du har muligvis brugt træmodeller i lang tid eller en nybegynder, men har du nogensinde spekuleret på, hvordan det faktisk fungerer, og hvordan det adskiller sig fra andre algoritmer? Her, jeg deler en kort af mine forståelser.
CART er også en forudsigelig model, der hjælper med at finde en variabel baseret på andre mærkede variabler. For at være mere klar forudsiger træmodellerne resultatet ved at stille et sæt if-else-spørgsmål. Der er to store fordele ved at bruge træmodeller,
- de er i stand til at fange den ikke-linearitet i datasættet.
- Intet behov for Standardisering af data ved brug af træmodeller. Fordi de ikke beregner nogen euklidisk afstand eller andre målefaktorer mellem data. Bare hvis-ellers.
møtrikker og bolte af træer

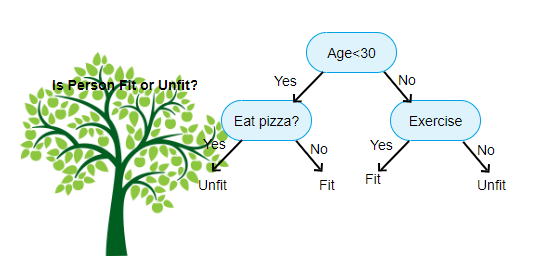
ovenfor vist er et billede af Decision Tree Classifier, hver runde er kendt som noder. Hver node har en If-else-klausul baseret på en mærket variabel. Baseret på dette spørgsmål vil hver forekomst af input blive rettet/dirigeret til en bestemt bladknude, der fortæller den endelige forudsigelse. Der er tre typer noder,
- Root Node: har ikke nogen forælder node, og giver to børn noder baseret på spørgsmålet
- intern Node: det vil have en forælder node, og giver to børn noder
- Leaf Node: det vil også have en forælder node, men vil ikke have nogen børn noder
antallet af niveauer af vi har er kendt som maks_depth. I ovenstående diagram maks_dybde = 3. Da maks_dybden stiger, vil modelkompleksiteten også stige. Mens vi træner, hvis vi øger det, vil træningsfejlen altid gå ned eller forblive den samme. Men det kan nogle gange øge testfejlen. Så vi skal være kræsne, når vi vælger maks_dybden for en model.
en anden interessant faktor om Node er Information gain(ir). Dette er et kriterium, der bruges til at måle renheden af en knude. Renhed måles ud fra, hvor smart en node kan opdele elementer. Lad os sige, at du er ved en knude, og du vil gå enten til venstre eller højre. Men du har elementer tilhører begge klasser på samme beløb (50-50) på hver node. Derefter er renheden i begge klasser lav, fordi du ikke ved, hvilken retning du skal vælge. Den ene skal være højere end den anden for at træffe en beslutning. dette måles ved hjælp af IR,
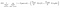

som navnet selv siger, er målet med CART at forudsige, hvilken klasse en inputinstans tilhører, baseret på dens mærkede værdier. For at opnå dette vil det træffe Beslutningsregioner ved hjælp af Beslutningsgrænser. Forestil dig, at vi har et 2D-datasæt,

som dette vil det adskille vores multidimensionelle datasæt i Beslutningsregioner baseret på if-else-spørgsmålene ved hver node. VOGNMODELLER kan finde mere nøjagtige beslutningsregioner end lineære modeller. Og beslutningsregionerne efter vogn er typisk rektangulære, fordi kun en funktion involveret ved hver knude i beslutningsprocessen. Du kan visualisere det nedenfor,

jeg synes, det er nok af introduktioner, lad os se nogle eksempler på, hvordan man bygger VOGNMODELLER på Scikit learn.
Klassificeringstræ
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
Regressionstræ
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
håber, at denne artikel er nyttig, hvis du har diskussioner eller forslag, bedes du efterlade en privat note.