Negli ultimi anni, aumentare gli algoritmi ha guadagnato enorme popolarità nella scienza dei dati o nelle competizioni di apprendimento automatico. La maggior parte dei vincitori di queste competizioni utilizza algoritmi di potenziamento per ottenere un’elevata precisione. Questi concorsi di Data science forniscono la piattaforma globale per l’apprendimento, l’esplorazione e la fornitura di soluzioni per vari problemi aziendali e governativi. Gli algoritmi di potenziamento combinano più modelli a bassa precisione (o deboli) per creare modelli ad alta precisione(o forti). Può essere utilizzato in vari domini come credito, assicurazione, marketing e vendite. Aumentare algoritmi come AdaBoost, Gradiente Boosting, e XGBoost sono ampiamente utilizzati algoritmo di apprendimento automatico per vincere le competizioni di scienza dei dati. In questo tutorial, imparerai l’algoritmo di amplificazione dell’ensemble AdaBoost e verranno trattati i seguenti argomenti:
- Ensemble Machine Learning Approach
- Bagging
- Boosting
- stacking
- Classificatore AdaBoost
- Come funziona l’algoritmo AdaBoost?
- Building Model in Python
- Pro e contro
- Conclusione
Ensemble Machine Learning Approach
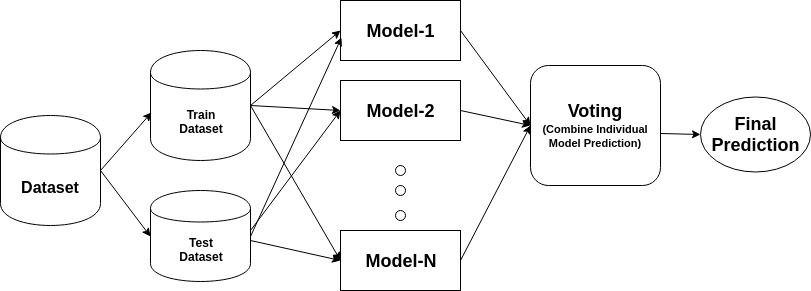
Un ensemble è un modello composito, combina una serie di classificatori a basso rendimento con l’obiettivo di creare un classificatore migliorato. Qui, il voto del classificatore individuale e l’etichetta di previsione finale sono tornati che eseguono il voto a maggioranza. Gli ensemble offrono maggiore precisione rispetto al classificatore individuale o di base. I metodi Ensemble possono parallelizzare allocando ogni studente di base a macchine diverse. Infine, si può dire che i metodi di apprendimento ensemble sono meta-algoritmi che combinano diversi metodi di apprendimento automatico in un unico modello predittivo per aumentare le prestazioni. I metodi Ensemble possono ridurre la varianza utilizzando l’approccio di insacco, il bias utilizzando un approccio di potenziamento o migliorare le previsioni utilizzando l’approccio di stacking.
-
Insaccamento sta per aggregazione bootstrap. Combina più studenti in modo da ridurre la varianza delle stime. Ad esempio, foresta casuale treni M Albero decisione, è possibile addestrare M diversi alberi su diversi sottoinsiemi casuali dei dati ed eseguire il voto per la previsione finale. Insaccamento ensembles metodi sono foresta casuale e alberi extra.
-
Gli algoritmi di potenziamento sono un insieme del classificatore a bassa precisione per creare un classificatore altamente accurato. Classificatore a bassa precisione (o classificatore debole) offre la precisione migliore rispetto al lancio di una moneta. Classificatore altamente accurato (o classificatore forte) offrono un tasso di errore vicino a 0. L’algoritmo di potenziamento può tenere traccia del modello che ha fallito la previsione accurata. Gli algoritmi di potenziamento sono meno influenzati dal problema di overfitting. I seguenti tre algoritmi hanno guadagnato enorme popolarità nelle competizioni di scienza dei dati.
