V posledních letech, posílení algoritmů získal masivní popularitě ve vědeckých dat nebo strojového učení soutěží. Většina vítězů těchto soutěží používá k dosažení vysoké přesnosti posilovací algoritmy. Tyto soutěže v oblasti vědy o datech poskytují globální platformu pro učení, zkoumání a poskytování řešení různých obchodních a vládních problémů. Posilovací algoritmy kombinují několik modelů s nízkou přesností (nebo slabými) a vytvářejí modely s vysokou přesností (nebo silnými). Lze jej využít v různých oblastech, jako je úvěr, pojištění, marketing a prodej. Posílení algoritmy, jako je AdaBoost, Gradient posílení, a XGBoost jsou široce používány strojové učení algoritmus vyhrát datové vědy soutěže. V tomto kurzu, budete učit AdaBoost soubor posílení algoritmus, a to následující témata budou pokryty:
- Soubor Machine Learning
- Pytlování
- Zvýšení
- stohování
- AdaBoost Klasifikátor
- Jak se AdaBoost algoritmus práce?
- Stavební Model v Pythonu
- Klady a zápory
- Závěr
Soubor Machine Learning
soubor je složený model, kombinuje řadu nízkou výkonností, klasifikátory s cílem vytvořit lepší třídění. Zde se vrátil individuální klasifikační hlas a konečný Predikční štítek, který provádí většinové hlasování. Soubory nabízejí větší přesnost než individuální nebo základní klasifikátor. Metody Ensemble mohou paralelizovat přidělením každého žáka základny různým strojům. Konečně můžete říci, Ensemble metody učení jsou meta-algoritmy, které kombinují několik metod strojového učení do jediného prediktivní model pro zvýšení výkonu. Ensemble metody mohou snížit rozptyl pomocí pytlování přístup, zaujatost pomocí posílení přístup, nebo zlepšit předpovědi pomocí stohování přístup.
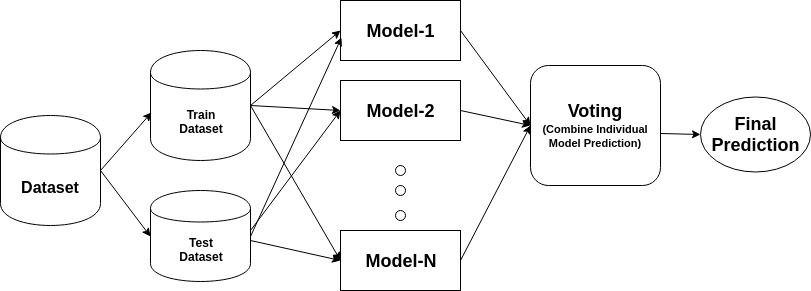
-
pytlování znamená agregaci bootstrap. Kombinuje více studentů způsobem, který snižuje rozptyl odhadů. Například náhodné lesní vlaky m rozhodovací strom, můžete trénovat M různé stromy na různých náhodných podmnožinách dat a provádět hlasování pro konečnou předpověď. Metody pytlování souborů jsou náhodné lesy a další stromy.
-
posilovací algoritmy jsou sadou nízko přesného klasifikátoru pro vytvoření vysoce přesného klasifikátoru. Klasifikátor s nízkou přesností (nebo slabý klasifikátor) nabízí přesnost lepší než převrácení mince. Vysoce přesný klasifikátor (nebo silný klasifikátor) nabízí chybovost blízkou 0. Posílení algoritmus může sledovat model, který selhal přesné predikce. Posilovací algoritmy jsou problémem s nadměrným vybavením méně ovlivněny. Následující tři algoritmy získaly obrovskou popularitu v soutěžích v oblasti vědy o datech.
- AdaBoost (Adaptive Boosting)
- Gradient Strom Posílení
- XGBoost
-
Stohování(nebo naskládané generalizace) je soubor učení technika, která kombinuje více základní klasifikace modelů předpovědi do nové datové sady. Tato nová data jsou považována za vstupní data pro jiný klasifikátor. Tento klasifikátor používá k vyřešení tohoto problému. Stohování je často označováno jako míchání.
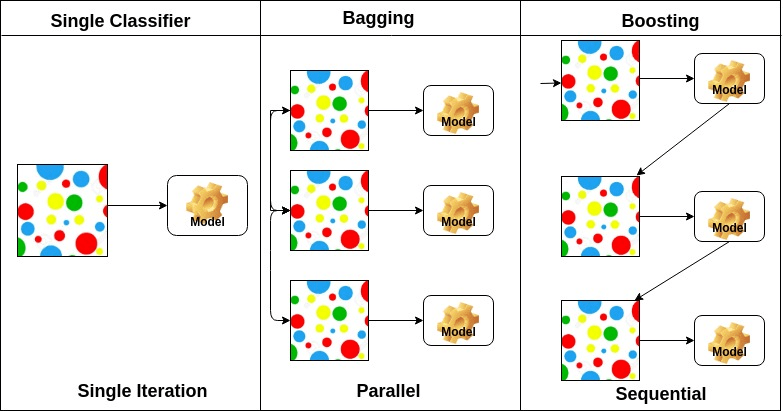
Na základě uspořádání základny studenty, ensemble metody mohou být rozděleny do dvou skupin: V paralelní ensemble metod, základní studenty jsou generovány v paralelním například. Náhodný Les. V metodách sekvenčního souboru jsou základní studenti generováni postupně, například AdaBoost.
na základě typu základních žáků lze metody souboru rozdělit do dvou skupin: metoda homogenního souboru používá v každé iteraci stejný typ základního žáka. heterogenní metoda ensemble používá v každé iteraci jiný typ základního žáka.
