에서 아다부스트 분류기 최근 몇 년 동안,부스팅 알고리즘은 데이터 과학이나 기계 학습 대회에서 엄청난 인기를 얻었다. 이 대회의 우승자 대부분은 높은 정확도를 달성하기 위해 부스팅 알고리즘을 사용합니다. 이러한 데이터 과학 대회는 다양한 비즈니스 및 정부 문제에 대한 솔루션을 학습,탐색 및 제공하기위한 글로벌 플랫폼을 제공합니다. 부스팅 알고리즘은 여러 개의 낮은 정확도(또는 약한)모델을 결합하여 높은 정확도(또는 강한)모델을 만듭니다. 신용,보험,마케팅 및 판매와 같은 다양한 영역에서 활용할 수 있습니다. 데이터 과학 대회에서 우승하기 위해 널리 사용되는 기계 학습 알고리즘입니다. 이 자습서에서는 애드부스트 앙상블 부스팅 알고리즘을 배우게 되며 다음 항목을 다룹니다:
- 앙상블 머신러닝 접근법
- 자루에 넣기
- 부스팅
- 스태킹
- 아다 부트 분류 자
- 아다 부트 알고리즘은 어떻게 작동합니까?
- 파이썬에서 모델 구축
- 장단점
- 결론
앙상블 기계 학습 접근
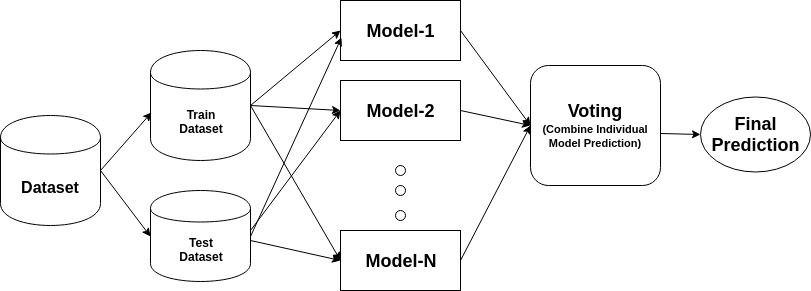
앙상블은 복합 모델이며,성능이 낮은 일련의 분류자를 결합하여 개선 된 분류자를 만듭니다. 여기서 과반수 투표를 수행하는 개별 분류 자 투표 및 최종 예측 레이블이 반환됩니다. 앙상블은 개인 또는 기본 분류기보다 더 많은 정확성을 제공합니다. 앙상블 메서드는 각 기본 학습자를 다른 시스템에 할당하여 병렬화 할 수 있습니다. 마지막으로 앙상블 학습 방법은 여러 기계 학습 방법을 단일 예측 모델로 결합하여 성능을 향상시키는 메타 알고리즘이라고 말할 수 있습니다. 앙상블 방법은 배깅 방식을 사용하여 분산을 줄이거 나 부스팅 방식을 사용하여 편향을 줄이거 나 스태킹 방식을 사용하여 예측을 향상시킬 수 있습니다.
-
자루에 넣기는 부트 스트랩 집계를 의미합니다. 그것은 추정의 분산을 줄일 수있는 방법으로 여러 학습자를 결합합니다. 예를 들어,임의의 포리스트 기차 미디엄 의사 결정 트리,데이터의 다른 임의의 하위 집합에서 미디엄 다른 트리를 훈련하고 최종 예측을 위해 투표를 수행 할 수 있습니다. 자루에 넣기 앙상블 방법은 임의의 숲과 여분의 나무입니다.
-
증폭 알고리즘은 매우 정확한 분류를 만들 수있는 낮은 정확한 분류의 집합입니다. 낮은 정확도 분류기(또는 약한 분류기)는 동전 뒤집기보다 정확도를 제공합니다. 매우 정확한 분류기(또는 강력한 분류기)는 0 에 가까운 오류율을 제공합니다. 부스팅 알고리즘은 정확한 예측에 실패한 모델을 추적 할 수 있습니다. 부스팅 알고리즘은 과적합 문제의 영향을 덜 받습니다. 다음 세 가지 알고리즘은 데이터 과학 대회에서 엄청난 인기를 얻었습니다.
