Ces dernières années, les algorithmes de stimulation ont gagné en popularité dans les compétitions de science des données ou d’apprentissage automatique. La plupart des gagnants de ces concours utilisent des algorithmes de stimulation pour atteindre une grande précision. Ces concours de science des données constituent la plate-forme mondiale pour apprendre, explorer et fournir des solutions à divers problèmes commerciaux et gouvernementaux. Les algorithmes d’amplification combinent plusieurs modèles de faible précision (ou faibles) pour créer des modèles de haute précision (ou forts). Il peut être utilisé dans divers domaines tels que le crédit, l’assurance, le marketing et les ventes. Les algorithmes d’amplification tels que AdaBoost, Gradient Boosting et XGBoost sont des algorithmes d’apprentissage automatique largement utilisés pour gagner les concours de science des données. Dans ce tutoriel, vous allez apprendre l’algorithme de renforcement d’ensemble AdaBoost, et les sujets suivants seront abordés:
- Approche d’apprentissage automatique d’ensemble
- Ensachage
- Amplification
- empilement
- Classificateur AdaBoost
- Comment fonctionne l’algorithme AdaBoost ?
- Modèle de construction en Python
- Avantages et inconvénients
- Conclusion
Approche d’apprentissage automatique d’ensemble
Un ensemble est un modèle composite, combine une série de classificateurs peu performants dans le but de créer un classificateur amélioré. Ici, le vote du classificateur individuel et l’étiquette de prédiction finale sont retournés qui effectue le vote à la majorité. Les ensembles offrent plus de précision que le classificateur individuel ou de base. Les méthodes d’ensemble peuvent se paralléliser en allouant chaque apprenant de base à des machines différentes – différentes. Enfin, vous pouvez dire que les méthodes d’apprentissage d’ensemble sont des méta-algorithmes qui combinent plusieurs méthodes d’apprentissage automatique en un seul modèle prédictif pour augmenter les performances. Les méthodes d’ensemble peuvent diminuer la variance à l’aide d’une approche d’ensachage, biaiser à l’aide d’une approche de renforcement ou améliorer les prédictions à l’aide d’une approche d’empilement.
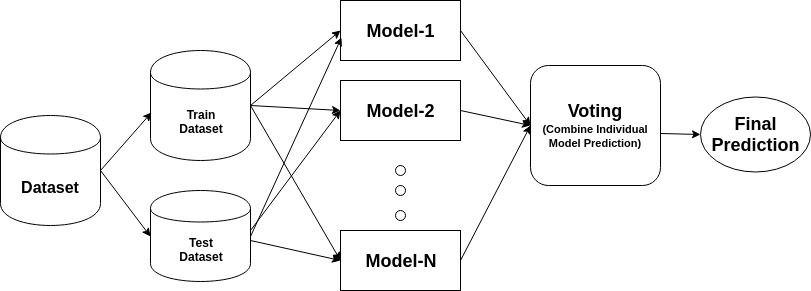
-
Ensachage signifie agrégation bootstrap. Il combine plusieurs apprenants de manière à réduire la variance des estimations. Par exemple, la forêt aléatoire entraîne M Arbre de décision, vous pouvez entraîner M arbres différents sur différents sous-ensembles aléatoires des données et effectuer un vote pour la prédiction finale. Les méthodes d’ensachage des ensembles sont des Forêts aléatoires et des arbres supplémentaires.
-
Les algorithmes d’amplification sont un ensemble du classificateur à faible précision pour créer un classificateur très précis. Classificateur de faible précision (ou classificateur faible) offre une précision meilleure que le retournement d’une pièce de monnaie. Un classificateur très précis (ou un classificateur puissant) offre un taux d’erreur proche de 0. L’algorithme de stimulation peut suivre le modèle qui a échoué à la prédiction précise. Les algorithmes de stimulation sont moins affectés par le problème de surajustement. Les trois algorithmes suivants ont acquis une popularité massive dans les compétitions de science des données.
