Differensialekspresjonsanalyse betyr å ta de normaliserte lesetellingsdataene og utføre statistisk analyse for å oppdage kvantitative endringer i uttrykksnivåer mellom eksperimentelle grupper. For eksempel bruker vi statistisk testing for å avgjøre om en observert forskjell i lesetall for et gitt gen er signifikant, det vil si om den er større enn det som forventes bare på grunn av naturlig tilfeldig variasjon.
metoder for differensialuttrykk analyse
det finnes ulike metoder for differensialuttrykk analyse som edgeR og DESeq basert på negative binomial (NB) distribusjoner eller baySeq og EBSeq som Er Bayesianske tilnærminger basert på en negativ binomial modell. Det er viktig å vurdere eksperimentell design når du velger en analysemetode. Mens noen av differensial uttrykk verktøy kan bare utføre parvis sammenligning, andre som edgeR, limma-voom, DESeq Og maSigPro kan utføre flere sammenligninger.
I Figur 11, nedenfor, skisserer VI RNA-seq – prosessorledningen som brukes til å generere data for Uttrykksatlas.
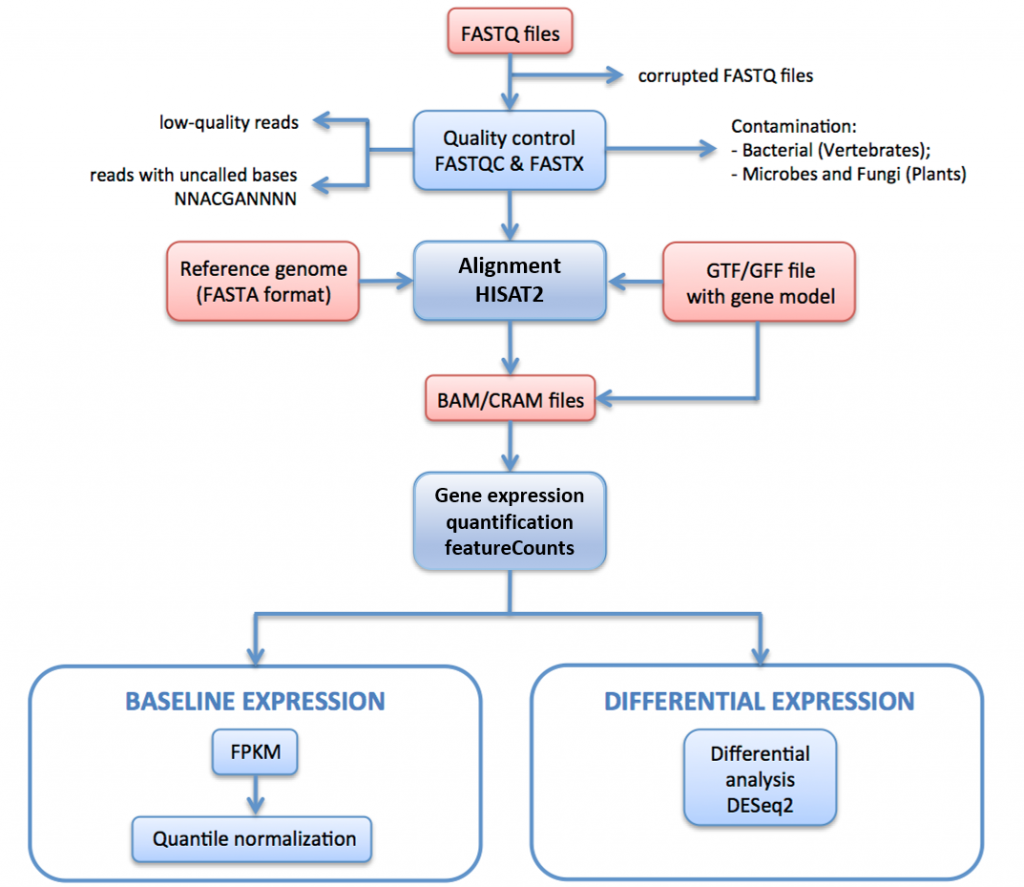
i denne pipeline raw leser (FASTQ filer) gjennomgå kvalitetsvurdering og filtrering. De kvalitetsfiltrerte lesingene er justert til referansegenomet via HISAT2. De kartlagte lesingene oppsummeres og aggregeres over gener via HTSeq. For baseline-uttrykk beregnes Fpkmene fra de rå tellingene av iRAP. Disse er i gjennomsnitt for hvert sett av tekniske replikater, og deretter quantile normalisert innenfor hvert sett av biologiske replikater ved hjelp av limma.