in de afgelopen jaren werd het stimuleren van algoritmen enorm populair in data science of machine learning wedstrijden. De meeste winnaars van deze wedstrijden gebruiken het stimuleren van algoritmen om een hoge nauwkeurigheid te bereiken. Deze data science wedstrijden bieden het wereldwijde platform voor het leren, verkennen en het leveren van oplossingen voor verschillende zakelijke en overheidsproblemen. Boosting algoritmes combineren meerdere lage nauwkeurigheid (of zwakke) modellen om een hoge nauwkeurigheid(of sterke) modellen te creëren. Het kan worden gebruikt in verschillende domeinen zoals krediet, verzekering, marketing, en verkoop. Het stimuleren van algoritmen zoals AdaBoost, gradiënt stimuleren, en XGBoost worden veel gebruikt machine learning algoritme om de data science wedstrijden te winnen. In deze tutorial, je gaat het AdaBoost ensemble stimuleren algoritme leren, en de volgende onderwerpen zullen worden behandeld:
- Ensemble Machine Learning Approach
- Bagging
- Boosting
- stapelen
- AdaBoost Classifier
- Hoe werkt het AdaBoost-algoritme?
- bouwmodel in Python
- voors en tegens
- conclusie
Ensemble Machine Learning Approach
een ensemble is een samengesteld model, combineert een reeks slecht presterende classifiers met als doel een verbeterde classifier te creëren. Hier, individuele classifier stem en definitieve voorspelling label terug dat de meerderheid van de stemming uitvoert. Ensembles bieden meer nauwkeurigheid dan individuele of base classifier. Ensemble methoden kunnen parallelliseren door het toewijzen van elke basis leerling aan verschillende-verschillende machines. Tot slot kun je zeggen dat Ensemble-leermethoden meta-algoritmen zijn die verschillende machine learning-methoden combineren tot één voorspellend model om de prestaties te verhogen. Ensemble methoden kunnen variantie verminderen met behulp van zakken aanpak, bias met behulp van een boosting aanpak, of het verbeteren van voorspellingen met behulp van stapelen aanpak.
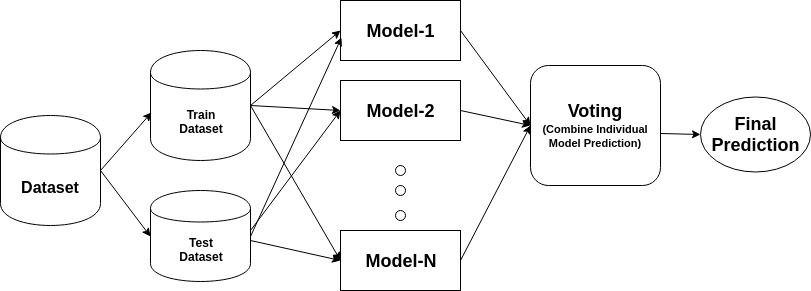
-
Bagging staat voor bootstrap aggregation. Het combineert meerdere leerlingen op een manier om de variantie van schattingen te verminderen. Bijvoorbeeld, random forest trains M Decision Tree, kunt u train m verschillende bomen op verschillende willekeurige deelverzamelingen van de gegevens en het uitvoeren van stemmen voor de definitieve voorspelling. Bagging ensembles methoden zijn willekeurig bos en Extra bomen.
-
het stimuleren van algoritmen zijn een set van de lage nauwkeurige classifier om een zeer nauwkeurige classifier te creëren. Lage nauwkeurigheid classifier (of zwakke classifier) biedt de nauwkeurigheid beter dan het omgooien van een munt. Zeer nauwkeurige classifier (of sterke classifier) bieden foutenpercentage dicht bij 0. Stimuleren algoritme kan het model dat de nauwkeurige voorspelling mislukt volgen. Het stimuleren van algoritmen worden minder beïnvloed door het overfitting probleem. De volgende drie algoritmen zijn enorm populair geworden in Data science competities.
