近年、boostingアルゴリズムはデータサイエンスや機械学習の競技で大きな人気を博しました。 これらの大会の勝者のほとんどは、高精度を達成するためにブーストアルゴリズムを使用しています。 これらのデータサイエンス競技会は、様々なビジネスや政府の問題のための学習、探索、ソリューションを提供するためのグロー ブーストアルゴリズムは、複数の低精度(または弱)モデルを組み合わせて、高精度(または強)モデルを作成します。 それは信用、保険、マーケティングおよび販売のようなさまざまな範囲で利用することができる。 AdaBoost、Gradient Boosting、XGBoostなどのブーストアルゴリズムは、データサイエンス競技に勝つために広く使用されている機械学習アルゴリズムです。 このチュートリアルでは、AdaBoost ensemble boostingアルゴリズムを学習し、次のトピックについて説明します:
-
- AdaBoost分類子
- AdaBoostアルゴリズムはどのように機能しますか?
- Pythonでモデルを構築する
- 長所と短所
- 結論
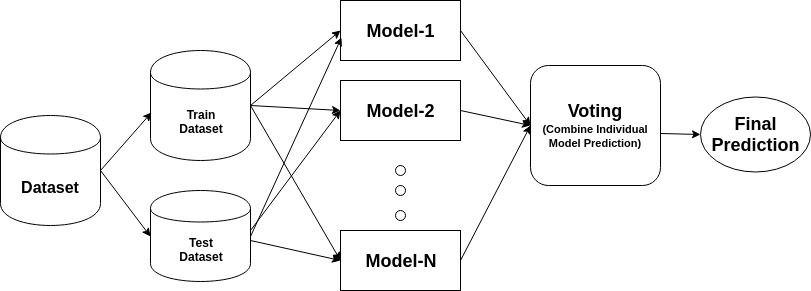
アンサンブル機械学習アプローチ
アンサンブルは複合モデルであり、改良された分類器を作成することを目的とした一連の低性能の分類器を組み合わせたものである。 ここでは、多数決を行う個々の分類器投票および最終予測ラベルが返される。 アンサンブルは、個々の分類器または基本分類器よりも高い精度を提供します。 アンサンブルメソッドは、各基本学習器を異なるマシンに割り当てることによって並列化できます。 最後に、アンサンブル学習法は、複数の機械学習法を単一の予測モデルに組み合わせてパフォーマンスを向上させるメタアルゴリズムであると言 アンサンブル法では、バギング法を使用して分散を減少させたり、ブースト法を使用してバイアスを下げたり、スタッキング法を使用して予測を改善したりすることができます。
-
Baggingはbootstrap aggregationの略です。 これは、推定値の分散を減らすための方法で複数の学習者を組み合わせます。 たとえば、random forest trains M Decision Treeでは、データの異なるランダムサブセット上でM個の異なるツリーをトレーニングし、最終予測の投票を実行できます。 バギングアンサンブルメソッドは、ランダムな森と余分な木です。
-
