan gøre sæsonmæssige tendenser usynlige eller i det mindste indeholde så mange data, at mønstre kun er hvid støj, mens månedlige data deler en særskilt sekvens, du rent faktisk kan bruge. Hvis standard KPI ‘ er springer månedlig rapportering over for at gå direkte til kvartalsvise mønstre, mister du værdifuld indsigt, der ville gøre prognoserne mere nøjagtige. Du kan ikke tage tid granularitet til pålydende værdi, hvis du ønsker at få den bedste intelligens.


Overfitting eller underfitting din model til det punkt, at de mønstre, du ser, er meningsløse.
AI-modeller skal generalisere godt fra eksisterende og fremtidige data for at levere nyttige anbefalinger. I det væsentlige kunne en god model se på disse data:

og antag dette som en arbejdsmodel baseret på informationen:

mønsteret repræsenterer muligvis ikke dataene perfekt, men det gør et godt stykke arbejde med at forudsige typisk adfærd uden at ofre for meget intelligens.
hvis du ikke har den rigtige datagranularitet, kan du dog ende med den forkerte model. Som vi talte om før, kan alt for granulære data forårsage støj, der gør det vanskeligt at finde et mønster. Hvis din algoritme konsekvent træner med dette støjende detaljeringsniveau, leverer den støj igen. Du ender med en model, der ser sådan ud:

vi kalder dette overfitting din model. Hvert datapunkt har en overdreven indvirkning, i det omfang modellen ikke længere kan generalisere nyttigt. De problemer, der oprindeligt skyldes høj granularitet, forstørres og gøres til et permanent problem i modellen.
for lav datagranularitet kan også gøre langvarig skade på din model. En algoritme skal have tilstrækkelige data til at finde mønstre. Algoritmer, der er trænet ved hjælp af data uden tilstrækkelig granularitet, vil gå glip af kritiske mønstre. Når algoritmen er flyttet ud over træningsfasen, vil den fortsat undlade at identificere lignende mønstre. Du ender med en model, der ser sådan ud:
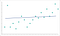
dette er underfitting modellen. Algoritmen kommer tæt på at lave de rigtige forudsigelser, men de vil aldrig være så nøjagtige som de kunne have været. Ligesom overmontering er det en forstørrelse af det oprindelige granularitetsproblem.
når du opretter en model til din analyse, bliver korrekt granularitet eksponentielt vigtigere, end når du først har en stabil algoritme. Af denne grund vælger mange virksomheder at outsource denne del af processen til eksperter. Det er for delikat og dyrt et stadium for fejl.
justering af granulariteten af de forkerte data helt.
måske er den dyreste datagranularitetsfejl blot at fokusere så meget på at optimere granulariteten af KPI ‘er, du i øjeblikket måler, at du ikke indser, at de er de forkerte KPI’ er helt. Vi tilstræber at opnå den korrekte datagranularitet for ikke at optimere nogen specifik KPI-ydeevne, men snarere at genkende mønstre i dataene, der leverer handlingsbar og værdifuld indsigt. Hvis du for eksempel vil forbedre indtægterne, kan du underminere din succes ved kun at se på mønstre i prisfastsættelsen. Andre faktorer er involveret.
Tag et eksempel fra min kollega. En ny Evo-klient ønskede at øge salget, og en indledende test, der anvendte vores Forsyningskædeværktøjer, viste en forbedring på 10% på mindre end to uger. Vores administrerende direktør var meget begejstret over disse hidtil usete resultater, men til hans overraskelse var supply chain manager ikke imponeret. Hans primære KPI var produkttilgængelighed, og ifølge interne tal havde det aldrig ændret sig. Hans fokus på at forbedre en bestemt KPI kom på bekostning af at genkende værdifuld indsigt fra andre data.


hvorvidt KPI blev målt nøjagtigt, fokuserede udelukkende på at ændre dens ydeevne, holdt denne manager tilbage fra at se værdien i en ny tilgang. Han var en smart mand, der handlede i god tro, men dataene vildledte ham — en utrolig almindelig, men alligevel dyr fejltagelse. Korrekt datagranularitet er afgørende, men det kan ikke være et mål i sig selv. Du skal se på det større billede for at maksimere dit afkast fra AI. Hvor tæt du ser på dine data, betyder ikke noget, hvis du ikke har de rigtige data i første omgang.
“en almindelig fejlslutning af datadrevet ledelse bruger de forkerte data til at besvare det rigtige spørgsmål”. – Fabio Fantini, grundlægger og Administrerende Direktør for Evo
fordelene ved den rigtige datagranularitet
der er ingen magisk kugle, når det kommer til datagranularitet. Du skal vælge det omhyggeligt og med vilje for at undgå disse og andre mindre almindelige fejl. Den eneste måde at maksimere afkastet fra dine data er at se kritisk på det — normalt med en ekspert dataforskers hjælp. Du får sandsynligvis ikke granularitet lige ved dit første forsøg, så du skal teste og justere, indtil det er perfekt.
det er dog værd at gøre. Når du ser nøje, men ikke for tæt, sikrer dine data optimal forretningsinformation. Segmenteret og analyseret korrekt, data omdannes til en konkurrencemæssig fordel, du kan stole på.