- AdaBoost (Amplification adaptative)
- Amplification de l’arbre de gradient
- XGBoost
-
L’empilement (ou généralisation empilée) est une technique d’apprentissage par ensemble qui combine plusieurs prédictions de modèles de classification de base dans un nouvel ensemble de données. Ces nouvelles données sont traitées comme les données d’entrée d’un autre classificateur. Ce classificateur utilisé pour résoudre ce problème. L’empilement est souvent appelé mélange.
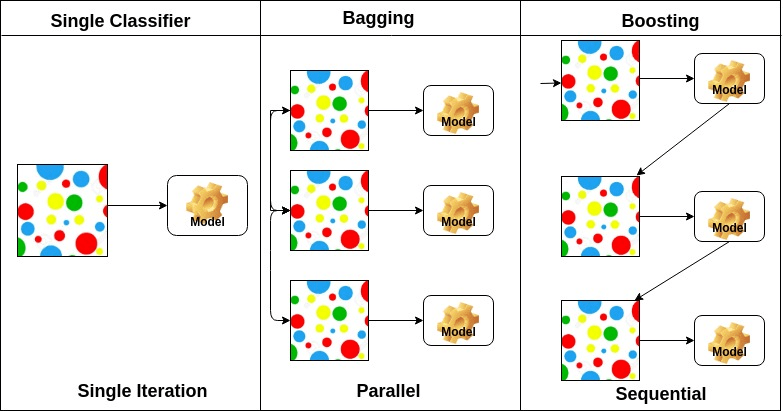
Sur la base de la disposition des apprenants de base, les méthodes d’ensemble peuvent être divisées en deux groupes: Dans les méthodes d’ensemble parallèles, les apprenants de base sont générés en parallèle par exemple. Forêt aléatoire. Dans les méthodes d’ensemble séquentiel, les apprenants de base sont générés séquentiellement par exemple AdaBoost.
Sur la base du type d’apprenants de base, les méthodes d’ensemble peuvent être divisées en deux groupes: la méthode d’ensemble homogène utilise le même type d’apprenant de base à chaque itération. la méthode d’ensemble hétérogène utilise le type différent d’apprenant de base à chaque itération.
Classificateur AdaBoost
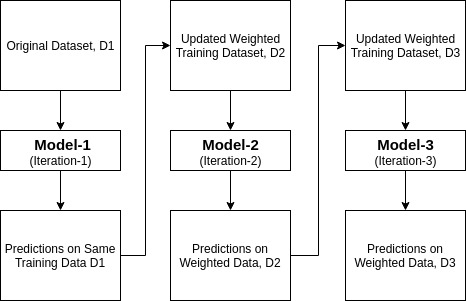
Ada-boost ou Amplification adaptative est l’un des classificateurs d’amplification d’ensemble proposés par Yoav Freund et Robert Schapire en 1996. Il combine plusieurs classificateurs pour augmenter la précision des classificateurs. AdaBoost est une méthode d’ensemble itérative. Le classificateur AdaBoost construit un classificateur puissant en combinant plusieurs classificateurs peu performants afin que vous obteniez un classificateur puissant de haute précision. Le concept de base d’Adaboost est de définir les poids des classificateurs et de former l’échantillon de données à chaque itération de manière à garantir des prédictions précises d’observations inhabituelles. Tout algorithme d’apprentissage automatique peut être utilisé comme classificateur de base s’il accepte des poids sur l’ensemble d’entraînement. Adaboost doit remplir deux conditions:
- Le classificateur doit être formé de manière interactive sur divers exemples de formation pondérée.
- À chaque itération, il essaie de fournir un excellent ajustement à ces exemples en minimisant les erreurs d’apprentissage.
Comment fonctionne l’algorithme AdaBoost ?
Il fonctionne dans les étapes suivantes:
- Dans un premier temps, Adaboost sélectionne aléatoirement un sous-ensemble d’entraînement.
- Il entraîne itérativement le modèle d’apprentissage automatique AdaBoost en sélectionnant l’ensemble d’entraînement en fonction de la prédiction précise de la dernière formation.
- Il attribue le poids le plus élevé aux observations mal classées de sorte que lors de l’itération suivante, ces observations obtiendront la probabilité élevée de classification.