- 아다부스트(적응형 부스팅)
- 그라디언트 트리 부스팅
-
스태킹(또는 스택 일반화)은 여러 기본 분류 모델 예측을 새 데이터 세트로 결합하는 앙상블 학습 기술입니다. 이 새 데이터는 다른 분류자에 대한 입력 데이터로 처리됩니다. 이 분류는이 문제를 해결하기 위해 사용. 겹쳐 쌓이는 것은 혼합으로 수시로 불립니다.
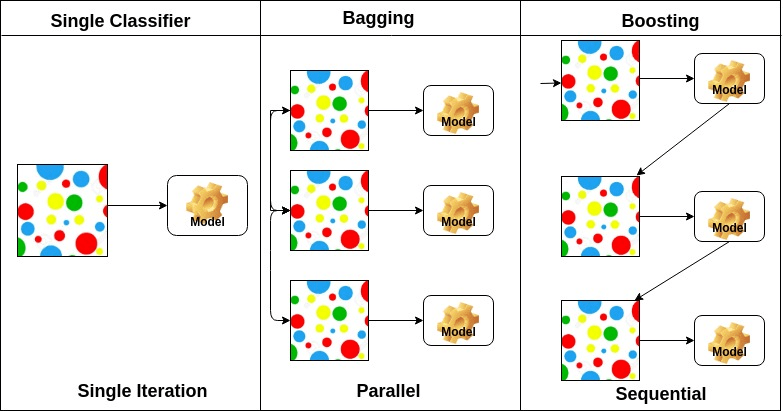
기본 학습자의 배열에 기초하여,앙상블 방법은 두 그룹으로 나눌 수있다:병렬 앙상블 방법,기본 학습자는 예를 들어 병렬로 생성됩니다. 랜덤 포레스트. 순차적 앙상블 메소드에서 기본 학습자는 예를 들어 순차적으로 생성됩니다.
기본 학습자의 유형에 따라 앙상블 방법을 두 그룹으로 나눌 수 있습니다: 동질 앙상블 방법은 각 반복에서 동일한 유형의 기본 학습자를 사용합니다. 이기종 앙상블 메서드는 각 반복에서 다른 유형의 기본 학습자를 사용합니다.
아다부스트 분류기
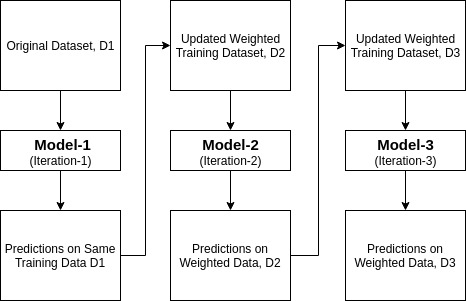
아다부스트 또는 어댑티브 부스팅은 1996 년 요아브 프로인트와 로버트 샤피어가 제안한 앙상블 부스팅 분류기 중 하나이다. 이 분류의 정확성을 높이기 위해 여러 분류를 결합합니다. 아다 부스트는 반복적 인 앙상블 방법입니다. 당신은 높은 정확도 강력한 분류를 얻을 수 있도록 여러 제대로 수행 분류기를 결합하여 강력한 분류를 구축합니다. 기본 개념은 분류자의 가중치를 설정하고 각 반복에서 데이터 샘플을 학습하여 비정상적인 관측치의 정확한 예측을 보장하는 것입니다. 모든 기계 학습 알고리즘은 훈련 세트에 가중치를 허용하는 경우 기본 분류 자로 사용할 수 있습니다. 아다부스트는 두 가지 조건을 충족해야 합니다:
- 분류자는 다양한 계량 훈련 예제에 대해 대화식으로 훈련해야합니다.
- 각 반복에서 훈련 오류를 최소화하여 이러한 예제에 대한 우수한 적합성을 제공하려고합니다.
아다부스트 알고리즘은 어떻게 작동합니까?
다음 단계에서 작동합니다:
- 처음에는 학습 하위 집합을 무작위로 선택합니다.
- 마지막 트레이닝의 정확한 예측을 기반으로 트레이닝 세트를 선택하여 애드부스트 머신 러닝 모델을 반복적으로 트레이닝합니다.
- 잘못된 분류 관측치에 더 높은 가중치를 할당하여 다음 반복에서 이러한 관측치가 분류에 대한 높은 확률을 얻을 수 있도록합니다.
