lehet, hogy már régóta használsz fa modelleket, vagy egy újoncot, de elgondolkodtál már azon, hogy valójában hogyan működik, és miben különbözik más algoritmusoktól? Itt, megosztom egy rövid megértésemet.
a CART egy prediktív modell is, amely segít megtalálni a változót más címkézett változók alapján. Hogy egyértelműbb legyen, a fa modellek megjósolják az eredményt azáltal, hogy feltesznek egy sor if-else kérdést. A fa modellek használatának két fő előnye van,
- képesek rögzíteni a nemlinearitást az adatkészletben.
- nincs szükség az adatok szabványosítására fa modellek használatakor. Mivel nem számítanak ki euklideszi távolságot vagy más mérési tényezőt az adatok között. Csak ha-máskülönben.
dió és csavar fa

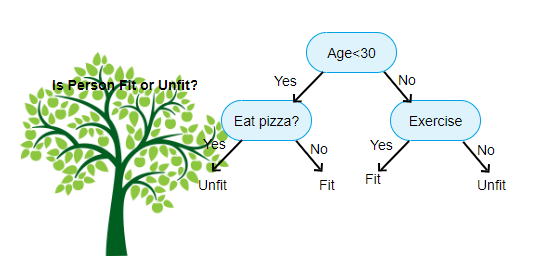
fent látható egy kép döntési fa osztályozó, minden körben ismert csomópontok. Minden csomópontnak lesz egy If-else záradéka egy címkézett változó alapján. E kérdés alapján a bemenet minden példányát egy adott levélcsomópontra irányítják/irányítják, amely megmondja a végső előrejelzést. Három típusú csomópont van,
- Gyökércsomópont: nincs szülőcsomópontja, és két gyermekcsomópontot ad a
- belső csomópont kérdése alapján: lesz szülőcsomópontja, és két gyermekcsomópontot ad
- levélcsomópont: lesz szülőcsomópontja is, de nem lesz gyermekcsomópontja
a We have szintjeinek száma max_depth néven ismert. A fenti ábrán max_depth = 3. A max_depth növekedésével a modell komplexitása is növekszik. Miközben edzünk, ha növeljük, az edzési hiba mindig csökken, vagy ugyanaz marad. De néha növelheti a tesztelési hibát. Tehát válogatósnak kell lennünk, amikor kiválasztjuk a modell max_depth értékét.
egy másik érdekes tényező a csomópontról az információszerzés (IR). Ez egy kritérium, amelyet a csomópont tisztaságának mérésére használnak. A tisztaságot annak alapján mérik, hogy egy csomópont milyen okosan tudja felosztani az elemeket. Tegyük fel, hogy egy csomópontnál vagy, és balra vagy jobbra akarsz menni. De van elem tartozik mindkét osztály azonos mennyiségű (50-50) minden csomóponton. Akkor mindkét osztály tisztasága alacsony, mert nem tudja, melyik irányt válassza. Az egyiknek magasabbnak kell lennie, mint a másiknak, hogy döntést hozzon. ezt IR segítségével mérjük,
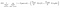

ahogy maga a név is mondja, a CART célja annak megjósolása, hogy a bemeneti példány melyik osztályba tartozik a címkézett értékek alapján. Ennek elérése érdekében döntési régiókat hoz létre a döntési határok felhasználásával. Képzelje el, hogy van egy 2D adatkészletünk,

így a többdimenziós adatkészletet döntési régiókra választja el az egyes csomópontok if-else kérdései alapján. A CART modellek pontosabb döntési régiókat találnak, mint a lineáris modellek. A CART szerinti döntési régiók általában téglalap alakúak, mert a döntéshozatal minden csomópontjában csak egy jellemző vesz részt. Az alábbiakban vizualizálhatja,

azt hiszem, elég a bevezetések, lássunk néhány példát arra, hogyan lehet CART modelleket építeni a Scikit learn-on.
osztályozási fa
#use a seed value for reusability
SEED = 1 # Import DecisionTreeClassifier from sklearn.tree
from sklearn.tree import DecisionTreeClassifier# Instantiate a DecisionTreeClassifier
# You can specify other parameters like criterion refer sklearn documentation for Decision tree. or try dt.get_params()dt = DecisionTreeClassifier(max_depth=6, random_state=SEED)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Import accuracy_score
from sklearn.metrics import accuracy_score# Predict test set labels
y_pred = dt.predict(X_test)# Compute test set accuracy
acc = accuracy_score(y_pred, y_test)
print("Test set accuracy: {:.2f}".format(acc))
regressziós fa
# Import DecisionTreeRegressor from sklearn.tree
from sklearn.tree import DecisionTreeRegressor# Instantiate dt
dt = DecisionTreeRegressor(max_depth=8,
min_samples_leaf=0.13,
random_state=3)# Fit dt to the training set
dt.fit(X_train, y_train)# Predict test set labels
y_pred = dt.predict(X_test)# Compute mse
mse = MSE(y_test, y_pred)# Compute rmse_lr
rmse = mse**(1/2)# Print rmse_dt
print('Regression Tree test set RMSE: {:.2f}'.format(rmse_dt))
remélem, hogy ez a cikk hasznos, ha bármilyen megbeszélése vagy javaslata van, kérjük, hagyjon privát megjegyzést.