- AdaBoost (Adaptive Boosting)
- Gradient Tree Boosting
- XGBoost
-
Stacking (o generalizzazione stacked) è una tecnica di apprendimento insieme che combina più modelli di classificazione di base previsioni in un nuovo set di dati. Questi nuovi dati vengono trattati come i dati di input per un altro classificatore. Questo classificatore impiegato per risolvere questo problema. L’impilamento è spesso indicato come fusione.
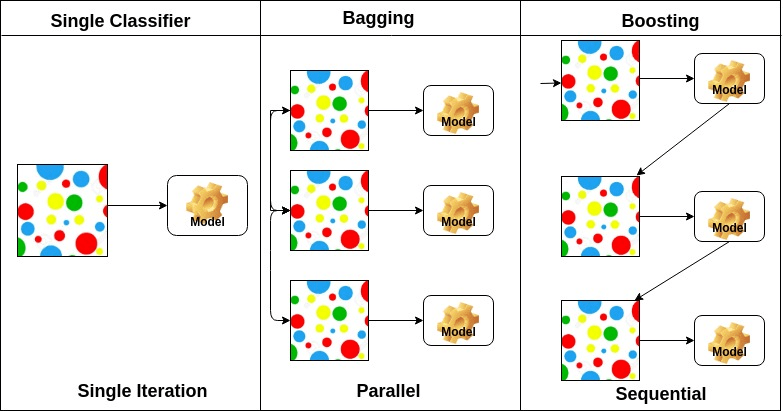
Sulla base della disposizione degli studenti di base, i metodi di ensemble possono essere divisi in due gruppi: nei metodi di ensemble paralleli, gli studenti di base sono generati in parallelo, ad esempio. Foresta casuale. Nei metodi sequenziali di ensemble, gli studenti di base vengono generati sequenzialmente, ad esempio AdaBoost.
In base al tipo di studenti base, i metodi ensemble possono essere suddivisi in due gruppi: il metodo homogenous ensemble utilizza lo stesso tipo di studente di base in ogni iterazione. il metodo ensemble eterogeneo utilizza il diverso tipo di studente di base in ogni iterazione.
AdaBoost Classificatore
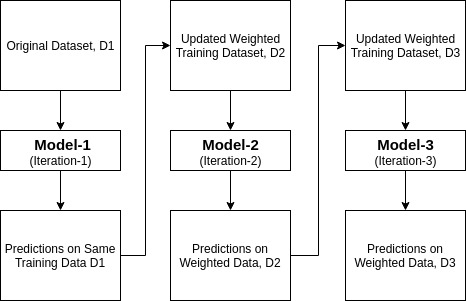
Ada-boost o Adaptive Boosting è uno dei ensemble boosting classificatore proposto da Yoav Freund e Robert Schapire nel 1996. Combina più classificatori per aumentare la precisione dei classificatori. AdaBoost è un metodo di ensemble iterativo. AdaBoost classificatore costruisce un classificatore forte combinando più classificatori poco performanti in modo da ottenere alta precisione classificatore forte. Il concetto di base alla base di Adaboost è quello di impostare i pesi dei classificatori e addestrare il campione di dati in ogni iterazione in modo tale da garantire le previsioni accurate di osservazioni insolite. Qualsiasi algoritmo di apprendimento automatico può essere utilizzato come classificatore di base se accetta pesi sul set di allenamento. Adaboost dovrebbe soddisfare due condizioni:
- Il classificatore deve essere addestrato in modo interattivo su vari esempi di allenamento pesati.
- In ogni iterazione, cerca di fornire una misura eccellente per questi esempi riducendo al minimo l’errore di allenamento.
Come funziona l’algoritmo AdaBoost?
Funziona nei seguenti passaggi:
- Inizialmente, Adaboost seleziona un sottoinsieme di allenamento in modo casuale.
- Allena iterativamente il modello di apprendimento automatico AdaBoost selezionando il set di allenamento in base alla previsione accurata dell’ultimo allenamento.
