Es posible que haya estado utilizando modelos de árbol durante mucho tiempo o un novato, pero, ¿alguna vez se ha preguntado cómo funciona realmente y cómo es diferente de otros algoritmos? Aquí, comparto un breve resumen de mis entendimientos.
CART es también un modelo predictivo que ayuda a encontrar una variable basada en otras variables etiquetadas. Para ser más claros, los modelos de árbol predicen el resultado al hacer un conjunto de preguntas si no. Hay dos ventajas principales en el uso de modelos de árbol,
- Son capaces de capturar la no linealidad en el conjunto de datos.
- No es necesario estandarizar los datos cuando se utilizan modelos de árbol. Porque no calculan ninguna distancia euclidiana u otros factores de medición entre los datos. Sólo if-else.
Tuercas y pernos de árboles

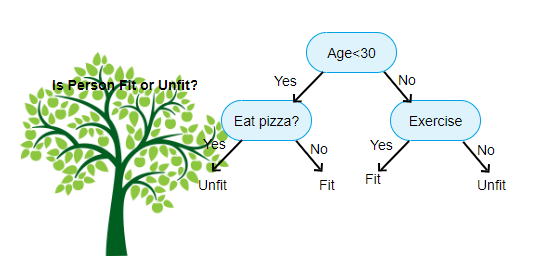
Arriba se muestra una imagen del Clasificador de Árbol de Decisión, cada ronda se conoce como Nodos. Cada nodo tendrá una cláusula if-else basada en una variable etiquetada. Basado en esa pregunta, cada instancia de entrada será dirigida / enrutada a un nodo hoja específico que dirá la predicción final. Hay tres tipos de nodos,
- Nodo raíz: no tiene ningún nodo padre, y da dos nodos hijos basados en la pregunta
- Nodo interno: tendrá un nodo padre, y da dos nodos hijos
- Nodo Hoja: también tendrá un nodo padre, pero no tendrá nodos hijos
El número de niveles que tenemos se conoce como max_depth. En el diagrama anterior max_depth = 3. A medida que aumenta el max_depth, la complejidad del modelo también aumentará. Mientras entrenamos si lo aumentamos, el error de entrenamiento siempre bajará o permanecerá igual. Pero a veces puede aumentar el error de prueba. Así que tenemos que ser exigentes al seleccionar el max_depth para un modelo.
Otro factor interesante sobre el nodo es la ganancia de información (IR). Este es un criterio utilizado para medir la pureza de un Nodo. La pureza se mide en función de lo inteligente que un nodo puede dividir elementos. Digamos que estás en un nodo y quieres ir a la izquierda o a la derecha. Pero tiene elementos que pertenecen a ambas clases en la misma cantidad (50-50) en cada nodo. Entonces la pureza de ambas clases es baja porque no sabes en qué dirección elegir. Uno tiene que ser más alto que el otro para tomar una decisión. esto se mide a través de INFRARROJOS,
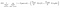

Como dice el propio nombre, el objetivo de CART es predecir a qué clase pertenece una instancia de entrada en función de sus valores etiquetados. Para lograr esto, tomará Regiones de Decisión utilizando Límites de Decisión. Imagine que tenemos un conjunto de datos 2D,

así, separará nuestro conjunto de datos multidimensional en Regiones de decisión basadas en las preguntas if-else en cada nodo. Los modelos de carro pueden encontrar regiones de decisión más precisas que los modelos lineales. Y las regiones de decisión por CARRO son típicamente rectangulares porque, solo una característica involucrada en cada nodo en la toma de decisiones. Usted puede visualizar a continuación,

creo que basta de introducciones, vamos a ver algunos ejemplos sobre cómo construir modelos de CARRITO en Scikit aprender.
Árbol de clasificación
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Árbol de regresión
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
Espero que este artículo sea útil, si tiene alguna discusión o sugerencia, deje una nota privada.