AdaBoost Klasifikátor
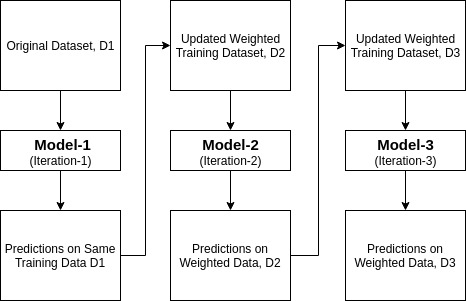
Ada-boost nebo Adaptivní Podpora je jedním z ensemble zvýšení třídění navržené Yoav Freund a Robert Schapire v roce 1996. Kombinuje více klasifikátorů pro zvýšení přesnosti klasifikátorů. AdaBoost je iterativní metoda souboru. AdaBoost classifier vytváří silný klasifikátor kombinací několika špatně fungujících klasifikátorů, takže získáte vysokou přesnost silný klasifikátor. Základním konceptem Adaboost je nastavit váhy klasifikátorů a trénovat vzorek dat v každé iteraci tak, aby zajišťoval přesné předpovědi neobvyklých pozorování. Jakýkoli algoritmus strojového učení lze použít jako základní klasifikátor, pokud přijímá závaží na tréninkové sadě. Adaboost by měl splňovat dvě podmínky:
- klasifikátor by měl být interaktivně vyškolen na různých vážených příkladech školení.
- v každé iteraci se snaží tyto příklady dokonale přizpůsobit minimalizací chyby školení.
jak funguje algoritmus AdaBoost?
funguje v následujících krocích:
- zpočátku Adaboost náhodně vybere podmnožinu školení.
- iterativně trénuje Model strojového učení AdaBoost výběrem tréninkové sady na základě přesné předpovědi posledního tréninku.
- přiřazuje vyšší váhu chybným klasifikovaným pozorováním, takže v další iteraci tato pozorování získají vysokou pravděpodobnost klasifikace.
- také přiřazuje váhu vyškolenému klasifikátoru v každé iteraci podle přesnosti klasifikátoru. Přesnější klasifikátor získá vysokou váhu.
- Tento proces opakovat, dokud dokončení přípravy dat se vejde bez jakýchkoli chyb nebo dokud dosaženo zadané maximální počet odhadů.
- Chcete-li klasifikovat, proveďte „hlasování“ ve všech vytvořených učebních algoritmech.
Budování Modelu v Pythonu
Import potřebných Knihoven
Pojďme se nejprve vložte požadované knihovny.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsLoading Dataset
v modelu stavební část můžete použít dataset IRIS, což je velmi známý problém klasifikace více tříd. Tato datová sada se skládá ze 4 prvků (sepal length, sepal width, petal length, petal width, šířka) a cíl (typ květu). Tato data mají tři typy tříd květin: Setosa, versicolor a Virginica. Dataset je k dispozici v knihovně scikit-learn, nebo si jej můžete také stáhnout z knihovny strojového učení UCI.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit dataset
Chcete-li pochopit výkon modelu, rozdělení datasetu na tréninkovou sadu a testovací sadu je dobrá strategie.
rozdělme dataset pomocí funkce train_test_split (). musíte projít 3 parametry funkce, cíl a velikost test_set.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testvytvoření modelu AdaBoost
pojďme vytvořit model AdaBoost pomocí Scikit-learn. AdaBoost používá klasifikátor rozhodovacího stromu jako výchozí klasifikátor.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)„nejdůležitější parametry jsou base_estimator, n_estimators, a learning_rate.“(AdaBoost, Chris Albon)
- base_estimator: je to slabý student používaný k výcviku modelu. Používá DecisionTreeClassifier jako výchozí slabý student pro účely výcviku. Můžete také určit různé algoritmy strojového učení.
- n_estimators: počet slabých studentů trénovat iterativně.
- learning_rate: přispívá k hmotnosti slabých studentů. Používá 1 jako výchozí hodnotu.
vyhodnoťte Model
pojďme odhadnout, jak přesně může klasifikátor nebo model předpovědět Typ kultivarů.
přesnost lze vypočítat porovnáním skutečných hodnot testovacích sad a předpokládaných hodnot.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888no, máte přesnost 88,88%, považována za dobrou přesnost.
pro další vyhodnocení můžete také vytvořit model pomocí různých základních odhadů.
pomocí různých základních studentů
použil jsem SVC jako základní odhad. Můžete použít jakýkoli ML student jako základní odhad, pokud přijímá hmotnost vzorku, jako je rozhodovací strom, podpora vektorového klasifikátoru.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556no, máte klasifikační poměr 95,55%, považovaný za dobrou přesnost.
V tomto případě, SVC Základní Odhad je stále lepší přesnost pak Rozhodovací strom Základní Odhad.
Pros
AdaBoost se snadno implementuje. Iterativně opravuje chyby slabého klasifikátoru a zlepšuje přesnost kombinací slabých studentů. S AdaBoost můžete použít mnoho základních klasifikátorů. AdaBoost není náchylný k nadměrnému vybavení. To lze zjistit pomocí výsledků experimentu, ale není k dispozici žádný konkrétní důvod.
nevýhody
AdaBoost je citlivý na šumová data. Je velmi ovlivněn odlehlými hodnotami, protože se snaží dokonale zapadnout do každého bodu. AdaBoost je pomalejší ve srovnání s XGBoost.
závěr
Gratulujeme, že jste se dostali na konec tohoto tutoriálu!
v tomto tutoriálu jste se naučili přístupy strojového učení Ensemble, algoritmus AdaBoost, funguje to, vytváření modelů a hodnocení pomocí balíčku Python Scikit-learn. Také diskutoval o jeho výhodách a nevýhodách.