- Assegna il peso maggiore a osservazioni classificate errate in modo che nella prossima iterazione queste osservazioni ottengano l’alta probabilità di classificazione.
- Inoltre, assegna il peso al classificatore addestrato in ogni iterazione in base alla precisione del classificatore. Il classificatore più accurato otterrà un peso elevato.
- Questo processo itera fino a quando i dati di allenamento completi non si adattano senza errori o fino a raggiungere il numero massimo specificato di stimatori.
- Per classificare, esegui un “voto” su tutti gli algoritmi di apprendimento creati.
Costruzione del modello in Python
Importazione delle librerie richieste
Prima carichiamo le librerie richieste.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsCaricamento del set di dati
Nel modello la parte dell’edificio, è possibile utilizzare il set di dati IRIS, che è un problema di classificazione multi-classe molto famoso. Questo set di dati comprende 4 caratteristiche (lunghezza sepal, larghezza sepal, lunghezza petalo, larghezza petalo) e un obiettivo (il tipo di fiore). Questi dati hanno tre tipi di classi di fiori: Setosa, Versicolour e Virginica. Il set di dati è disponibile nella libreria scikit-learn, oppure è anche possibile scaricarlo dalla libreria di apprendimento automatico UCI.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetSplit dataset
Per comprendere le prestazioni del modello, dividere il dataset in un set di allenamento e un set di test è una buona strategia.
Dividiamo il set di dati usando la funzione train_test_split (). è necessario passare 3 parametri caratteristiche, target e dimensione test_set.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testCreazione del modello AdaBoost
Creiamo il modello AdaBoost usando Scikit-learn. AdaBoost utilizza il classificatore dell’albero delle decisioni come classificatore predefinito.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“I parametri più importanti sono base_estimator, n_estimators e learning_rate.”(Adaboost Classifier, Chris Albon)
- base_estimator: è uno studente debole usato per addestrare il modello. Utilizza DecisionTreeClassifier come studente debole predefinito per scopi di formazione. È inoltre possibile specificare diversi algoritmi di apprendimento automatico.
- n_estimators: Numero di studenti deboli da addestrare in modo iterativo.
- learning_rate: contribuisce al peso degli studenti deboli. Usa 1 come valore predefinito.
Valuta il modello
Stimiamo, quanto accuratamente il classificatore o il modello possono prevedere il tipo di cultivar.
La precisione può essere calcolata confrontando i valori effettivi del set di test e i valori previsti.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Beh, hai una precisione dell ‘ 88,88%, considerata una buona precisione.
Per ulteriori valutazioni, è anche possibile creare un modello utilizzando diversi stimatori di base.
Utilizzando diversi studenti di base
Ho usato SVC come stimatore di base. È possibile utilizzare qualsiasi studente ML come stimatore di base se accetta il peso del campione come l’albero decisionale, il classificatore vettoriale di supporto.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Beh, hai un tasso di classificazione del 95,55%, considerato come una buona precisione.
In questo caso, lo stimatore di base SVC sta ottenendo una precisione migliore dello stimatore di base dell’albero decisionale.
Pro
AdaBoost è facile da implementare. Corregge iterativamente gli errori del classificatore debole e migliora la precisione combinando gli studenti deboli. Puoi usare molti classificatori di base con AdaBoost. AdaBoost non è soggetto a overfitting. Questo può essere scoperto tramite i risultati dell’esperimento, ma non esiste una ragione concreta disponibile.
Contro
AdaBoost è sensibile ai dati di rumore. È altamente influenzato dai valori anomali perché cerca di adattarsi perfettamente a ciascun punto. AdaBoost è più lento rispetto a XGBoost.
Conclusione
Congratulazioni, siete arrivati alla fine di questo tutorial!
In questo tutorial, hai imparato gli approcci di apprendimento automatico Ensemble, l’algoritmo AdaBoost, sta funzionando, la costruzione del modello e la valutazione utilizzando il pacchetto Python Scikit-learn. Inoltre, discusso i suoi pro e contro.