- 또한,분류자의 정확도에 따라 각 반복에서 훈련된 분류자에 가중치를 할당한다. 더 정확한 분류기는 높은 무게를 얻을 것입니다.
- 이 프로세스는 완전한 학습 데이터가 오류없이 적합하거나 지정된 최대 추정자 수에 도달 할 때까지 반복됩니다.
- 분류하려면 작성한 모든 학습 알고리즘에 대해”투표”를 수행합니다.
파이썬에서 모델 작성
필요한 라이브러리 가져오기
먼저 필요한 라이브러리를 로드해 보겠습니다.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metrics로드 데이터 세트
모델 건물 부분에서,당신은 매우 유명한 멀티 클래스 분류 문제입니다 홍채 데이터 세트를 사용할 수 있습니다. 이 데이터 세트는 4 가지 기능(꽃받침 길이,꽃받침 너비,꽃잎 길이,꽃잎 너비)및 대상(꽃 유형)으로 구성됩니다. 이 데이터에는 세토사,베르 시코 루어 및 비르 지니 카의 세 가지 유형의 꽃 클래스가 있습니다. 데이터 집합은 컴퓨터 학습 라이브러리에서 사용할 수 있습니다.
# Load datairis = datasets.load_iris()X = iris.datay = iris.target데이터 집합 분할
모델 성능을 이해하려면 데이터 집합을 학습 집합과 테스트 집합으로 나누는 것이 좋은 전략입니다.
함수 기차 _테스트 _분할()을 사용하여 데이터 집합을 분할해 보겠습니다. 3 개의 매개 변수 기능,대상 및 테스트 세트 크기를 전달해야합니다.이 모델에서는 다음과 같은 기능을 사용할 수 있습니다. 의사 결정 트리 분류자를 기본 분류자로 사용합니다.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“가장 중요한 매개 변수는 다음과 같습니다.”(아다 부스트분류자,크리스 알본)
- 이 모델을 훈련하는 데 사용되는 약한 학습자이다. 그것은 훈련 목적을 위해 기본 약한 학습자로 의사 결정 분류기를 사용합니다. 다른 기계 학습 알고리즘을 지정할 수도 있습니다.
- 반복 훈련 할 약한 학습자 수.
- 학습률:약한 학습자의 가중치에 기여합니다. 기본값으로 1 을 사용합니다.
평가 모델
분류 자 또는 모델이 품종의 유형을 얼마나 정확하게 예측할 수 있는지 추정 해 봅시다.
정확도는 실제 테스트 세트 값과 예측 값을 비교하여 계산할 수 있습니다.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888글쎄,당신은 좋은 정확도로 간주 88.88%의 정확도를 얻었다.
추가 평가를 위해 다른 기본 추정기를 사용하여 모델을 만들 수도 있습니다.
다른 기본 학습자 사용
의사 결정 트리,지원 벡터 분류기와 같은 샘플 가중치를 허용하는 경우 모든 학습자를 기본 추정기로 사용할 수 있습니다.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556잘,당신은 좋은 정확도로 간주 95.55%의 분류 비율을 얻었다.
이 경우 의사 결정 트리 기본 추정치보다 정확도가 향상됩니다.
프로
아다 부스트는 구현하기 쉽습니다. 그것은 반복적으로 약한 분류기의 실수를 수정하고 약한 학습자를 결합하여 정확성을 향상시킵니다. 아다 부스트와 함께 많은 기본 분류자를 사용할 수 있습니다. 아다 부스트는 과적합하는 경향이 없습니다. 이것은 실험 결과를 통해 발견 될 수 있지만 구체적인 이유는 없습니다.
단점
아다부스트는 노이즈 데이터에 민감합니다. 각 점을 완벽하게 맞추려고 하기 때문에 이상값의 영향을 많이 받습니다. 이 문제를 해결하려면 다음을 수행하십시오.
결론
축하합니다,이 튜토리얼의 끝까지 만들었습니다!
이 튜토리얼에서,당신은 앙상블 기계 학습 방법을 배웠습니다,아다부스트 알고리즘,그것은 작동,파이썬 공상 과학 학습 패키지를 사용하여 모델 구축 및 평가. 또한 장단점에 대해 논의했습니다.