a differenciális expressziós analízis azt jelenti, hogy a normalizált olvasási számadatokat vesszük és statisztikai analízist végzünk a kísérleti csoportok közötti expressziós szintek mennyiségi változásainak felderítésére. Például statisztikai teszteléssel döntjük el, hogy egy adott gén esetében az olvasási számok megfigyelt különbsége szignifikáns-e, vagyis nagyobb-e, mint ami csak a természetes véletlenszerű variáció miatt várható lenne.
differenciál expressziós analízis módszerei
a differenciál expressziós analízisnek különböző módszerei vannak, mint például az edger és a DESeq, amelyek negatív binomiális (NB) eloszlásokon alapulnak, vagy baySeq és EBSeq, amelyek negatív binomiális modellen alapuló bayesi megközelítések. Fontos figyelembe venni a kísérleti tervezést az elemzési módszer kiválasztásakor. Míg néhány differenciál expressziós eszköz csak páronkénti összehasonlítást képes végrehajtani, mások, mint például az edgeR, a limma-voom, a DESeq és a maSigPro több összehasonlítást is végezhetnek.
az alábbi 11. ábrán vázoljuk az expressziós Atlasz adatainak előállításához használt RNS-seq feldolgozó csővezetéket.
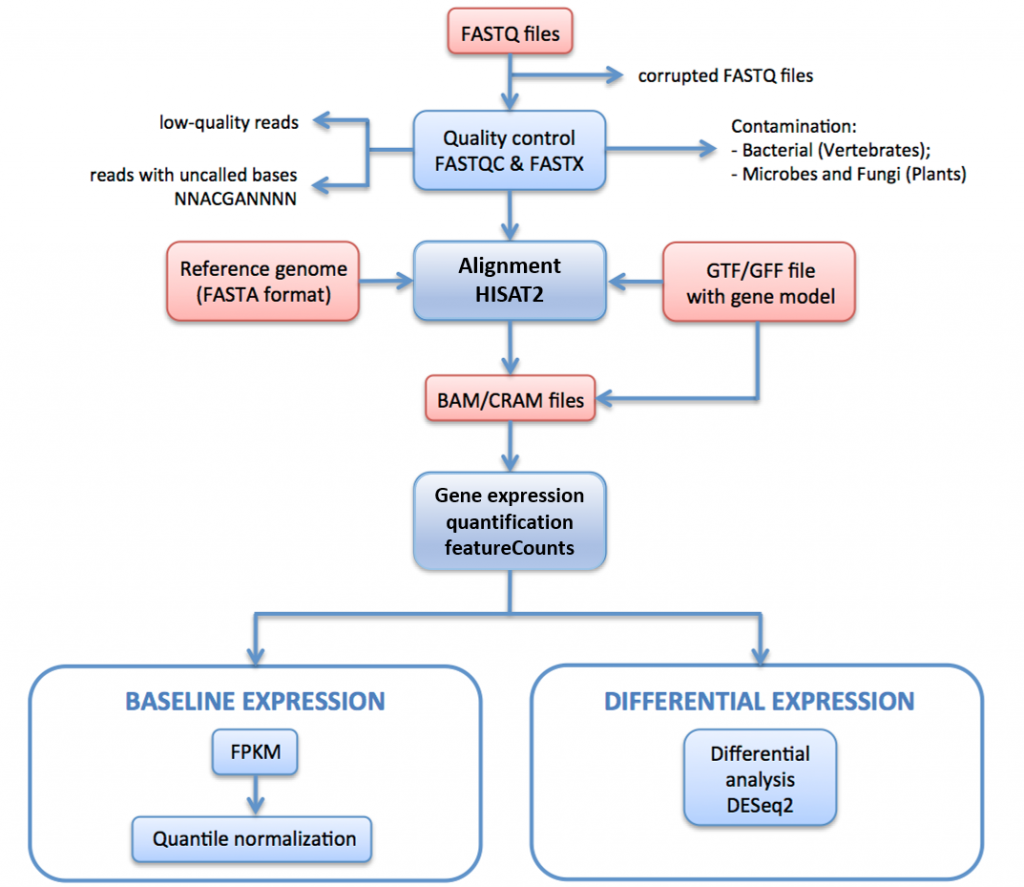
ebben a folyamatban a nyers olvasmányok (FASTQ fájlok) minőségértékelésen és szűrésen mennek keresztül. A minőséggel szűrt olvasmányok a hisat2-n keresztül igazodnak a referencia genomhoz. A leképezett olvasmányokat a HTSeq-n keresztül a gének összegzik és összesítik. A kiindulási kifejezéshez az Fpkm-eket az iRAP nyers számlálásából számítják ki. Ezeket a technikai replikációk minden egyes halmazára átlagoljuk, majd a limma segítségével kvantilisen normalizáljuk a biológiai replikációk minden halmazán belül.