a nagy adatok korában a kihívás már nem elegendő adat elérése; a kihívás a megfelelő adatok kitalálása. Egy korábbi cikkben az alternatív adatok értékére összpontosítottam, amely létfontosságú üzleti eszköz. Még az alternatív adatok előnyeivel is, a helytelen adatgrafikáció alááshatja az adatvezérelt menedzsment megtérülését.
“annyira megszállottak vagyunk az adatokkal, hogy elfelejtjük értelmezni őket”. – Danah Boyd, a Microsoft Research vezető kutatója
tehát mennyire kell alaposan megnéznie az adatait? Mivel a rossz adatok részletessége többe kerülhet, mint gondolnád.
egyszerűen fogalmazva, az adatok részletessége az adataink részletességének szintjére utal. Minél részletesebb az adat, annál több információt tartalmaz egy adott adatpont. Az éves tranzakciók mérése az ország összes üzletében alacsony részletességgel járna,mivel nagyon keveset tudna arról, hogy az ügyfelek mikor és hol vásárolnak. Az egyes üzletek tranzakcióinak második mérése viszont hihetetlenül nagy részletességgel járna.
az adatok ideális részletessége az elvégzett elemzés típusától függ. Ha évtizedek óta keresi a fogyasztói magatartás mintáit, az alacsony szemcsézettség valószínűleg rendben van. Az áruház feltöltésének automatizálásához azonban sokkal részletesebb adatokra van szükség.
ha rossz szemcsézettséget választasz az elemzéshez, kevésbé pontos és kevésbé hasznos intelligenciát kapsz. Gondoljon bele, milyen rendetlen lenne a csak az éves rendszerszintű adatok alapján történő heti áruház-feltöltés! Folyamatosan tapasztalhatja mind a felesleges készleteket, mind a készleteket, hatalmas költségeket és magas hulladékmennyiséget halmozva fel a folyamat során. Bármely elemzésben a helytelen adatgrafikáció hasonlóan súlyos következményekkel járhat a hatékonyságára és a lényegre nézve.
tehát a megfelelő adatrészletességet használja üzleti intelligenciájához? Íme öt gyakori — és költséges-adat-részletességi hiba.
több üzleti trend csoportosítása egyetlen mintába (ha az adatok nem elég részletesek).
az üzleti intelligenciának világosnak és egyértelműnek kell lennie ahhoz, hogy végrehajtható legyen, de néha az egyszerűség elérése érdekében az emberek nem merülnek elég mélyen az adatokba. Ez szégyen, mert kihagyja az értékes betekintést. Ha az adatok részletessége túl alacsony, akkor csak a felszínre felmerülő nagy mintákat látja. Lehet, hogy hiányzik a kritikus adatok.
túl sok esetben az adatok nem elég alapos vizsgálata az eltérő trendek egyetlen eredménybe tömörítéséhez vezet. Az ezt a hibát elkövető vállalkozások egyenetlen eredményekkel járnak. Nagyobb valószínűséggel vannak kiszámíthatatlan és szélsőséges kiugró értékeik, amelyek nem felelnek meg az Általános mintának — mert ez a minta nem tükrözi a valóságot.
ez sok hagyományos ellátási lánc előrejelző rendszerben gyakori probléma. Nem tudják kezelni az egyes üzletek SKU-szintű keresletének előrejelzéséhez szükséges részletességi szintet, ami azt jelenti, hogy egyetlen üzlet egyszerre foglalkozhat mind a készletekkel, mind a készletekkel. Az AI által működtetett automatizált rendszerek képesek kezelni az adatok megfelelő szegmentálásához szükséges bonyolultságot, ami az egyik oka annak, hogy ezek javítják az ellátási lánc hatékonyságát. Az adatok megfelelő részletessége kritikus fontosságú a pontosabb üzleti intelligencia szempontjából.