- AdaBoost (Adaptive Boost)
- Gradient Tree Boost
- XGBoost
-
stapelen (of gestapelde generalisatie) is een ensemble-leertechniek die meerdere basisclassificatiemodellen voorspellingen combineert in een nieuwe dataset. Deze nieuwe gegevens worden behandeld als invoergegevens voor een andere classifier. Deze classifier gebruikt om dit probleem op te lossen. Stapelen wordt vaak aangeduid als mengen.
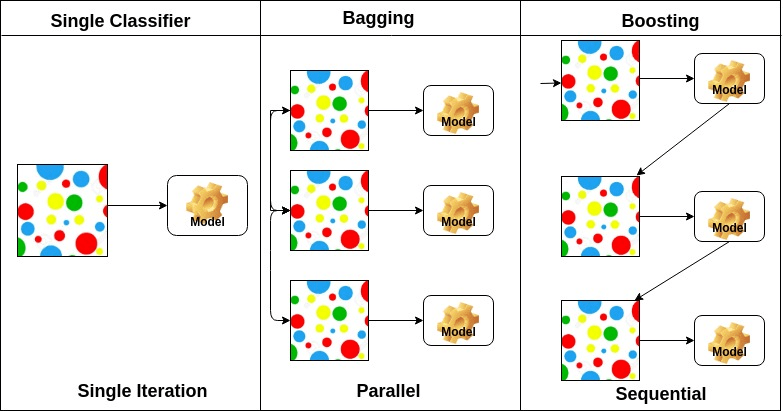
op basis van de rangschikking van basisleerders kunnen ensemblemethoden in twee groepen worden verdeeld: in parallelle ensemblemethoden worden basisleerders bijvoorbeeld parallel gegenereerd. Willekeurig Bos. In sequentiële ensemble methoden worden basisleerders sequentieel gegenereerd, bijvoorbeeld AdaBoost.
op basis van het type basisleerders kunnen ensemblemethoden in twee groepen worden verdeeld: homogene ensemble methode maakt gebruik van hetzelfde type basisleerder in elke iteratie. heterogene ensemble methode gebruikt het verschillende type basisleerder in elke iteratie.
AdaBoost Classifier
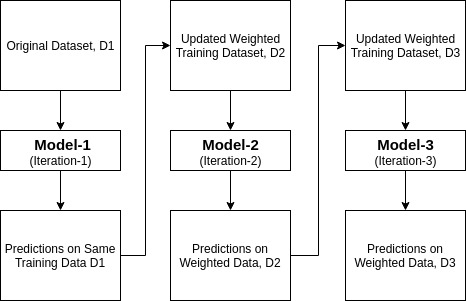
Adaptive Boosting is een van de ensemble boosting classifier voorgesteld door Yoav Freund en Robert Schapire in 1996. Het combineert meerdere classifiers om de nauwkeurigheid van classifiers te verhogen. AdaBoost is een iteratieve ensemblemethode. AdaBoost classifier bouwt een sterke classifier door meerdere slecht presterende classifiers te combineren, zodat u een hoge nauwkeurigheid sterke classifier krijgt. Het basisconcept achter Adaboost is om de gewichten van classifiers in te stellen en de datasteekproef in elke iteratie zodanig te trainen dat het de nauwkeurige voorspellingen van ongewone waarnemingen garandeert. Elke machine learning algoritme kan worden gebruikt als basis classifier als het gewichten op de training set accepteert. Adaboost moet aan twee voorwaarden voldoen:
- de classifier moet interactief worden getraind op verschillende gewogen trainingsvoorbeelden.
- In elke iteratie wordt getracht een uitstekende pasvorm voor deze voorbeelden te bieden door trainingsfouten te minimaliseren.
Hoe werkt het AdaBoost-algoritme?
het werkt in de volgende stappen:
- in eerste instantie selecteert Adaboost willekeurig een trainingssubset.
- het model AdaBoost machine learning traint iteratief door het selecteren van de trainingsset op basis van de nauwkeurige voorspelling van de laatste training.
- het geeft het hogere gewicht aan verkeerd geclassificeerde waarnemingen, zodat in de volgende herhaling deze waarnemingen de grote kans op classificatie krijgen.