ブーストアルゴリズムは、高精度の分類器を作成するための低精度の分類器のセットです。 低精度分類器(または弱い分類器)は、コインの反転よりも精度が優れています。 非常に正確な分類器(または強力な分類器)は、0に近い誤り率を提供します。 ブーストアルゴリズムは、正確な予測に失敗したモデルを追跡することができます。 ブーストアルゴリズムは、過適合問題の影響を受けません。 以下の三つのアルゴリズムは、データサイエンス競技で大規模な人気を得ています。
- AdaBoost(アダプティブブースト)
- グラデーションツリーブースト
- XGBoost
-
積み重ね(または積み重ねられた一般化)は、複数の基本分類モデルの予測を新しいデータセットに結合するアンサンブル学習手法です。 この新しいデータは、別の分類器の入力データとして扱われます。 この分類器は、この問題を解決するために採用しました。 スタッキングは、しばしばブレンドと呼ばれます。
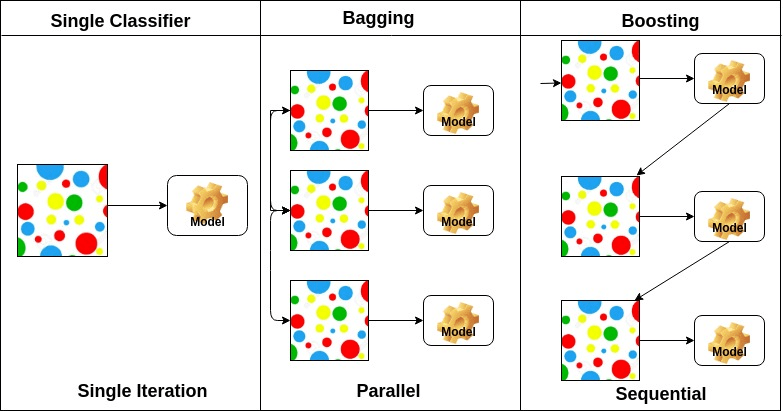
基本学習器の配置に基づいて,アンサンブル法は二つのグループに分けることができる。 ランダムな森。 シーケンシャルアンサンブル法では、基本学習器は、例えばAdaBoostのように順番に生成されます。
ベース学習器のタイプに基づいて、アンサンブル方法は二つのグループに分けることができます: 同種アンサンブル法では、各反復で同じタイプの基本学習器を使用します。 異種混合アンサンブル法では、反復ごとに異なるタイプの基本学習器を使用します。
AdaBoost Classifier
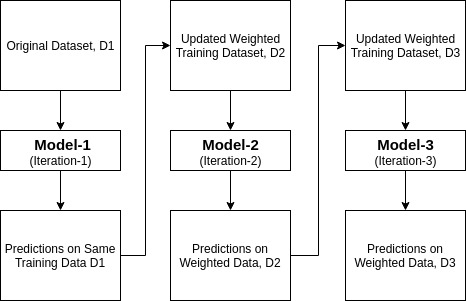
Ada-boostまたはAdaptive Boostingは、Yoav FreundとRobert Schapireによって1996年に提案されたensemble boosting classifierの一つである。 それは分類器の正確さを高めるために多数の分類器を結合します。 AdaBoostは反復アンサンブルメソッドです。 AdaBoost分類器は、高精度の強力な分類器を得るように、複数のパフォーマンスの低い分類器を組み合わせることによって強力な分類器を構築します。 Adaboostの背後にある基本的な概念は、分類器の重みを設定し、異常な観測値の正確な予測を確実にするように、各反復でデータサンプルを訓練することです。 任意の機械学習アルゴリズムは、学習セットの重みを受け入れる場合、基本分類子として使用できます。 Adaboostは二つの条件を満たす必要があります:
- 分類器は、さまざまな計量された訓練例で対話的に訓練されるべきである。
- 各反復では、学習誤差を最小限に抑えることによって、これらの例に優れた適合を提供しようとします。
AdaBoostアルゴリズムはどのように機能しますか?
