i de senere årene har økt algoritmer fått enorm popularitet i datavitenskap eller maskinlæringskonkurranser. De fleste av vinnerne av disse konkurransene bruker forsterkende algoritmer for å oppnå høy nøyaktighet. Disse datavitenskapskonkurransene gir den globale plattformen for å lære, utforske og tilby løsninger for ulike forretnings-og regjeringsproblemer. Forsterke algoritmer kombinere flere lav nøyaktighet (eller svak) modeller for å lage en høy nøyaktighet(eller sterk) modeller. Den kan brukes i ulike domener som kreditt, forsikring, markedsføring og salg. Øke algoritmer Som AdaBoost, Gradient Øker, Og XGBoost er mye brukt maskinlæring algoritme for å vinne data vitenskap konkurranser. I denne opplæringen skal du lære adaboost ensemble boosting-algoritmen, og følgende emner vil bli dekket:
- Ensemble Maskinlæring Tilnærming
- Bagging
- Forsterke
- stabling
- AdaBoost Classifier
- hvordan Fungerer adaboost-algoritmen?
- Byggemodell I Python
- Fordeler og ulemper
- Konklusjon
Ensemble Machine Learning Approach
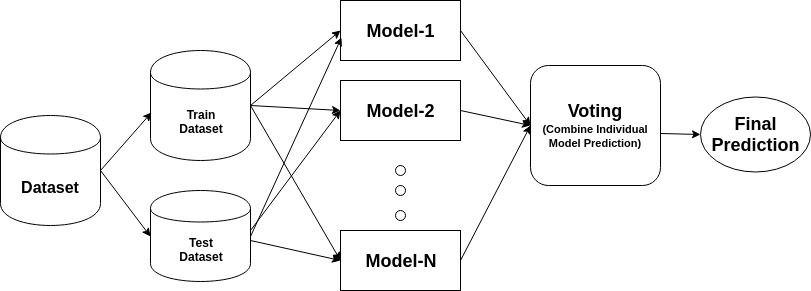
et ensemble er en sammensatt modell som kombinerer en serie klassifikatorer med lav ytelse med sikte på å skape en forbedret klassifikator. Her returnerte individuell klassifikatorstemme og endelig prediksjonsmerke som utfører flertallsvalg. Ensembler tilbyr mer nøyaktighet enn individuelle eller base klassifikator. Ensemble metoder kan parallellisere ved å tildele hver base elev til forskjellige forskjellige maskiner. Til slutt kan Du si At Ensemble læringsmetoder er meta-algoritmer som kombinerer flere maskinlæringsmetoder i en enkelt prediktiv modell for å øke ytelsen. Ensemble metoder kan redusere variansen ved hjelp av bagging tilnærming, skjevhet ved hjelp av en økende tilnærming, eller forbedre spådommer ved hjelp av stabling tilnærming.
-
Bagging står for bootstrap aggregering. Den kombinerer flere elever på en måte å redusere variansen av estimater. For eksempel, tilfeldig skog tog M Beslutning Treet, kan du trene m forskjellige trær på ulike tilfeldige delsett av dataene og utføre stemme for endelig prediksjon. Bagging ensembler metoder Er Tilfeldig Skog Og Ekstra Trær.
-
Øke algoritmer er et sett av lav nøyaktig klassifikator for å skape en svært nøyaktig klassifikator. Lav nøyaktighet klassifikator (eller svak klassifikator) gir nøyaktigheten bedre enn flipping av en mynt. Svært nøyaktig klassifikator (eller sterk klassifikator) tilbyr feilrate nær 0. Forsterke algoritmen kan spore modellen som mislyktes nøyaktig prediksjon. Øke algoritmer er mindre påvirket av overfitting problemet. Følgende tre algoritmer har fått massiv popularitet i datavitenskapskonkurranser.