- En outre, Il attribue le poids au classificateur entraîné à chaque itération en fonction de la précision du classificateur. Le classificateur plus précis aura un poids élevé.
- Ce processus itère jusqu’à ce que les données d’apprentissage complètes correspondent sans aucune erreur ou jusqu’à ce que le nombre maximal d’estimateurs spécifié soit atteint.
- Pour classer, effectuez un « vote » sur tous les algorithmes d’apprentissage que vous avez créés.
Modèle de construction en Python
Importation des bibliothèques requises
Chargeons d’abord les bibliothèques requises.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsChargement du jeu de données
Dans le modèle de la partie bâtiment, vous pouvez utiliser le jeu de données IRIS, qui est un problème de classification multi-classes très célèbre. Cet ensemble de données comprend 4 caractéristiques (longueur des sépales, largeur des sépales, longueur des pétales, largeur des pétales) et une cible (le type de fleur). Ces données ont trois types de classes de fleurs: Setosa, Versicolour et Virginica. L’ensemble de données est disponible dans la bibliothèque scikit-learn, ou vous pouvez également le télécharger à partir de la bibliothèque d’apprentissage automatique UCI.
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetDiviser l’ensemble de données
Pour comprendre les performances du modèle, diviser l’ensemble de données en un ensemble d’entraînement et un ensemble de tests est une bonne stratégie.
Divisons l’ensemble de données en utilisant la fonction train_test_split(). vous devez passer 3 caractéristiques de paramètres, target et test_set size.
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testConstruction du modèle AdaBoost
Créons le modèle AdaBoost en utilisant Scikit-learn. AdaBoost utilise le Classificateur d’arbre de décision comme Classificateur par défaut.
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)» Les paramètres les plus importants sont base_estimator, n_estimators et learning_rate. » (Classificateur Adaboost, Chris Albon)
- base_estimator: C’est un apprenant faible utilisé pour entraîner le modèle. Il utilise DecisionTreeClassifier comme apprenant faible par défaut à des fins de formation. Vous pouvez également spécifier différents algorithmes d’apprentissage automatique.
- n_estimateurs: Nombre d’apprenants faibles à former de manière itérative.
- taux d’apprentissage : Il contribue au poids des apprenants faibles. Il utilise 1 comme valeur par défaut.
Évaluez le modèle
Estimons avec quelle précision le classificateur ou le modèle peut prédire le type de cultivars.
La précision peut être calculée en comparant les valeurs réelles de l’ensemble de test et les valeurs prédites.
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888Eh bien, vous avez une précision de 88,88%, considérée comme une bonne précision.
Pour une évaluation plus approfondie, vous pouvez également créer un modèle en utilisant différents estimateurs de base.
En utilisant différents Apprenants de base
J’ai utilisé SVC comme estimateur de base. Vous pouvez utiliser n’importe quel apprenant ML comme estimateur de base s’il accepte le poids de l’échantillon tel que l’arbre de décision, le Classificateur de vecteurs de support.
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556Eh bien, vous avez un taux de classification de 95,55%, considéré comme une bonne précision.
Dans ce cas, l’estimateur de base SVC obtient une meilleure précision que l’estimateur de base de l’arbre de décision.
Avantages
AdaBoost est facile à mettre en œuvre. Il corrige de manière itérative les erreurs du classificateur faible et améliore la précision en combinant des apprenants faibles. Vous pouvez utiliser de nombreux classificateurs de base avec AdaBoost. AdaBoost n’est pas sujet au surajustement. Cela peut être découvert via les résultats d’expériences, mais il n’y a aucune raison concrète disponible.
Inconvénients
AdaBoost est sensible aux données de bruit. Il est fortement affecté par les valeurs aberrantes car il essaie de s’adapter parfaitement à chaque point. AdaBoost est plus lent que XGBoost.
Conclusion
Félicitations, vous êtes arrivé à la fin de ce tutoriel!
Dans ce tutoriel, vous avez appris les approches d’apprentissage automatique d’Ensemble, l’algorithme AdaBoost, son fonctionnement, la construction de modèles et l’évaluation à l’aide du package Python Scikit-learn. En outre, discuté de ses avantages et inconvénients.