次の手順で動作します:
- 最初に、Adaboostはトレーニングサブセットをランダムに選択します。
- 最後の訓練の正確な予測に基づいて訓練セットを選択することにより、AdaBoost機械学習モデルを反復的に訓練します。
- 間違った分類された観測値に高い重みを割り当て、次の反復でこれらの観測値が分類の高い確率を得るようにします。
- また、分類子の精度に応じて、各反復で学習された分類子に重みを割り当てます。 より正確な分類器は高い重量を得るでしょう。
- このプロセスは、完全な学習データがエラーなしで収まるまで、または指定された推定量の最大数に達するまで反復します。
- 分類するには、構築したすべての学習アルゴリズムにわたって”投票”を実行します。
Pythonでモデルを構築する
必要なライブラリをインポートする
最初に必要なライブラリをロードしましょう。
# Load librariesfrom sklearn.ensemble import AdaBoostClassifierfrom sklearn import datasets# Import train_test_split functionfrom sklearn.model_selection import train_test_split#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricsデータセットの読み込み
構築部分のモデルでは、非常に有名なマルチクラス分類問題であるIRISデータセットを使用できます。 このデータセットは、4つの特徴(萼片の長さ、萼片の幅、花弁の長さ、花弁の幅)とターゲット(花の種類)で構成されています。 このデータには、Setosa、Versicolour、Virginicaの三つのタイプの花のクラスがあります。 また、UCI Machine Learningライブラリからダウンロードすることもできます。
# Load datairis = datasets.load_iris()X = iris.datay = iris.targetデータセットの分割
モデルのパフォーマンスを理解するには、データセットをトレーニングセットとテストセットに分割するのが良い戦略です。
関数train_test_split()を使ってデータセットを分割しましょう。 features、target、およびtest_set sizeの3つのパラメータを渡す必要があります。
# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% testAdaBoostモデルの構築
Scikit-learnを使ってAdaBoostモデルを作成しましょう。 AdaBoostは、デフォルトの分類子として決定木分類子を使用します。
# Create adaboost classifer objectabc = AdaBoostClassifier(n_estimators=50, learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)“最も重要なパラメータは、base_estimator、n_estimators、およびlearning_rateです。”(アダブースト、クリス-アルボン)
- base_estimator:モデルを訓練するために使用される弱い学習器です。 これは、訓練目的のためのデフォルトの弱い学習者としてDecisionTreeClassifierを使用しています。 また、さまざまな機械学習アルゴリズムを指定することもできます。
- n_estimators:反復的に学習する弱い学習器の数。
- learning_rate:弱い学習者の重みに寄与します。 デフォルト値として1を使用します。
モデルを評価する
分類器またはモデルが品種の種類をどの程度正確に予測できるかを推定しましょう。
精度は、実際のテスト設定値と予測値を比較することによって計算することができます。
# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.8888888888888888まあ、あなたは88.88%の精度を得て、良い精度と考えられています。
さらに評価するために、異なるベース推定量を使用してモデルを作成することもできます。
異なるベース学習器を使用して
私はベース推定器としてSVCを使用しました。 決定木、サポートベクトル分類器などのサンプル重みを受け入れる場合は、任意のML学習器をベース推定器として使用できます。
# Load librariesfrom sklearn.ensemble import AdaBoostClassifier# Import Support Vector Classifierfrom sklearn.svm import SVC#Import scikit-learn metrics module for accuracy calculationfrom sklearn import metricssvc=SVC(probability=True, kernel='linear')# Create adaboost classifer objectabc =AdaBoostClassifier(n_estimators=50, base_estimator=svc,learning_rate=1)# Train Adaboost Classifermodel = abc.fit(X_train, y_train)#Predict the response for test datasety_pred = model.predict(X_test)# Model Accuracy, how often is the classifier correct?print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.9555555555555556まあ、あなたは95.55%の分類率を得て、良い精度と考えられています。
この場合、SVCベース推定器は、決定木ベース推定器よりも精度が向上しています。
Pros
AdaBoostは実装が簡単です。 弱い分類器の間違いを反復的に修正し、弱い学習器を組み合わせることによって精度を向上させます。 AdaBoostでは、多くの基本分類子を使用できます。 AdaBoostは過剰適合する傾向はありません。 これは実験結果から知ることができますが、利用可能な具体的な理由はありません。
Cons
AdaBoostはノイズデータに敏感です。 各点を完全に適合させようとするため、外れ値の影響を強く受けます。 AdaBoostはXGBoostと比較して遅いです。
結論
おめでとう、あなたはこのチュートリアルの最後にそれを作った!
このチュートリアルでは、Python Scikit-learnパッケージを使用して、アンサンブル機械学習のアプローチ、AdaBoostアルゴリズム、動作、モデル構築、評価を学びました。 また、その長所と短所を議論しました。