Diferenciální výraz analýzy znamená, že normáln číst údaje o počtu a provedení statistické analýzy zjistit kvantitativní změny v expresi úrovni mezi experimentálními skupinami. Používáme například statistické testování, abychom rozhodli, zda je u daného genu pozorovaný rozdíl v počtech čtení významný, to znamená, zda je větší než to, co by se dalo očekávat právě díky přirozené náhodné variaci.
Metody pro diferenciální výraz analýzy
Existují různé metody pro diferenciální výraz analýzy jako rozhrnovacích a DESeq na základě negativní binomické (NB) distribuce nebo baySeq a EBSeq, které jsou Bayesovské přístupy založené na negativní binomický model. Při výběru metody analýzy je důležité zvážit experimentální návrh. Zatímco některé nástroje diferenciálního výrazu mohou provádět pouze párové srovnání, jiné jako edgeR, limma-voom, DESeq a maSigPro mohou provádět více srovnání.
na obrázku 11, níže, jsme nastínit RNA-seq processing pipeline použitý pro generování dat pro Expression Atlas.
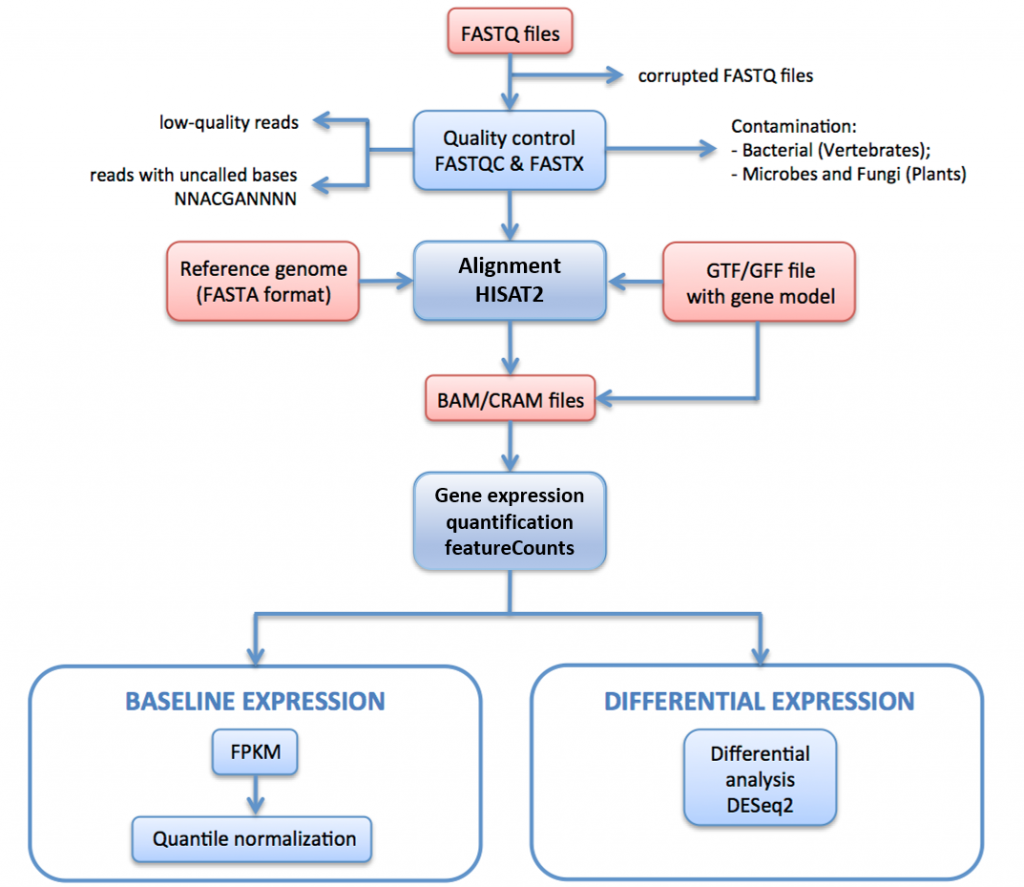
v tomto potrubí raw čte (FASTQ soubory) podstoupit hodnocení kvality a filtrování. Kvalita filtrované čtení jsou zarovnány s referenčním genomem přes HISAT2. Mapované čtení jsou shrnuty a agregovány přes geny prostřednictvím HTSeq. Pro základní expresi jsou FPKMs vypočteny ze surových počtů pomocí iRAP. Ty jsou zprůměrovány pro každou sadu technických replikátů a poté kvantil normalizován v každé sadě biologických replikátů pomocí Limmy.