- AdaBoost (Adaptiv Forsterkning)
- Gradert Treforsterkning
- XGBoost
-
Stabling(eller stablet generalisering) Er en ensemble læring teknikk som kombinerer flere base klassifisering modeller spådommer i et nytt datasett. Disse nye dataene behandles som inngangsdata for en annen klassifikator. Denne klassifikatoren ansatt for å løse dette problemet. Stacking er ofte referert til som blanding.
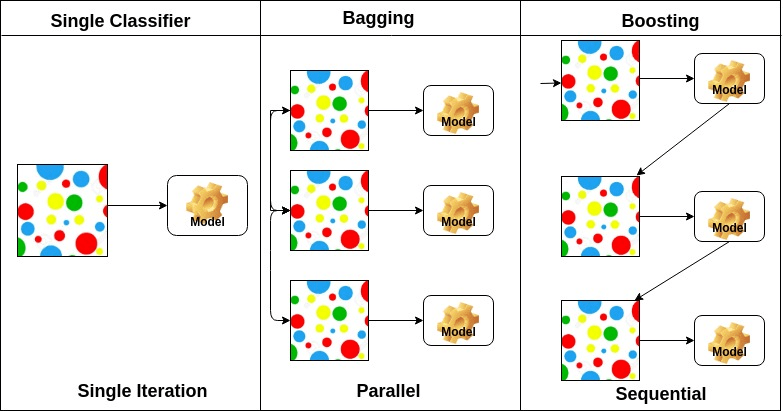
på grunnlag av arrangementet av baselærere kan ensemblemetoder deles inn i to grupper: i parallelle ensemblemetoder genereres baselærere parallelt for eksempel. Tilfeldig Skog. I sekvensielle ensemblemetoder genereres baselærere sekvensielt, For Eksempel AdaBoost.
på grunnlag av den type base elever, ensemble metoder kan deles inn i to grupper: homogen ensemble metoden bruker samme type base elev i hver iterasjon. heterogen ensemble metoden bruker ulike typer base elev i hver iterasjon.
AdaBoost Classifier
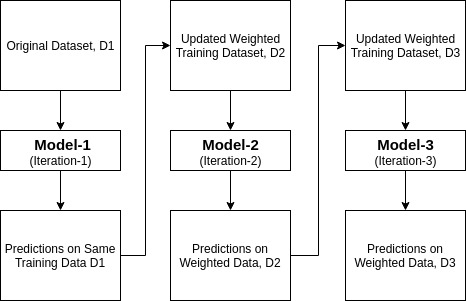
Ada-boost eller Adaptive Boosting Er en av ensemble boosting classifier foreslått Av Yoav Freund Og Robert Schapire i 1996. Den kombinerer flere klassifikatorer for å øke nøyaktigheten av klassifikatorer. AdaBoost er en iterativ ensemble-metode. AdaBoost classifier bygger en sterk klassifikator ved å kombinere flere klassifikatorer med dårlig ytelse, slik at du får høy nøyaktighet sterk klassifikator. Det grunnleggende konseptet Bak Adaboost er å sette vektene til klassifiserere og trene dataprøven i hver iterasjon slik at den sikrer nøyaktige spådommer om uvanlige observasjoner. Enhver maskinlæringsalgoritme kan brukes som baseklassifiserer hvis den aksepterer vekter på treningssettet. Adaboost må oppfylle to betingelser:
- klassifikatoren skal trenes interaktivt på ulike veide treningseksempler.
- i hver iterasjon forsøker den å gi en utmerket passform for disse eksemplene ved å minimere treningsfeil.
hvordan Fungerer adaboost-algoritmen?
det fungerer i følgende trinn:
- I Utgangspunktet velger Adaboost en undergruppe av opplæring tilfeldig.
- den trener adaboost maskinlæringsmodellen iterativt ved å velge treningssettet basert på nøyaktig prediksjon av den siste treningen.
- den tilordner den høyere vekten til feil klassifiserte observasjoner, slik at i neste iterasjon vil disse observasjonene få høy sannsynlighet for klassifisering.