elveszni az adatokban fókuszpont nélkül (ha az adatok túl szemcsések).
előfordult már, hogy véletlenül túl messzire nagyított egy online térképen? Ez annyira frusztráló! Nem tud semmilyen hasznos információt kitalálni, mert nincs kontextus. Ez történik az adatokban is.
ha az adatok túl szemcsés, akkor eltéved; nem lehet összpontosítani elég találni egy hasznos mintát az összes idegen adatokat. Csábító azt érezni, hogy az adatokkal kapcsolatban mindig jobb a részletesség, de a túl sok részlet gyakorlatilag haszontalanná teheti adatait. Sok olyan vezető, aki ennyi adattal szembesül, fagyasztva találja magát elemzési bénulással. Végül megbízhatatlan ajánlásokkal, az üzleti környezet hiányával és felesleges zavarokkal jár.
a túl szemcsés adatok különösen költséges hibák az AI előrejelzésében. Az adatok becsaphatják az algoritmust, jelezve, hogy elegendő adattal rendelkezik ahhoz, hogy feltételezéseket tegyen a jövőről, ami a mai technológiával nem lehetséges. Például az EVO ellátási láncában végzett munkám során még mindig lehetetlen előrejelezni a napi értékesítést SKU-nként. A hibahatár túl nagy lesz ahhoz, hogy hasznos legyen. Ez a részletesség aláássa a célokat és csökkenti a megtérülést.
nem szándékosan választotta ki az időváltozók részletességét.
a leggyakoribb adatgrafikációs hibák az időintervallumokhoz kapcsolódnak, azaz a változók óránkénti, napi, heti, éves stb. alap. Az időbeli szemcsésségi hibák gyakran a kényelem kedvéért fordulnak elő. A legtöbb vállalatnak szabványos módja van az időzített változók jelentésére. Úgy érzi, hogy túl sok erőfeszítést igényel a megváltoztatásuk, ezért nem
ha mérlegeli a KPI-k jelentési módjának megváltoztatásának költségeit, szemben a nem megfelelő üzleti intelligencia következetes megszerzésének költségeivel, akkor a megfelelő részletességi nyilvántartás céltudatos kiválasztásának előnyei. Az idő részletességétől függően ugyanazon adatokból nagyon különböző betekintést fog felismerni. Vegyük például a kiskereskedelem szezonalitási trendjeit. Ha egyetlen nap alatt nézzük a tranzakciókat, láthatatlanná tehetjük a szezonális trendeket, vagy legalábbis annyi adatot tartalmazhatnak, hogy a minták csak fehér zajok, míg a havi adatok egy különálló szekvenciát osztanak meg, amelyet valóban használhat. Ha a szokásos KPI-k kihagyják a havi jelentéseket, hogy egyenesen a negyedéves mintákra kerüljenek, akkor értékes betekintést veszít, amely pontosabbá tenné az előrejelzéseket. Nem lehet időt granularitás névértéken, ha azt szeretné, hogy a legjobb intelligencia.


Overfitting vagy underfitting a modell arra a pontra, hogy a minták látsz értelmetlen.
az AI modelleknek jól kell általánosítaniuk a meglévő és jövőbeli adatokból, hogy hasznos ajánlásokat nyújtsanak. Lényegében egy jó modell megnézheti ezeket az adatokat:

tegyük fel, hogy ez egy működő modell az információk alapján:

lehet, hogy a minta nem tökéletesen képviseli az adatokat, de jó munkát végez a tipikus viselkedés előrejelzésében anélkül, hogy túl sok intelligenciát feláldozna.
Ha azonban nem rendelkezik a megfelelő adatgrafikával, akkor rossz modellt kaphat. Amint arról korábban beszéltünk, a túl szemcsés adatok zajt okozhatnak, ami megnehezíti a minta megtalálását. Ha az algoritmus következetesen edz ezzel a zajos részletességgel, akkor viszont zajt ad. A végén egy modell, amely így néz ki:

ezt nevezzük a modell túltöltésének. Minden adatpontnak túlméretezett hatása van, olyan mértékben, hogy a modell már nem képes hasznosan általánosítani. Az eredetileg a nagy szemcsézettség által okozott problémákat felnagyítják és állandó problémává teszik a modellben.
az adatok túl alacsony részletessége hosszú távon is károsíthatja a modellt. Az algoritmusnak elegendő adattal kell rendelkeznie a minták megtalálásához. Algoritmusok képzett adatok felhasználásával anélkül, hogy elég részletesség hiányozni fog a kritikus mintákat. Miután az algoritmus túllépett a képzési szakaszon, továbbra sem fogja azonosítani a hasonló mintákat. A végén egy modell, amely így néz ki:
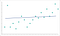
ez alulteljesíti a modellt. Az algoritmus közel áll a helyes előrejelzésekhez, de soha nem lesznek olyan pontosak, mint lehetett volna. Mint overfitting, ez egy nagyítás a kezdeti granularitás probléma.
amikor modellt hoz létre az elemzéshez, a megfelelő részletesség exponenciálisan fontosabbá válik, mint ha stabil algoritmussal rendelkezik. Emiatt sok vállalat úgy dönt, hogy a folyamat ezen részét kiszervezi szakértőknek. Ez túl kényes és költséges szakasz a hibákhoz.
a hibás adatok részletességének teljes beállítása.
talán a legköltségesebb adat granularitás hiba pusztán összpontosítva annyira optimalizálása a részletességét KPI jelenleg mért, hogy nem veszik észre, hogy a rossz KPI teljesen. Célunk, hogy a megfelelő adatgrafikációt elérjük, nem azért, hogy optimalizáljunk egy adott KPI teljesítményt, hanem azért, hogy felismerjük az adatokban lévő mintákat, amelyek hasznosítható és értékes betekintést nyújtanak. Ha például javítani szeretné a bevételt, akkor alááshatja sikerét azzal, hogy csak az árképzési mintákat vizsgálja. Más tényezők is érintettek.
Vegyünk egy példát a kollégámtól. Egy új Evo ügyfél növelni akarta az értékesítést, és az ellátási lánc eszközeinket alkalmazó első teszt kevesebb mint két hét alatt 10% – os javulást mutatott. Vezérigazgatónkat nem izgatták ezek a példátlan eredmények, de meglepetésére az ellátási lánc menedzsere nem volt lenyűgözve. Elsődleges KPI-je a termékek elérhetősége volt, és a belső számok szerint ez soha nem változott. Egy adott KPI javítására való összpontosítása más adatokból származó értékes betekintések felismerésének árán történt.


függetlenül attól, hogy a KPI-t pontosan mérték-e vagy sem, teljes egészében a teljesítmény megváltoztatására összpontosítva visszatartotta ezt a menedzsert attól, hogy új megközelítésben lássa az értéket. Okos ember volt, jóhiszeműen cselekedett, de az adatok félrevezették — hihetetlenül gyakori, mégis drága hiba. Az adatok pontos részletessége létfontosságú, de önmagában nem lehet cél. Meg kell nézni a nagyobb képet, hogy maximalizálja a visszatér AI. Az, hogy mennyire nézed meg az adataidat, nem számít, ha nem rendelkezel a megfelelő adatokkal.
“az adatvezérelt menedzsment általános tévedése a rossz adatok felhasználása a helyes kérdés megválaszolásához”. – Fabrizio Fantini, az Evo alapítója és vezérigazgatója
a megfelelő adatok granularitásának előnyei
nincs mágikus golyó, amikor az adatok granularitásáról van szó. Gondosan és szándékosan kell választania, hogy elkerülje ezeket és más kevésbé gyakori hibákat. Az adatokból származó hozam maximalizálásának egyetlen módja az, ha kritikusan nézzük meg-általában egy szakértő adattudós segítségével. Valószínűleg nem kap granularitást az első próbálkozáskor, ezért tesztelnie kell és be kell állítania, amíg tökéletes.
megéri az erőfeszítést, bár. Ha alaposan megvizsgálja, de nem túl szorosan, az adatai biztosítják az optimális üzleti intelligenciát. A szegmentált és helyesen elemzett adatok olyan versenyelőnyt jelentenek, amelyre számíthat.