- ook wordt het gewicht toegekend aan de getrainde classifier in elke iteratie volgens de nauwkeurigheid van de classifier. De nauwkeurigere classifier krijgt een hoog gewicht.
- dit proces herhaalt zich totdat de volledige trainingsgegevens zonder fouten passen of totdat het gespecificeerde maximumaantal schatters is bereikt.
- om te classificeren, voert u een “stem” uit over alle leeralgoritmen die u hebt gebouwd.
bouwmodel in Python
vereiste bibliotheken importeren
laten we eerst de vereiste bibliotheken Laden.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsdataset Laden
in het model het bouwdeel kunt u de IRIS-dataset gebruiken, een zeer beroemd classificatieprobleem in meerdere klassen. Deze dataset bestaat uit 4 functies (sepal lengte, sepal breedte, bloemblaadlengte, bloemblaadbreedte) en een doel (het type bloem). Deze gegevens hebben drie soorten bloemklassen: Setosa, Versicolour en Virginica. De dataset is beschikbaar in de scikit-learn bibliotheek, of u kunt het ook downloaden van de UCI Machine Learning bibliotheek.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetdataset
splitsen om de prestaties van het model te begrijpen, is het een goede strategie om de dataset op te delen in een trainingsset en een testset.
laten we de dataset splitsen met behulp van functie train_test_split (). je moet 3 parameters kenmerken passeren, doel, en test_set grootte.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testbouwen van het AdaBoost-Model
laten we het AdaBoost-Model maken met behulp van Scikit-learn. AdaBoost gebruikt Decision Tree Classifier als standaard Classifier.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“de belangrijkste parameters zijn base_estimator, n_estimators en learning_rate.”(Adaboost Classifier, Chris Albon)
- base_estimator: het is een zwakke leerling gebruikt om het model te trainen. Het maakt gebruik van DecisionTreeClassifier als default zwakke leerling voor trainingsdoeleinden. U kunt ook verschillende algoritmen voor machine learning opgeven.
- n_estimators: aantal zwakke lerenden dat iteratief moet opleiden.
- learning_rate: het draagt bij aan het gewicht van zwakke leerlingen. Het gebruikt 1 als standaardwaarde.
evalueer Model
laten we schatten hoe nauwkeurig de classificeerder of het model het type cultivars kan voorspellen.De nauwkeurigheid van
kan worden berekend door werkelijke testwaarden en voorspelde waarden te vergelijken.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888je hebt een nauwkeurigheid van 88,88%, beschouwd als een goede nauwkeurigheid.
voor verdere evaluatie kunt u ook een model maken met behulp van verschillende basis schatters.
gebruikmakend van verschillende Basisleerders
ik heb SVC gebruikt als basisschatting. U kunt Elke ml-leerling gebruiken als basis schatter als het monstergewicht accepteert, zoals beslissingsboom, ondersteuning Vector Classifier.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556nou, je hebt een classificatie van 95,55%, beschouwd als een goede nauwkeurigheid.
in dit geval krijgt SVC Base Estimator een betere nauwkeurigheid dan Decision tree Base Estimator.
Pros
AdaBoost is eenvoudig te implementeren. Het corrigeert iteratief de fouten van de zwakke classifier en verbetert de nauwkeurigheid door het combineren van zwakke leerlingen. U kunt veel Base classifiers gebruiken met AdaBoost. AdaBoost is niet gevoelig voor overbevissing. Dit kan worden ontdekt via de resultaten van experimenten, maar er is geen concrete reden beschikbaar.
Cons
AdaBoost is gevoelig voor ruisgegevens. Het wordt sterk beïnvloed door uitschieters omdat het probeert om elk punt perfect te passen. AdaBoost is trager in vergelijking met XGBoost.
conclusie
Gefeliciteerd, u bent aan het einde van deze tutorial gekomen!
in deze tutorial, heb je de Ensemble Machine Learning benaderingen, AdaBoost algoritme, het werkt, modelbouw en evaluatie met behulp van Python sikit-learn pakket geleerd. Ook besproken de voor-en nadelen.