La pérdida de MSE se utiliza para tareas de regresión. Como su nombre indica, esta pérdida se calcula tomando la media de las diferencias cuadradas entre los valores reales(objetivo) y predichos.
Ejemplo
Por ejemplo, tenemos una red neuronal que toma datos de la casa y predice el precio de la casa. En este caso, puede usar la pérdida MSE. Básicamente, en el caso de que la salida sea un número real, debe usar esta función de pérdida.
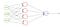
Crossentropy Binario
La pérdida BCE se utiliza para las tareas de clasificación binaria. Si está utilizando la función de pérdida BCE, solo necesita un nodo de salida para clasificar los datos en dos clases. El valor de salida debe pasarse a través de una función de activación sigmoide y el rango de salida es (0 – 1).
Ejemplo
Por ejemplo, tenemos una red neuronal que toma datos de la atmósfera y predice si lloverá o no. Si la salida es superior a 0,5, la red la clasifica como rain y si la salida es inferior a 0,5, la red la clasifica como not rain. (podría ser lo contrario, dependiendo de cómo entrenes la red). Cuanto mayor sea el valor de la puntuación de probabilidad, mayor será la probabilidad de llover.
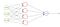
Mientras se entrena la red, el valor objetivo que se alimenta a la red debe ser 1 si llueve, de lo contrario, 0.
Nota 1
Una cosa importante, si está utilizando la función de pérdida BCE, la salida del nodo debe estar entre (0-1). Significa que tienes que usar una función de activación sigmoide en tu salida final. Dado que sigmoid convierte cualquier valor real en el rango entre (0-1).
Nota 2
¿Qué pasa si no está utilizando la activación sigmoide en la capa final? Luego puede pasar un argumento llamado from logits como true a la función de pérdida y aplicará internamente el sigmoide al valor de salida.
Crossentropy categórico
Cuando tenemos una tarea de clasificación de varias clases, una de las funciones de pérdida que puede seguir adelante es esta. Si está utilizando la función de pérdida CCE, debe haber el mismo número de nodos de salida que las clases. Y la salida de la capa final debe pasarse a través de una activación de softmax para que cada nodo genere un valor de probabilidad entre (0-1).
Ejemplo
Por ejemplo, tenemos una red neuronal que toma una imagen y la clasifica en un gato o un perro. Si el nodo gato tiene una puntuación de probabilidad alta, la imagen se clasifica en un gato o perro. Básicamente, cualquiera que sea el nodo de clase que tenga la puntuación de probabilidad más alta, la imagen se clasifica en esa clase.

Para la alimentación del valor objetivo en el momento de la formación, tenemos a uno caliente codifican. Si la imagen es de gato, el vector de destino sería (1, 0) y si la imagen es de perro, el vector de destino sería (0, 1). Básicamente, el vector de destino sería del mismo tamaño que el número de clases y la posición de índice correspondiente a la clase real sería 1 y todas las demás serían cero.
Nota
¿Y si no utilizamos la activación softmax en la capa final? Luego puede pasar un argumento llamado from logits como true a la función de pérdida y aplicará internamente el softmax al valor de salida. Igual que en el caso anterior.
Crossentropy categórico Disperso
Esta función de pérdida es casi similar a CCE excepto por un cambio.
Cuando estamos utilizando la función de pérdida SCCE, no es necesario codificar en caliente el vector de destino. Si la imagen de destino es de un gato, simplemente pasa 0, de lo contrario 1. Básicamente, cualquiera que sea la clase, simplemente pasa el índice de esa clase.