- det tilordner også vekten til den trente klassifikatoren i hver iterasjon i henhold til klassifikatorens nøyaktighet. Den mer nøyaktige klassifikatoren vil få høy vekt.
- denne prosessen itererer til de komplette treningsdataene passer uten feil eller til nådd til det angitte maksimale antall estimatorer.
- for å klassifisere, utfør en «stemme» på tvers av alle læringsalgoritmene du bygde.
Byggemodell I Python
Importerer Nødvendige Biblioteker
La oss først laste inn de nødvendige bibliotekene.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsLaster Datasett
i modellen bygningsdelen kan DU bruke IRIS datasettet, som er et veldig kjent klassifiseringsproblem i flere klasser. Dette datasettet består av 4 funksjoner (sepal lengde, sepal bredde, petal lengde, petal bredde) og et mål (type blomst). Disse dataene har tre typer blomsterklasser: Setosa, Versicolour og Virginica. Datasettet er tilgjengelig i scikit-learn-biblioteket, eller du kan også laste det ned fra Uci Machine Learning Library.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit datasett
for å forstå modellens ytelse, er det en god strategi å dele datasettet i et treningssett og et testsett.
la oss dele datasett ved hjelp av funksjonen train_test_split(). du må passere 3 parametere funksjoner, mål og test_set størrelse.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testBygg AdaBoost-Modellen
La Oss lage AdaBoost-Modellen ved Hjelp Av Scikit-learn. AdaBoost bruker Decision Tree Classifier som standard Classifier.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)«de viktigste parameterne er base_estimator, n_estimators og learning_rate.»(Adaboost Klassifiserer, Chris Albon)
- base_estimator: det er en svak elev som brukes til å trene modellen. Den bruker DecisionTreeClassifier som standard svak elev for trening formål. Du kan også angi forskjellige maskinlæringsalgoritmer.
- n_estimators: Antall svake elever å trene iterativt.
- learning_rate: det bidrar til vektene til svake elever. Den bruker 1 som standardverdi.
Evaluer Modell
la oss anslå, hvor nøyaktig klassifikatoren eller modellen kan forutsi typen av kultivarer.
Nøyaktighet kan beregnes ved å sammenligne faktiske testsettverdier og forventede verdier.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888vel, du har en nøyaktighet på 88,88%, betraktet som god nøyaktighet.
for videre evaluering kan du også lage en modell ved hjelp av Forskjellige Basestimatorer.
Ved Hjelp Av Ulike Base Elever
jeg har brukt SVC som en base estimator. Du kan bruke NOEN ML learner som base estimator hvis den aksepterer prøvevekt som Beslutningstreet, Støttevektorklassifiserer.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556vel, du har en klassifiseringsrate på 95,55%, betraktet som god nøyaktighet.
I dette tilfellet BLIR SVC Base Estimator bedre nøyaktighet enn Decision tree Base Estimator.
Pros
AdaBoost er enkelt å implementere. Den korrigerer feilene til den svake klassifikatoren og forbedrer nøyaktigheten ved å kombinere svake elever. Du kan bruke mange grunnklassifiseringer med AdaBoost. AdaBoost er ikke utsatt for overfitting. Dette kan bli funnet ut via eksperimentresultater, men det er ingen konkret grunn tilgjengelig.
Ulemper
AdaBoost er følsom for støydata. Det er sterkt påvirket av uteliggere fordi den prøver å passe hvert punkt perfekt. AdaBoost er langsommere sammenlignet Med XGBoost.
Konklusjon
Gratulerer, du har gjort det til slutten av denne opplæringen!
i denne opplæringen har du lært Ensemble Machine Learning-Tilnærmingene, adaboost-algoritmen, det fungerer, modellbygging og evaluering ved Hjelp Av Python Scikit-learn-pakken. Også diskutert sine fordeler og ulemper.